MeTA-LoRA: Data-Efficient Multi-Task Fine-Tuning for Large Language Models
作者: Bo Cheng, Xu Wang, Jinda Liu, Yi Chang, Yuan Wu
分类: cs.CL
发布日期: 2025-10-13
💡 一句话要点
MeTA-LoRA:一种数据高效的大语言模型多任务微调方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 参数高效微调 多任务学习 低秩适应 知识迁移 数据高效 大型语言模型 LoRA
📋 核心要点
- 现有LoRA方法在多任务学习中难以有效利用任务间知识,需要大量特定任务数据。
- MeTA-LoRA通过两阶段优化,先用少量数据学习任务特定适配器,再更新共享适配器促进知识迁移。
- 实验表明,MeTA-LoRA在多任务和多语言学习中,用更少数据达到或超过全数据LoRA的性能。
📝 摘要(中文)
低秩适应(LoRA)已成为一种广泛使用的参数高效微调(PEFT)方法,用于将大型语言模型(LLM)适应于下游任务。虽然在单任务设置中非常有效,但它难以在复杂的多任务学习场景中有效地利用任务间的知识,通常需要大量的特定任务数据才能达到最佳性能。为了解决这个限制,我们引入了MeTA-LoRA,一个两阶段优化框架,它显著提高了多任务适应中的数据效率。在第一阶段,使用来自每个相关数据集的少量样本学习特定于任务的LoRA适配器,从而无需大规模监督即可实现快速适应。在第二阶段,通过聚合来自多个任务的梯度来更新共享的LoRA适配器,以促进跨任务的知识转移,并通过利用常见模式进一步减少数据使用。在多任务学习和多语言学习场景中,我们的方法在显著减少特定任务数据使用的同时,匹配或超过了传统全数据LoRA微调方法的性能。
🔬 方法详解
问题定义:现有的大型语言模型微调方法,特别是LoRA,在多任务学习场景下,需要大量的特定任务数据才能达到理想的性能。这是因为LoRA在不同任务之间进行知识迁移的能力有限,每个任务都需要独立地进行微调,导致数据效率低下。
核心思路:MeTA-LoRA的核心思路是通过两阶段的优化策略,首先利用少量数据快速适应特定任务,然后在多个任务之间共享和迁移知识,从而提高数据效率。这种方法旨在利用不同任务之间的共性,减少对每个任务所需数据的依赖。
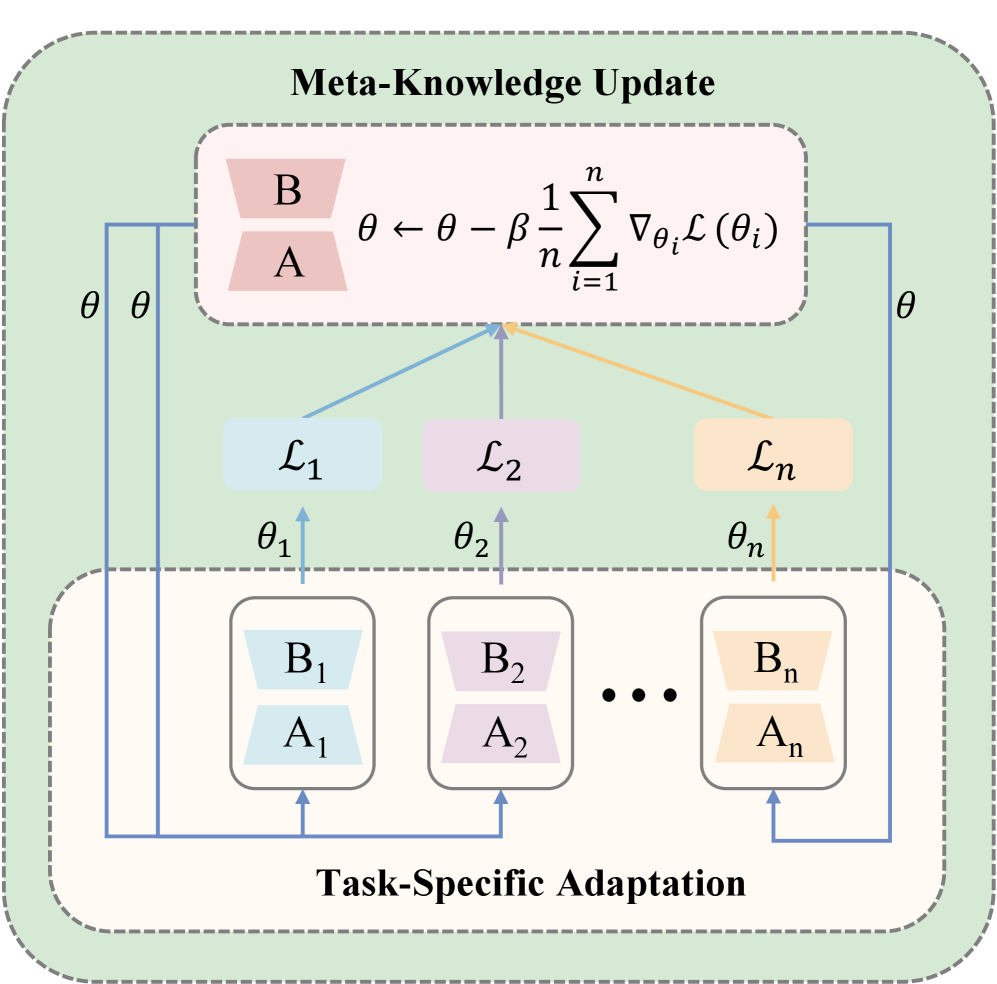
技术框架:MeTA-LoRA包含两个主要阶段: 1. 任务特定LoRA适配器学习:使用每个数据集中的少量样本,快速学习特定于任务的LoRA适配器。这一阶段旨在使模型能够快速适应每个任务的独特特征。 2. 共享LoRA适配器更新:通过聚合来自多个任务的梯度来更新共享的LoRA适配器。这一阶段旨在促进跨任务的知识转移,利用不同任务之间的共性,进一步减少数据使用。
关键创新:MeTA-LoRA的关键创新在于其两阶段优化框架,该框架能够有效地分离任务特定知识和共享知识的学习过程。与传统的LoRA方法相比,MeTA-LoRA能够更有效地利用少量数据进行多任务学习,并实现更好的泛化性能。
关键设计:MeTA-LoRA的关键设计包括: 1. 少量样本学习:在第一阶段,每个任务只使用少量样本进行训练,以减少数据需求。 2. 梯度聚合:在第二阶段,来自多个任务的梯度被聚合在一起,用于更新共享的LoRA适配器。具体的聚合方式可能包括简单的平均或者更复杂的加权平均。 3. 损失函数:损失函数通常是标准的交叉熵损失,用于衡量模型的预测结果与真实标签之间的差异。
