Invisible Languages of the LLM Universe
作者: Saurabh Khanna, Xinxu Li
分类: cs.CL
发布日期: 2025-10-13 (更新: 2025-12-30)
💡 一句话要点
揭示LLM中语言不平等现象,强调数字鸿沟与殖民时代语言等级制度的延续性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语言不平等 大型语言模型 数字鸿沟 后殖民理论 认知不公正 语言活力 数字化程度
📋 核心要点
- 大型语言模型训练数据存在偏差,导致大量语言在数字世界中“隐形”,造成语言不平等。
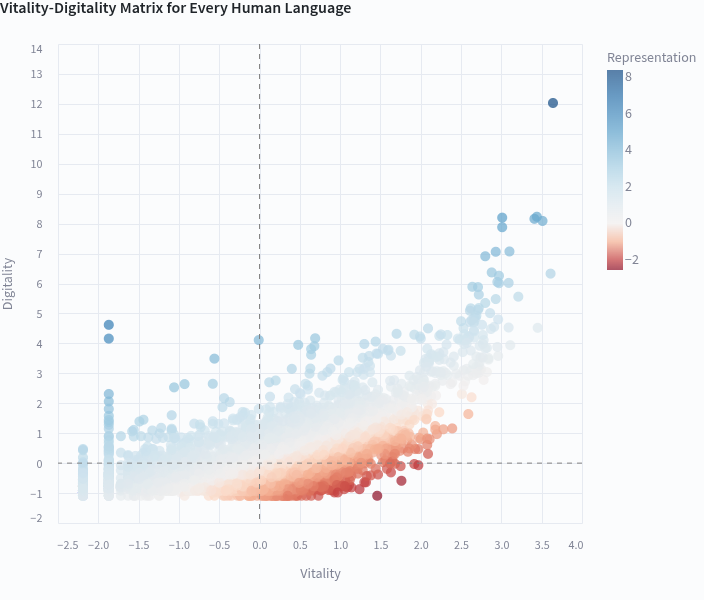
- 该研究通过分析语言活力和数字化程度,将语言划分为四个类别,揭示了语言在数字世界的分布不均。
- 研究表明,语言不平等并非技术问题,而是权力结构在AI领域的延续,呼吁语言技术去殖民化。
📝 摘要(中文)
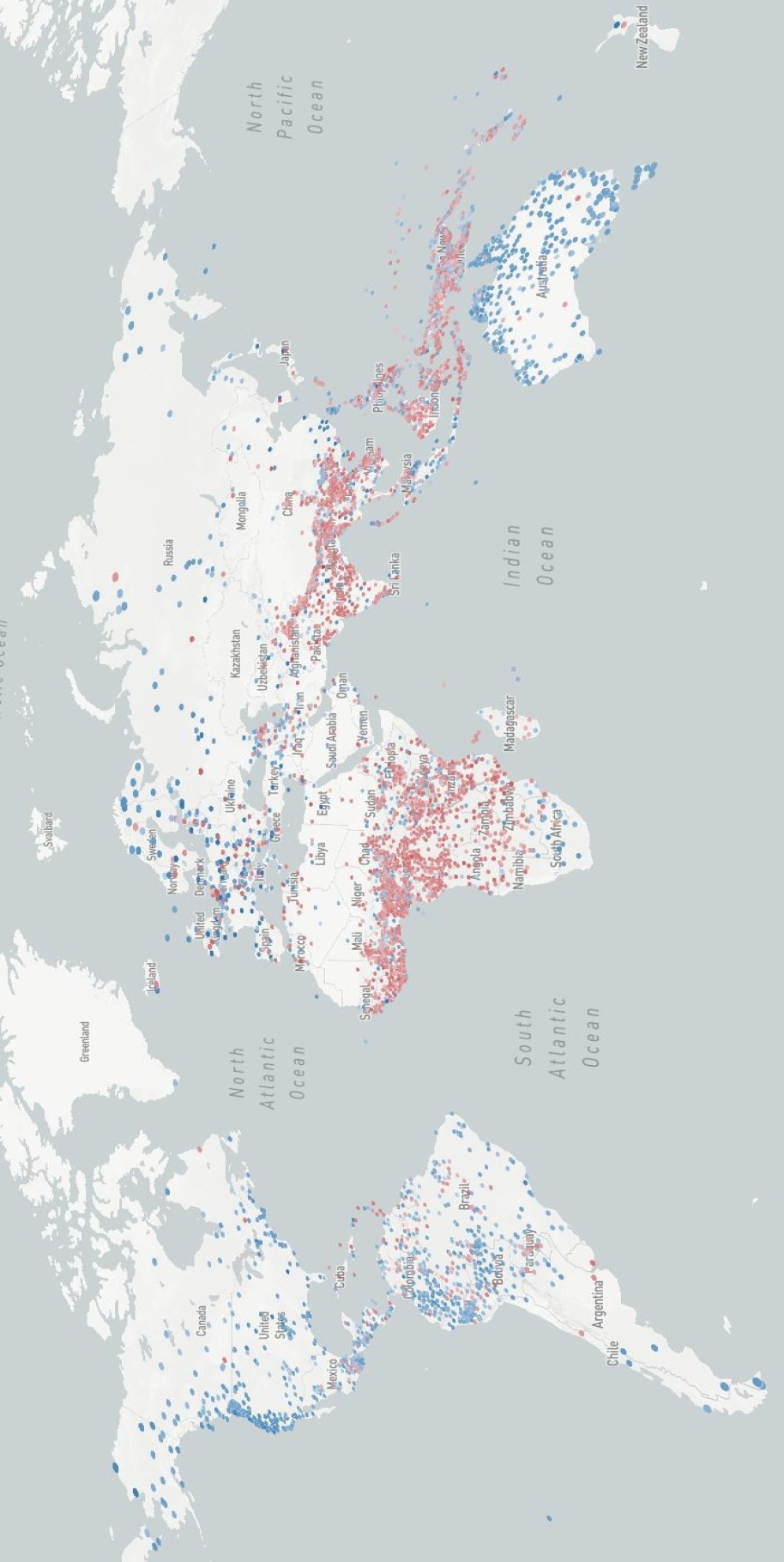
大型语言模型(LLM)在海量多语种语料库上训练,但这种丰富性掩盖了一个深刻的危机:在世界现存的7613种语言中,约有2000种语言(拥有数百万使用者)在数字生态系统中实际上是不可见的。本文提出了一个关键框架,将语言活力(现实世界的人口统计学实力)和数字化程度(在线存在)的经验测量与后殖民理论和认知不公正联系起来,以解释为什么AI系统中的语言不平等不是偶然的,而是结构性的。通过分析所有有记录的人类语言的数据,我们确定了四个类别:据点(33%,高活力和数字化程度),数字回声(6%,尽管活力下降但数字化程度高),衰落的声音(36%,在两个维度上都很低),以及关键的,隐形巨人(27%,高活力但接近零的数字化程度)——数百万人在使用但LLM宇宙中不存在的语言。我们证明这些模式反映了从殖民时代语言等级制度到当代AI发展的延续性,构成了数字认知不公正。我们的分析表明,英语在AI中的主导地位不是技术上的必然,而是系统性地排除边缘化语言知识的权力结构的产物。最后,我们总结了去殖民化语言技术和民主化AI访问的意义。
🔬 方法详解
问题定义:现有的大型语言模型训练数据集存在严重的语言偏差,导致许多语言在数字世界中缺乏代表性,使得使用这些语言的人群无法平等地享受AI技术带来的便利。现有方法未能充分解决这一问题,因为它们往往侧重于优化模型性能,而忽视了数据集中存在的结构性不平等。
核心思路:该研究的核心思路是将语言的“活力”(即现实世界的使用人数)和“数字化程度”(即在线存在感)结合起来,构建一个评估语言在数字世界中可见性的框架。通过这个框架,可以识别出那些在现实世界中拥有大量使用者,但在数字世界中几乎不可见的“隐形巨人”语言,从而揭示语言不平等的本质。
技术框架:该研究的技术框架主要包括以下几个步骤:1) 收集所有已记录的人类语言的数据,包括语言活力(例如,使用人数)和数字化程度(例如,在线内容量)。2) 基于这些数据,将语言划分为四个类别:据点、数字回声、衰落的声音和隐形巨人。3) 分析这四个类别之间的差异,并将其与后殖民理论和认知不公正联系起来,以解释语言不平等的根源。4) 提出去殖民化语言技术和民主化AI访问的建议。
关键创新:该研究的关键创新在于提出了一个将语言活力和数字化程度相结合的评估框架,并将其与后殖民理论和认知不公正联系起来。这种跨学科的分析方法能够更深入地理解语言不平等的本质,并为解决这一问题提供新的思路。
关键设计:该研究的关键设计包括:1) 使用了全面的语言数据,涵盖了所有已记录的人类语言。2) 定义了清晰的语言活力和数字化程度的指标。3) 采用了四分类的语言划分方法,能够更清晰地呈现语言在数字世界的分布情况。4) 结合了后殖民理论和认知不公正的视角,能够更深入地理解语言不平等的根源。
