Valid Survey Simulations with Limited Human Data: The Roles of Prompting, Fine-Tuning, and Rectification
作者: Stefan Krsteski, Giuseppe Russo, Serina Chang, Robert West, Kristina Gligorić
分类: cs.CL
发布日期: 2025-10-13 (更新: 2025-10-18)
备注: 19 pages, 4 figures, 9 tables
💡 一句话要点
提出结合LLM合成与偏差校正的调查模拟方法,提升有效样本量并降低偏差。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 调查模拟 偏差校正 数据合成 有效样本量
📋 核心要点
- 传统调查成本高昂且速度慢,利用LLM生成调查回复面临显著偏差问题,影响结果有效性。
- 论文提出结合LLM合成调查回复与偏差校正的方法,优化人类数据在合成与校正间的分配。
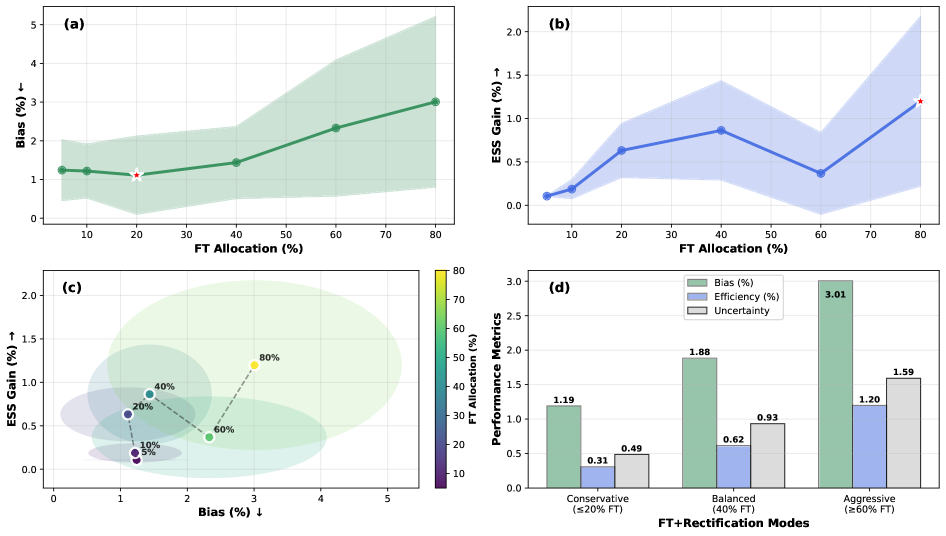
- 实验表明,结合合成与校正能显著降低偏差至5%以下,并提升有效样本量高达14%。
📝 摘要(中文)
调查是了解公众观点和行为的重要途径,但成本高且耗时。大型语言模型(LLM)已被提议作为人类受访者的可扩展、低成本替代方案,但其输出通常存在偏差,导致无效的估计。本研究探讨了使用LLM生成调查回复的合成方法与纠正人口估计偏差的校正方法之间的相互作用,并研究了如何最好地分配人类回复在这两者之间。通过对营养、政治和经济问题的两项小组调查,我们发现单独使用合成会引入大量偏差(24-86%),而将其与校正相结合可将偏差降低到5%以下,并将有效样本量提高高达14%。总的来说,我们挑战了将所有人类回复用于微调的常见做法,表明在固定预算下,将大部分分配给校正会产生更有效的估计。
🔬 方法详解
问题定义:论文旨在解决使用大型语言模型(LLM)模拟调查回复时产生的偏差问题。现有方法,如直接使用LLM生成回复或使用少量人工数据微调LLM,往往会引入显著的偏差,导致对人口统计数据的错误估计。这些偏差使得LLM在调查模拟中的应用受到限制。
核心思路:论文的核心思路是将LLM用于生成调查回复的合成方法与用于纠正人口估计偏差的校正方法相结合。通过合理分配有限的人工数据,一部分用于微调LLM以生成更真实的回复,另一部分用于校正合成数据中的偏差,从而在降低偏差的同时提高有效样本量。
技术框架:整体框架包含两个主要阶段:1) LLM合成阶段:使用Prompting或Fine-tuning的方式,利用LLM生成模拟的调查回复。Prompting直接使用预训练的LLM,而Fine-tuning则使用少量人工数据对LLM进行微调,使其更适应特定的调查问题。2) 偏差校正阶段:使用人工数据对合成数据进行校正,以减少偏差。具体的校正方法包括:a) Reweighting:根据人工数据调整合成数据的权重,以匹配真实的人口分布。b) Calibration:使用人工数据训练校准模型,将合成数据的概率分布映射到更真实的分布。
关键创新:论文的关键创新在于提出了一个结合LLM合成与偏差校正的框架,并研究了如何在两者之间最优地分配有限的人工数据。与以往的研究不同,论文强调了校正在降低偏差中的重要性,并证明了将更多的人工数据用于校正而非微调可以获得更好的效果。
关键设计:论文的关键设计包括:1) Prompting策略:设计有效的Prompt,引导LLM生成高质量的调查回复。2) Fine-tuning策略:选择合适的微调数据集和训练参数,以避免过拟合。3) 校正方法:选择合适的Reweighting或Calibration方法,并优化其参数,以最大程度地减少偏差。4) 数据分配策略:研究不同的人工数据分配比例对最终结果的影响,找到最优的分配方案。
🖼️ 关键图片

📊 实验亮点
实验结果表明,单独使用LLM合成会引入24-86%的偏差,而结合合成与校正可以将偏差降低到5%以下。此外,通过优化人工数据在合成与校正之间的分配,可以将有效样本量提高高达14%。实验还证明,在固定预算下,将更多的人工数据用于校正而非微调可以获得更好的估计效果。
🎯 应用场景
该研究成果可应用于各种需要大规模调查数据的领域,例如市场调研、舆情分析、社会科学研究等。通过利用LLM进行调查模拟,可以显著降低调查成本和时间,并为决策提供更及时、更全面的数据支持。此外,该方法还可以用于生成合成数据,以保护受访者的隐私。
📄 摘要(原文)
Surveys provide valuable insights into public opinion and behavior, but their execution is costly and slow. Large language models (LLMs) have been proposed as a scalable, low-cost substitute for human respondents, but their outputs are often biased and yield invalid estimates. We study the interplay between synthesis methods that use LLMs to generate survey responses and rectification methods that debias population estimates, and explore how human responses are best allocated between them. Using two panel surveys with questions on nutrition, politics, and economics, we find that synthesis alone introduces substantial bias (24-86%), whereas combining it with rectification reduces bias below 5% and increases effective sample size by up to 14%. Overall, we challenge the common practice of using all human responses for fine-tuning, showing that under a fixed budget, allocating most to rectification results in far more effective estimation.