Hallucination Detection via Internal States and Structured Reasoning Consistency in Large Language Models
作者: Yusheng Song, Lirong Qiu, Xi Zhang, Zhihao Tang
分类: cs.CL
发布日期: 2025-10-13 (更新: 2026-01-08)
🔗 代码/项目: GITHUB
💡 一句话要点
提出HalluDet框架,通过内部状态和结构化推理一致性检测大语言模型幻觉
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 幻觉检测 内部状态探测 思维链验证 多路径推理 交叉注意力 一致性学习
📋 核心要点
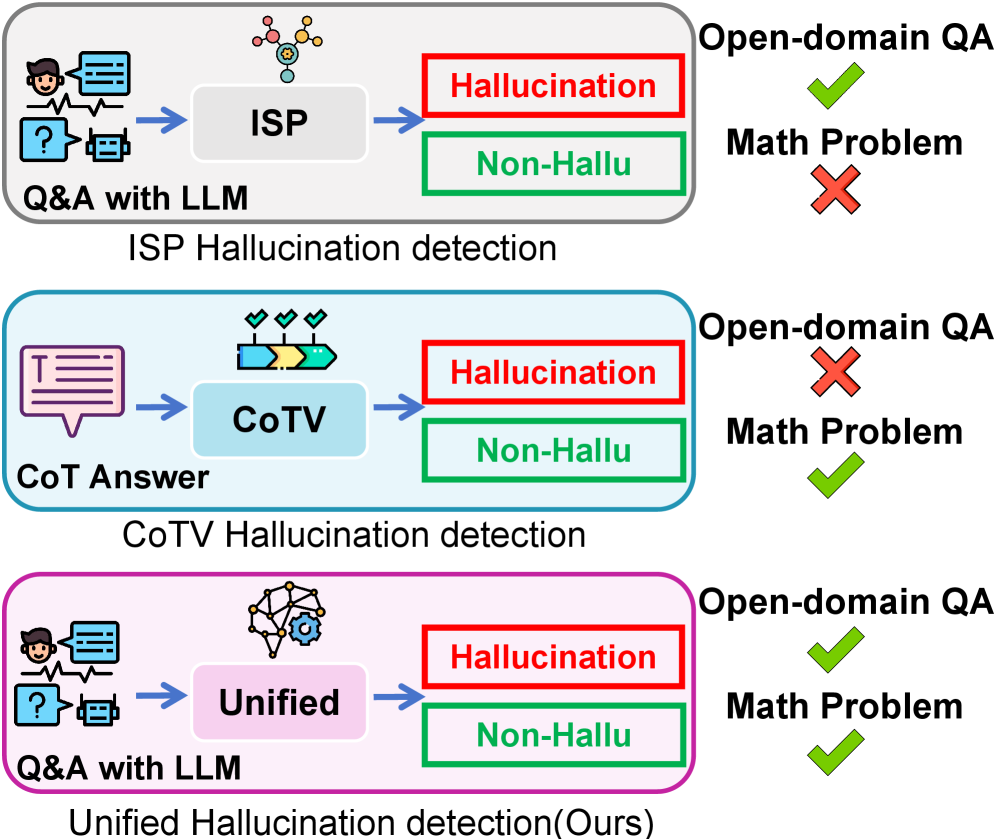
- 现有幻觉检测方法存在“检测困境”,内部状态探测和思维链验证分别擅长事实和逻辑错误,但各有盲区。
- 提出HalluDet框架,通过多路径推理获取细粒度信号,并使用分段感知的时间化交叉注意力模块对齐表征。
- 实验表明,HalluDet在多个基准测试和LLM上显著优于现有基线,有效提升了幻觉检测的准确性。
📝 摘要(中文)
大语言模型(LLM)中复杂幻觉的检测面临“检测困境”:探测内部状态的方法(内部状态探测)擅长识别事实不一致,但在逻辑谬误上表现不佳,而验证外部化推理的方法(思维链验证)则表现出相反的行为。这种分裂造成了任务依赖的盲点:思维链验证在开放域问答等事实密集型任务上失败,因为推理没有依据;而内部状态探测在数学推理等逻辑密集型任务上无效,因为模型自信地犯错。我们提出了一个统一的框架来弥合这一关键差距。然而,统一受到两个基本挑战的阻碍:信号稀缺性障碍,因为粗略的符号推理链缺乏与细粒度内部状态直接可比的信号;以及表征对齐障碍,即它们底层语义空间之间根深蒂固的不匹配。为了克服这些障碍,我们引入了一种多路径推理机制来获得更具可比性的细粒度信号,以及一个分段感知的时间化交叉注意力模块,以自适应地融合这些现在对齐的表示,从而精确定位细微的不和谐。在三个不同的基准和两个领先的LLM上的大量实验表明,我们的框架始终且显著地优于强大的基线。我们的代码可在https://github.com/peach918/HalluDet 获取。
🔬 方法详解
问题定义:现有的大语言模型幻觉检测方法存在局限性。内部状态探测方法擅长检测事实性错误,但难以发现逻辑推理错误;而思维链验证方法则相反。这种差异导致在不同类型的任务上,幻觉检测的性能表现不佳,例如,在开放域问答和数学推理任务上分别失效。因此,需要一种统一的框架,能够同时有效地检测事实性和逻辑性幻觉。
核心思路:论文的核心思路是通过融合内部状态探测和思维链验证的优点,弥补各自的不足。具体而言,通过引入多路径推理机制,生成更细粒度的推理信号,使其与内部状态更具可比性。同时,利用分段感知的时间化交叉注意力模块,对齐内部状态和推理链的表征,从而能够更准确地检测出两者之间的不一致性,进而识别幻觉。
技术框架:HalluDet框架主要包含以下几个模块:1) 多路径推理模块:生成多个推理路径,提供更丰富的推理信息。2) 内部状态提取模块:提取大语言模型的内部状态表示。3) 分段感知的时间化交叉注意力模块:对齐多路径推理和内部状态的表征,计算它们之间的一致性得分。4) 幻觉检测模块:基于一致性得分,判断是否存在幻觉。整体流程是,给定输入,首先通过多路径推理模块生成多个推理路径,然后提取LLM的内部状态,接着使用分段感知的时间化交叉注意力模块对齐推理路径和内部状态的表征,最后根据对齐结果判断是否存在幻觉。
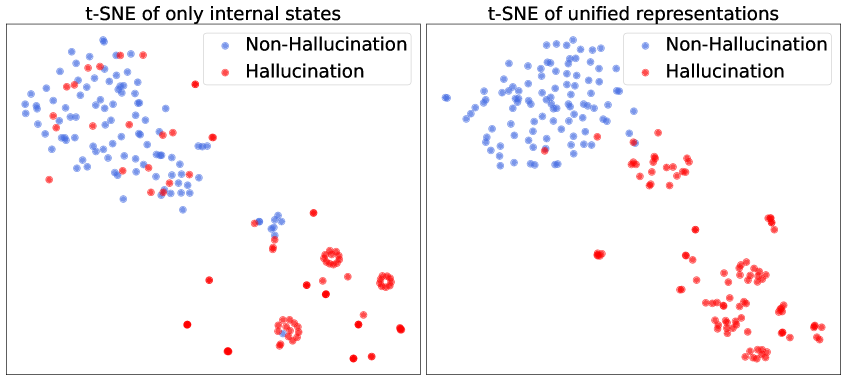
关键创新:该论文的关键创新在于提出了一个统一的框架,能够同时利用内部状态和结构化推理信息进行幻觉检测,克服了现有方法只能处理特定类型幻觉的局限性。此外,多路径推理机制和分段感知的时间化交叉注意力模块是两个重要的技术创新,前者提供了更丰富的推理信号,后者实现了内部状态和推理链表征的有效对齐。与现有方法相比,HalluDet能够更全面、准确地检测大语言模型中的幻觉。