🖼️ 关键图片

📊 实验亮点
研究发现,27%的语言属于“隐形巨人”类别,这些语言拥有大量使用者,但在数字世界中几乎不可见。这表明,LLM的训练数据存在严重的偏差,导致大量人口无法平等地享受AI技术带来的便利。该研究强调了英语在AI中的主导地位并非技术上的必然,而是权力结构在AI领域的延续。
🎯 应用场景
该研究成果可应用于指导语言资源的建设,优先支持“隐形巨人”语言的数字化,提升LLM对这些语言的支持能力。同时,该研究也为AI伦理研究提供了新的视角,有助于推动AI技术的公平性和包容性,避免加剧社会不平等。
📄 摘要(原文)
Large Language Models are trained on massive multilingual corpora, yet this abundance masks a profound crisis: of the world's 7,613 living languages, approximately 2,000 languages with millions of speakers remain effectively invisible in digital ecosystems. We propose a critical framework connecting empirical measurements of language vitality (real world demographic strength) and digitality (online presence) with postcolonial theory and epistemic injustice to explain why linguistic inequality in AI systems is not incidental but structural. Analyzing data across all documented human languages, we identify four categories: Strongholds (33%, high vitality and digitality), Digital Echoes (6%, high digitality despite declining vitality), Fading Voices (36%, low on both dimensions), and critically, Invisible Giants (27%, high vitality but near-zero digitality) - languages spoken by millions yet absent from the LLM universe. We demonstrate that these patterns reflect continuities from colonial-era linguistic hierarchies to contemporary AI development, constituting digital epistemic injustice. Our analysis reveals that English dominance in AI is not a technical necessity but an artifact of power structures that systematically exclude marginalized linguistic knowledge. We conclude with implications for decolonizing language technology and democratizing access to AI benefits.