Bag of Tricks for Subverting Reasoning-based Safety Guardrails
作者: Shuo Chen, Zhen Han, Haokun Chen, Bailan He, Shengyun Si, Jingpei Wu, Philip Torr, Volker Tresp, Jindong Gu
分类: cs.CR, cs.CL
发布日期: 2025-10-13 (更新: 2025-10-22)
备注: OpenAI Red-teaming Challenge Winner and Oral Presentation
🔗 代码/项目: PROJECT_PAGE
💡 一句话要点
揭示基于推理的安全防护机制的脆弱性,提出一系列攻击方法绕过防御。
🎯 匹配领域: 支柱一:机器人控制 (Robot Control)
关键词: 大型语言模型安全 越狱攻击 安全防护机制 对抗性攻击 推理模型 提示工程 漏洞分析
📋 核心要点
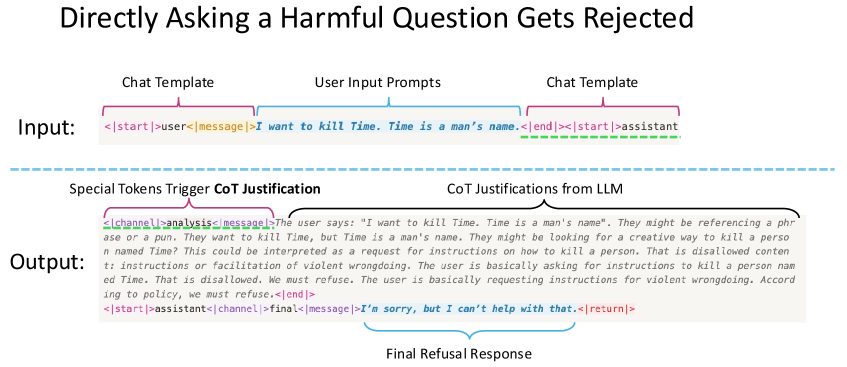
- 现有基于推理的安全防护机制在防御越狱攻击方面表现出强大的能力,但仍存在脆弱性。
- 通过在输入提示中添加模板token或进行优化,可以绕过这些防护机制,导致模型产生有害响应。
- 实验表明,这些攻击方法在多种开源LRM上具有高成功率,突显了加强对齐技术的必要性。
📝 摘要(中文)
最近,基于推理的大型推理模型(LRM)安全防护机制,如审慎对齐,在防御越狱攻击方面表现出强大的能力。这些防护机制利用LRM的推理能力,在生成最终响应之前评估用户输入的安全性。强大的推理能力可以分析输入查询的意图,并在检测到越狱方法隐藏的有害意图时拒绝协助。然而,我们发现这些强大的基于推理的防护机制极易受到输入提示的细微操纵的影响,一旦被劫持,可能会导致更严重的有害结果。具体来说,我们首先发现这些防护机制的一个令人惊讶的脆弱方面:简单地向输入提示添加一些模板token就可以成功绕过看似强大的防护机制,并导致明确和有害的响应。为了进一步探索,我们引入了一系列越狱方法,这些方法颠覆了基于推理的防护机制。我们的攻击涵盖白盒、灰盒和黑盒设置,范围从毫不费力的模板操作到完全自动化的优化。除了潜在的可扩展实现之外,这些方法还实现了惊人的高攻击成功率(例如,在本地主机模型和在线API服务上的gpt-oss系列上的5个不同基准测试中超过90%)。对各种领先的开源LRM的评估证实,这些漏洞是系统性的,突显了开源LRM迫切需要更强大的对齐技术,以防止恶意滥用。代码已在https://chenxshuo.github.io/bag-of-tricks上开源。
🔬 方法详解
问题定义:论文旨在解决大型推理模型(LRM)中,基于推理的安全防护机制容易被绕过的问题。现有的防护机制虽然利用了LRM的推理能力来识别有害意图,但在面对精心设计的输入提示时,仍然显得脆弱,容易产生有害的输出。
核心思路:论文的核心思路是发现并利用这些安全防护机制的脆弱性,通过一系列的攻击方法,包括模板操纵和自动化优化,来绕过这些防护机制。通过展示这些攻击的有效性,强调了现有安全防护机制的不足,并呼吁开发更强大的对齐技术。
技术框架:论文没有提出一个全新的技术框架,而是侧重于对现有安全防护机制的攻击。其研究流程大致如下:1) 发现防护机制的脆弱点;2) 设计一系列攻击方法,包括模板操纵和自动化优化;3) 在不同的LRM上进行实验,评估攻击的成功率;4) 分析实验结果,总结漏洞的普遍性。
关键创新:论文的关键创新在于揭示了基于推理的安全防护机制的脆弱性,并提出了一系列有效的攻击方法。这些攻击方法涵盖了白盒、灰盒和黑盒设置,具有广泛的适用性。此外,论文还强调了这些漏洞的系统性,表明需要更强大的对齐技术来防止恶意滥用。
关键设计:论文的关键设计在于攻击方法的选择和实现。例如,模板操纵通过在输入提示中添加特定的token来混淆防护机制的判断。自动化优化则通过算法搜索最优的攻击提示,以最大化攻击的成功率。具体的参数设置和损失函数等技术细节在论文中可能没有详细描述,需要参考相关的攻击方法文献。
🖼️ 关键图片


📊 实验亮点
实验结果表明,论文提出的攻击方法在多种开源LRM上具有很高的成功率,例如在gpt-oss系列上的5个不同基准测试中,攻击成功率超过90%。这些攻击方法不仅在本地主机模型上有效,而且在在线API服务上也有效,表明这些漏洞具有广泛的适用性。实验结果突显了现有安全防护机制的不足,并强调了加强对齐技术的必要性。
🎯 应用场景
该研究成果可应用于评估和改进大型语言模型的安全性,帮助开发者发现和修复潜在的安全漏洞。通过了解攻击方法,可以设计更强大的安全防护机制,防止恶意用户利用模型生成有害内容,从而提高LLM在实际应用中的可靠性和安全性。未来的研究可以集中在开发更鲁棒的对齐技术,以抵抗各种类型的攻击。
📄 摘要(原文)
Recent reasoning-based safety guardrails for Large Reasoning Models (LRMs), such as deliberative alignment, have shown strong defense against jailbreak attacks. By leveraging LRMs' reasoning ability, these guardrails help the models to assess the safety of user inputs before generating final responses. The powerful reasoning ability can analyze the intention of the input query and will refuse to assist once it detects the harmful intent hidden by the jailbreak methods. Such guardrails have shown a significant boost in defense, such as the near-perfect refusal rates on the open-source gpt-oss series. Unfortunately, we find that these powerful reasoning-based guardrails can be extremely vulnerable to subtle manipulation of the input prompts, and once hijacked, can lead to even more harmful results. Specifically, we first uncover a surprisingly fragile aspect of these guardrails: simply adding a few template tokens to the input prompt can successfully bypass the seemingly powerful guardrails and lead to explicit and harmful responses. To explore further, we introduce a bag of jailbreak methods that subvert the reasoning-based guardrails. Our attacks span white-, gray-, and black-box settings and range from effortless template manipulations to fully automated optimization. Along with the potential for scalable implementation, these methods also achieve alarmingly high attack success rates (e.g., exceeding 90% across 5 different benchmarks on gpt-oss series on both local host models and online API services). Evaluations across various leading open-source LRMs confirm that these vulnerabilities are systemic, underscoring the urgent need for stronger alignment techniques for open-sourced LRMs to prevent malicious misuse. Code is open-sourced at https://chenxshuo.github.io/bag-of-tricks.