LLMAtKGE: Large Language Models as Explainable Attackers against Knowledge Graph Embeddings
作者: Ting Li, Yang Yang, Yipeng Yu, Liang Yao, Guoqing Chao, Ruifeng Xu
分类: cs.CL, cs.CR
发布日期: 2025-10-13
备注: 13 pages
💡 一句话要点
提出LLMAtKGE,利用大语言模型作为可解释的知识图谱嵌入对抗攻击器
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 知识图谱嵌入 对抗攻击 大型语言模型 可解释性 链接预测
📋 核心要点
- 现有KGE对抗攻击方法缺乏可解释性,且泛化能力不足,难以提供攻击背后的逻辑。
- LLMAtKGE利用大语言模型的推理能力,通过结构化提示和过滤机制,选择攻击目标并生成可解释的攻击理由。
- 实验表明,LLMAtKGE在攻击性能上优于现有黑盒方法,并能生成人类可读的解释,性能接近白盒方法。
📝 摘要(中文)
知识图谱嵌入(KGE)的对抗攻击旨在通过移除或插入三元组来破坏模型进行链接预测的能力。最近的一种黑盒方法试图结合文本和结构信息来提高攻击性能,但它无法生成人类可读的解释,并且泛化能力较差。近年来,大型语言模型(LLM)在文本理解、生成和推理方面表现出强大的能力。本文提出了一种基于LLM的新框架LLMAtKGE,该框架选择攻击目标并生成人类可读的解释。为了在有限的输入约束下为LLM提供足够的实际上下文,我们设计了一种结构化的提示方案,该方案将攻击明确地表述为多项选择题,同时结合了KG事实证据。为了解决上下文窗口限制和犹豫问题,我们引入了基于语义和基于中心性的过滤器,这些过滤器压缩了候选集,同时保持了攻击相关信息的高召回率。此外,为了有效地将语义和结构信息集成到过滤器中,我们预先计算高阶邻接矩阵,并使用三元组分类任务对LLM进行微调,以提高过滤性能。在两个广泛使用的知识图谱数据集上的实验表明,我们的攻击优于最强的黑盒基线,并通过推理提供了解释,并且与白盒方法相比表现出竞争优势。全面的消融和案例研究进一步验证了其生成解释的能力。
🔬 方法详解
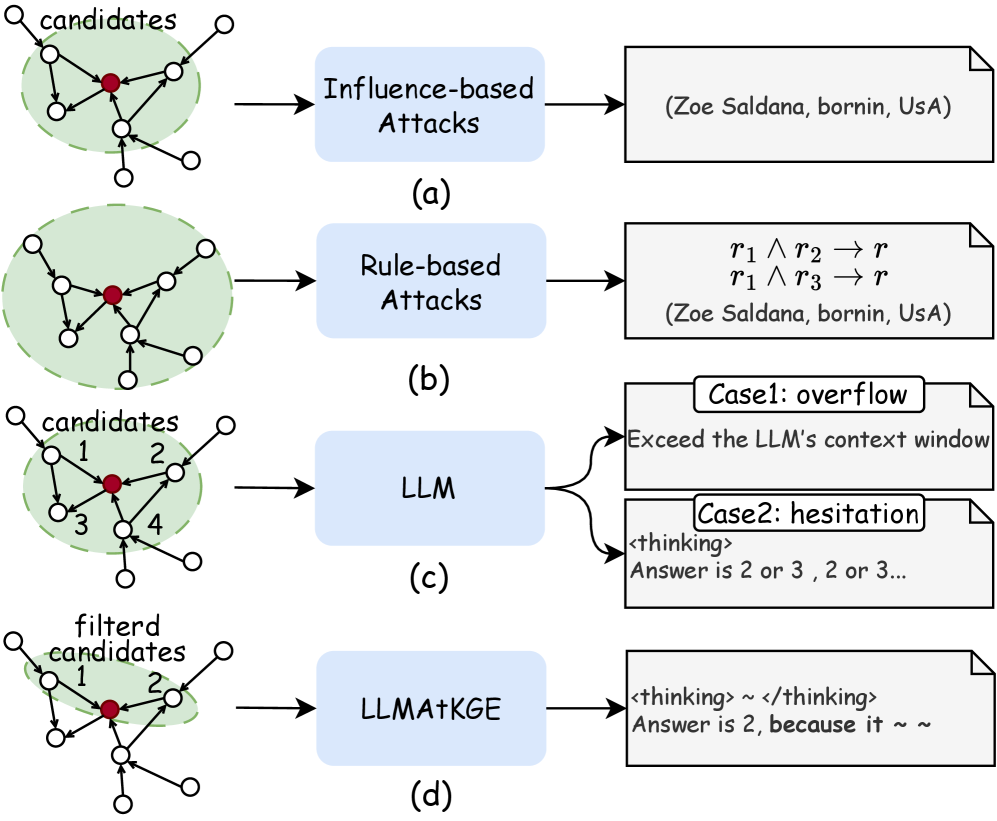
问题定义:论文旨在解决现有知识图谱嵌入(KGE)对抗攻击方法缺乏可解释性和泛化能力的问题。现有的黑盒攻击方法虽然尝试结合文本和结构信息,但无法生成人类可读的解释,难以理解攻击的原因和方式,并且在不同数据集上的表现不稳定。
核心思路:论文的核心思路是利用大型语言模型(LLM)强大的文本理解、生成和推理能力,将对抗攻击过程转化为一个可解释的推理过程。通过设计合适的提示(prompt),引导LLM选择合适的攻击目标,并生成攻击的解释。
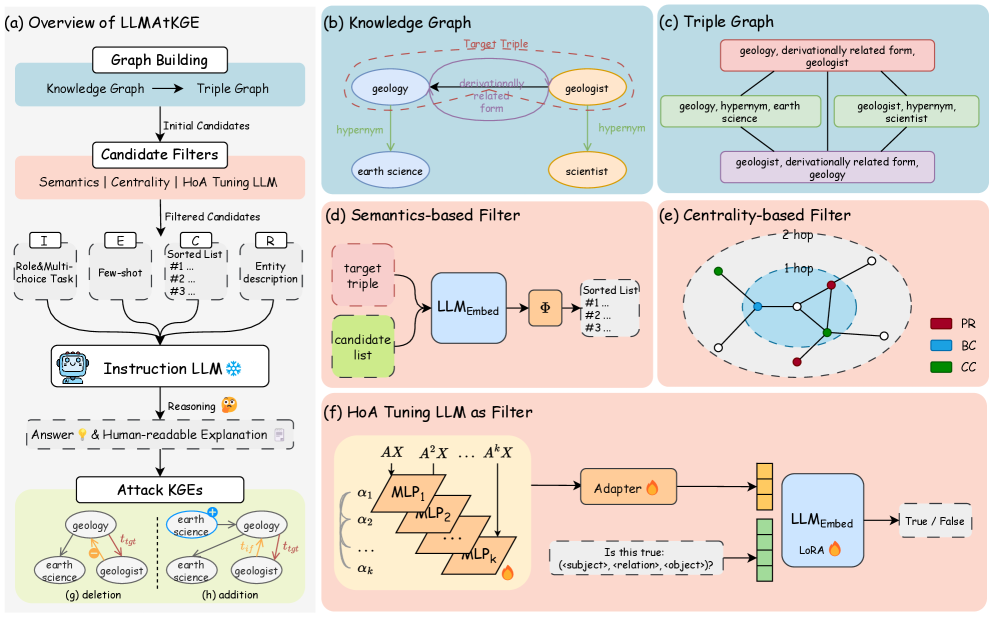
技术框架:LLMAtKGE框架主要包含以下几个模块:1) 结构化提示模块:将攻击任务转化为多项选择题,并结合知识图谱的事实信息,为LLM提供上下文。2) 过滤模块:包括基于语义的过滤器和基于中心性的过滤器,用于压缩候选攻击目标集合,缓解LLM的上下文窗口限制。3) LLM微调模块:使用三元组分类任务对LLM进行微调,提高其过滤性能。
关键创新:论文的关键创新在于:1) 将LLM引入KGE对抗攻击领域,利用其推理能力生成可解释的攻击。2) 设计了结构化的提示方案,有效地利用了LLM的上下文窗口。3) 提出了基于语义和中心性的过滤机制,提高了攻击效率和召回率。
关键设计:1) 结构化提示:将攻击目标选择转化为多项选择题,选项包括正确的三元组和多个候选的错误三元组。提示中包含目标三元组的上下文信息,例如实体和关系的描述。2) 过滤机制:基于语义的过滤器利用预训练的词向量计算实体和关系的语义相似度,过滤掉语义上不相关的三元组。基于中心性的过滤器利用知识图谱的结构信息,选择中心性较高的实体和关系作为攻击目标。3) LLM微调:使用三元组分类任务对LLM进行微调,提高其判断三元组真伪的能力。损失函数采用交叉熵损失。
🖼️ 关键图片

📊 实验亮点