关键设计:多路径推理模块的具体实现方式未知,可能涉及不同的提示工程策略或模型解码方法。分段感知的时间化交叉注意力模块的关键设计在于如何将推理链和内部状态进行分段,以及如何设计时间化的注意力机制,以捕捉两者之间的动态关系。损失函数的设计可能涉及对比学习或一致性损失,以鼓励内部状态和推理链表征的对齐。
🖼️ 关键图片

📊 实验亮点
实验结果表明,HalluDet在三个不同的基准测试和两个领先的大语言模型上,都显著优于现有的基线方法。具体的性能提升数据未知,但论文强调了HalluDet在检测事实性和逻辑性幻觉方面的全面性和准确性,证明了其有效性。
🎯 应用场景
该研究成果可应用于各种需要大语言模型提供可靠输出的场景,例如智能客服、自动问答系统、内容生成等。通过提高大语言模型输出的可靠性,可以增强用户信任,减少错误信息的传播,并提升人工智能系统的整体性能和安全性。未来,该技术有望成为评估和改进大语言模型的重要工具。
📄 摘要(原文)
The detection of sophisticated hallucinations in Large Language Models (LLMs) is hampered by a ``Detection Dilemma'': methods probing internal states (Internal State Probing) excel at identifying factual inconsistencies but fail on logical fallacies, while those verifying externalized reasoning (Chain-of-Thought Verification) show the opposite behavior. This schism creates a task-dependent blind spot: Chain-of-Thought Verification fails on fact-intensive tasks like open-domain QA where reasoning is ungrounded, while Internal State Probing is ineffective on logic-intensive tasks like mathematical reasoning where models are confidently wrong. We resolve this with a unified framework that bridges this critical gap. However, unification is hindered by two fundamental challenges: the Signal Scarcity Barrier, as coarse symbolic reasoning chains lack signals directly comparable to fine-grained internal states, and the Representational Alignment Barrier, a deep-seated mismatch between their underlying semantic spaces. To overcome these, we introduce a multi-path reasoning mechanism to obtain more comparable, fine-grained signals, and a segment-aware temporalized cross-attention module to adaptively fuse these now-aligned representations, pinpointing subtle dissonances. Extensive experiments on three diverse benchmarks and two leading LLMs demonstrate that our framework consistently and significantly outperforms strong baselines. Our code is available: https://github.com/peach918/HalluDet.