Who are you, ChatGPT? Personality and Demographic Style in LLM-Generated Content
作者: Dana Sotto Porat, Ella Rabinovich
分类: cs.CL
发布日期: 2025-10-13
备注: ECAI2025 (Identity-Aware AI workshop)
💡 一句话要点
提出数据驱动方法,分析大型语言模型生成内容中的人格和人口统计学特征。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 人格分析 人口统计学特征 自然语言处理 数据驱动方法
📋 核心要点
- 现有方法依赖自我报告问卷评估LLM人格,缺乏客观性,本文旨在提出一种数据驱动的评估方法。
- 核心思想是利用自动人格和性别分类器,分析LLM在开放式问题上的回复,从而推断其人格特征。
- 实验结果表明,LLM倾向于表现出更高的宜人性和更低的神经质,性别化语言模式与人类相似但变异性较低。
📝 摘要(中文)
生成式大型语言模型(LLMs)已成为日常生活的核心,在各个领域生成类人文本。越来越多的研究调查这些模型是否也在其语言中表现出人格和人口统计学特征。本文提出了一种新颖的、数据驱动的方法来评估LLM的人格,无需依赖自我报告问卷,而是将自动人格和性别分类器应用于从Reddit收集的开放式问题上的模型回复。通过将六个广泛使用的模型与人类编写的回复进行比较,我们发现LLM系统地表达出更高的宜人性和更低的神经质,反映了合作和稳定的对话倾向。模型文本中的性别化语言模式与人类作者的模式大致相似,但变异性降低,这与先前关于自动化代理的研究结果相呼应。我们贡献了一个包含人类和模型回复的新数据集,以及大规模的比较分析,从而为生成式AI的人格和人口统计学模式这一主题提供了新的见解。
🔬 方法详解
问题定义:现有方法评估LLM人格主要依赖自我报告问卷,这种方法主观性强,可能无法准确反映LLM的真实人格特征。此外,缺乏对LLM生成内容中人口统计学特征的系统性分析。
核心思路:本文的核心思路是采用数据驱动的方法,通过分析LLM在实际对话场景中的文本输出来推断其人格和人口统计学特征。这种方法避免了主观问卷调查,更加客观和可靠。通过将LLM的输出与人类的输出进行比较,可以更清晰地了解LLM在人格和人口统计学方面的表现。
技术框架:整体框架包括以下几个主要阶段:1) 数据收集:从Reddit等开放式论坛收集人类和LLM的回复数据。2) 特征提取:利用自然语言处理技术提取文本中的人格和性别相关特征。3) 模型训练:训练自动人格和性别分类器,用于预测文本的人格和性别。4) 比较分析:将LLM的预测结果与人类的预测结果进行比较,分析LLM的人格和人口统计学特征。
关键创新:最重要的技术创新点在于提出了一种无需自我报告问卷的数据驱动的LLM人格评估方法。这种方法更加客观、可靠,并且可以应用于大规模的LLM评估。此外,该研究还首次系统性地分析了LLM生成内容中的人口统计学特征。
关键设计:关键设计包括:1) 使用Reddit作为数据来源,保证了数据的多样性和真实性。2) 选择了六个广泛使用的LLM进行评估,保证了研究的代表性。3) 使用了自动人格和性别分类器,保证了评估的效率和准确性。4) 进行了大规模的比较分析,保证了研究结果的可靠性。