实验结果表明,LLMAtKGE在两个广泛使用的知识图谱数据集上,攻击性能优于最强的黑盒基线,并且能够生成人类可读的解释。与白盒方法相比,LLMAtKGE也表现出具有竞争力的性能。消融实验验证了各个模块的有效性,案例研究展示了LLM生成解释的能力。
🎯 应用场景
该研究成果可应用于提升知识图谱嵌入模型的鲁棒性和安全性,例如在推荐系统、问答系统等应用中,防御恶意攻击,提高系统的可靠性。此外,该方法提供的可解释性攻击,有助于理解模型的弱点,从而有针对性地进行改进和优化。
📄 摘要(原文)
Adversarial attacks on knowledge graph embeddings (KGE) aim to disrupt the model's ability of link prediction by removing or inserting triples. A recent black-box method has attempted to incorporate textual and structural information to enhance attack performance. However, it is unable to generate human-readable explanations, and exhibits poor generalizability. In the past few years, large language models (LLMs) have demonstrated powerful capabilities in text comprehension, generation, and reasoning. In this paper, we propose LLMAtKGE, a novel LLM-based framework that selects attack targets and generates human-readable explanations. To provide the LLM with sufficient factual context under limited input constraints, we design a structured prompting scheme that explicitly formulates the attack as multiple-choice questions while incorporating KG factual evidence. To address the context-window limitation and hesitation issues, we introduce semantics-based and centrality-based filters, which compress the candidate set while preserving high recall of attack-relevant information. Furthermore, to efficiently integrate both semantic and structural information into the filter, we precompute high-order adjacency and fine-tune the LLM with a triple classification task to enhance filtering performance. Experiments on two widely used knowledge graph datasets demonstrate that our attack outperforms the strongest black-box baselines and provides explanations via reasoning, and showing competitive performance compared with white-box methods. Comprehensive ablation and case studies further validate its capability to generate explanations.