🖼️ 关键图片

📊 实验亮点
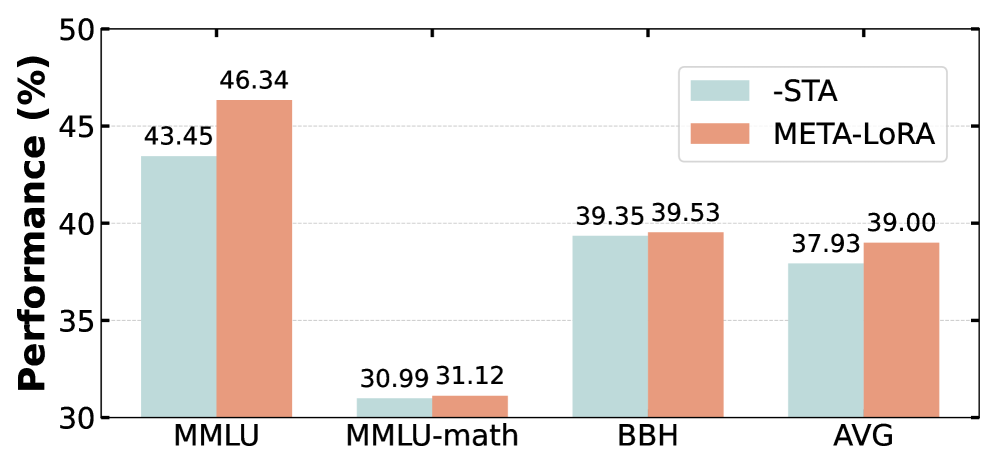
MeTA-LoRA在多任务学习和多语言学习场景中都取得了显著的性能提升。实验结果表明,MeTA-LoRA在使用远少于传统LoRA方法的数据量的情况下,能够达到甚至超过传统LoRA方法的性能。具体的性能提升幅度取决于具体的任务和数据集,但总体趋势是MeTA-LoRA能够显著提高数据效率。
🎯 应用场景
MeTA-LoRA适用于各种需要利用大型语言模型进行多任务学习的场景,例如自然语言处理中的文本分类、情感分析、机器翻译等。该方法可以显著降低数据标注成本,加速模型开发周期,并提高模型在资源受限场景下的性能。未来,MeTA-LoRA有望应用于更多领域,如医疗、金融等,助力构建更加智能和高效的AI系统。
📄 摘要(原文)
Low-Rank Adaptation (LoRA) has emerged as one of the most widely used parameter-efficient fine-tuning (PEFT) methods for adapting large language models (LLMs) to downstream tasks. While highly effective in single-task settings, it struggles to efficiently leverage inter-task knowledge in complex multi-task learning scenarios, often requiring substantial task-specific data to achieve optimal performance. To address this limitation, we introduce MeTA-LoRA, a two-stage optimization framework that significantly improves data efficiency in multi-task adaptation. In the first stage, task-specific LoRA adapters are learned using only a few samples from each involved dataset, enabling rapid adaptation without large-scale supervision. In the second stage, the shared LoRA adapter is updated by aggregating gradients from multiple tasks to promote knowledge transfer across tasks, further reducing data usage by leveraging common patterns. In both multi-task learning and multilingual learning scenarios, our method matches or surpasses the performance of traditional full-data LoRA fine-tuning approaches, while using significantly less task-specific data.