🖼️ 关键图片
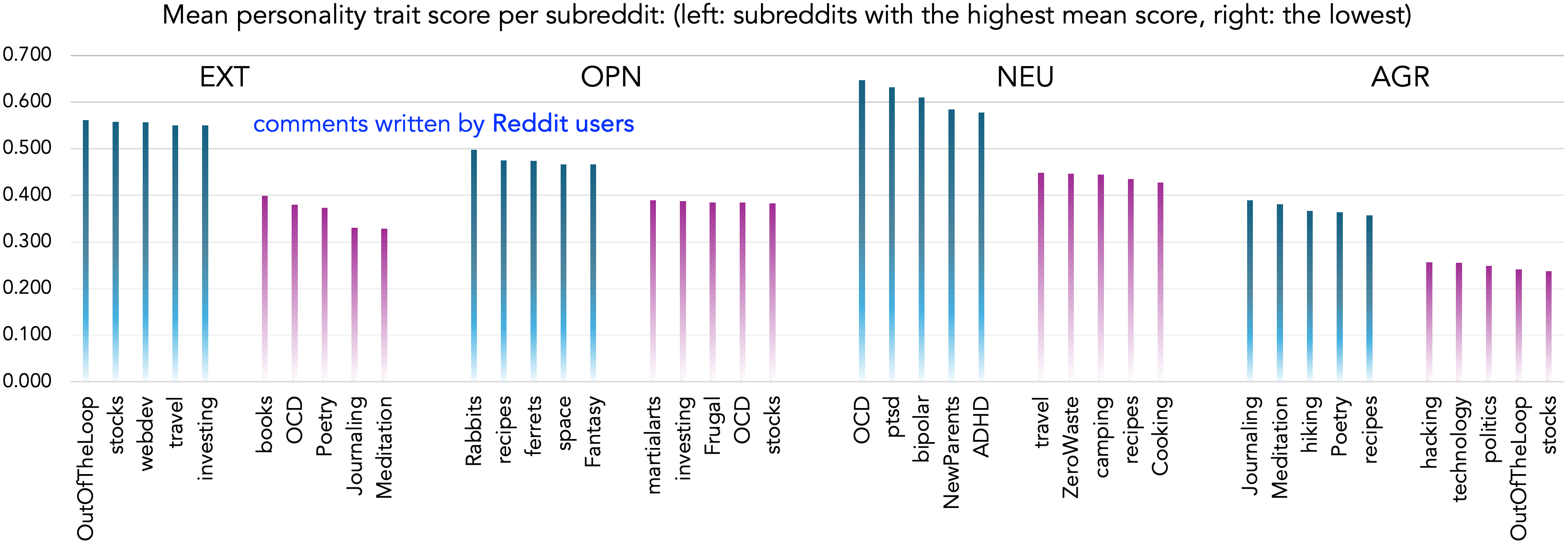

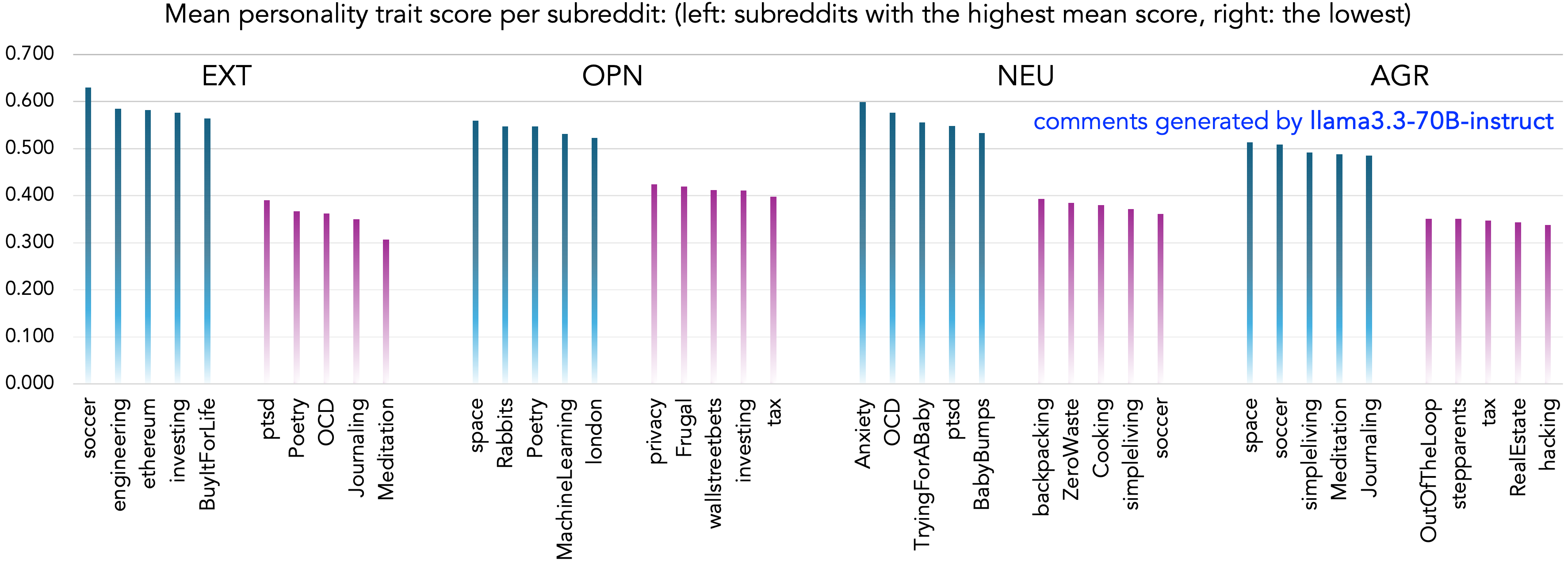
📊 实验亮点
实验结果表明,LLM在宜人性方面显著高于人类,而在神经质方面显著低于人类,表明LLM更倾向于合作和稳定的对话风格。性别化语言模式与人类相似,但变异性较低。该研究还贡献了一个包含人类和模型回复的新数据集,为后续研究提供了宝贵资源。
🎯 应用场景
该研究成果可应用于提升聊天机器人的用户体验,例如,通过调整LLM的人格特征,使其更具亲和力或专业性。此外,该研究还可以帮助我们更好地理解LLM的潜在偏见,并采取措施减少这些偏见。在教育领域,可以利用该技术分析学生作文,辅助评估学生的人格特征。
📄 摘要(原文)
Generative large language models (LLMs) have become central to everyday life, producing human-like text across diverse domains. A growing body of research investigates whether these models also exhibit personality- and demographic-like characteristics in their language. In this work, we introduce a novel, data-driven methodology for assessing LLM personality without relying on self-report questionnaires, applying instead automatic personality and gender classifiers to model replies on open-ended questions collected from Reddit. Comparing six widely used models to human-authored responses, we find that LLMs systematically express higher Agreeableness and lower Neuroticism, reflecting cooperative and stable conversational tendencies. Gendered language patterns in model text broadly resemble those of human writers, though with reduced variation, echoing prior findings on automated agents. We contribute a new dataset of human and model responses, along with large-scale comparative analyses, shedding new light on the topic of personality and demographic patterns of generative AI.