Beyond Survival: Evaluating LLMs in Social Deduction Games with Human-Aligned Strategies
作者: Zirui Song, Yuan Huang, Junchang Liu, Haozhe Luo, Chenxi Wang, Lang Gao, Zixiang Xu, Mingfei Han, Xiaojun Chang, Xiuying Chen
分类: cs.CL
发布日期: 2025-10-13
备注: 34 pages, 32figures
💡 一句话要点
提出基于人类策略对齐的评估框架,用于评估LLM在狼人杀等社交推理游戏中的表现
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 社交推理游戏 狼人杀 LLM评估 策略对齐 多模态数据集
📋 核心要点
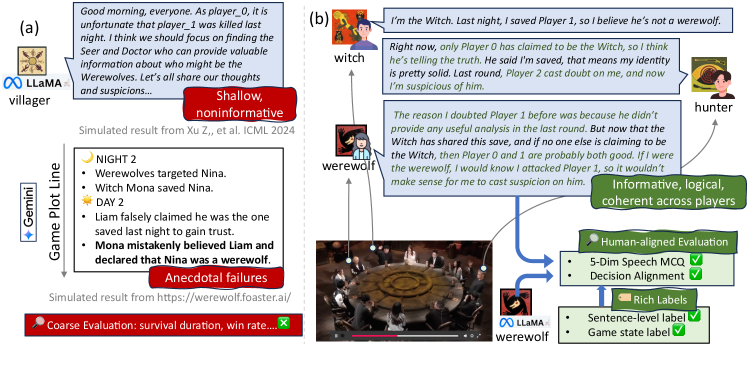
- 现有研究在评估LLM在社交推理游戏中的表现时,过度依赖自博弈和粗略指标,缺乏对复杂社交策略的有效评估。
- 论文提出一种基于人类策略对齐的评估框架,通过分析获胜阵营的策略,作为评估LLM表现的ground truth。
- 实验结果表明,现有LLM在欺骗和反事实推理方面存在明显差距,该数据集和评估框架为未来研究提供了基础。
📝 摘要(中文)
狼人杀等社交推理游戏结合了语言、推理和策略,为研究自然语言和社会智能提供了一个测试平台。然而,现有研究大多将游戏简化为基于LLM的自博弈,产生模板化的发言和零星案例,忽略了社交游戏玩法的丰富性。由于缺乏高质量的参考数据,评估也依赖于粗略的指标,如生存时间或主观评分。为了解决这些问题,我们整理了一个高质量、人工验证的多模态狼人杀数据集,包含超过100小时的视频、3240万个语篇token和15种规则变体。基于此数据集,我们提出了一种新的策略对齐评估方法,利用获胜阵营的策略作为ground truth,分两个阶段进行:1) 语音评估,将其形式化为多项选择题,评估模型在社交能力的五个维度上是否能采取适当的立场;2) 决策评估,评估模型的投票选择和对手角色推断。该框架能够对模型的语言和推理能力进行细粒度评估,同时捕捉其生成战略连贯游戏玩法的能力。实验表明,最先进的LLM表现出不同的性能,大约一半的模型仍然低于0.50,揭示了在欺骗和反事实推理方面的明显差距。我们希望我们的数据集能够进一步激发对多智能体交互中的语言、推理和策略的研究。
🔬 方法详解
问题定义:现有方法在评估LLM在狼人杀等社交推理游戏中的表现时,主要依赖于LLM自博弈,导致生成的对话模板化,缺乏多样性和策略性。同时,评估指标也较为粗略,如生存时间等,无法细致地评估LLM在语言、推理和策略方面的能力。缺乏高质量的人工标注数据也是一个关键痛点。
核心思路:论文的核心思路是利用人类玩家在狼人杀游戏中的策略作为ground truth,来评估LLM的表现。具体来说,通过分析获胜阵营的策略,提取出关键的语言模式和决策行为,然后评估LLM是否能够模仿或对齐这些策略。这种方法能够更准确地反映LLM在社交推理游戏中的真实能力。
技术框架:该评估框架主要包含两个阶段:语音评估和决策评估。在语音评估阶段,将LLM的发言转化为多项选择题,评估其在社交能力的五个维度(例如,欺骗、合作)上是否采取了适当的立场。在决策评估阶段,评估LLM的投票选择和对手角色推断是否符合获胜阵营的策略。整个框架依赖于一个高质量的多模态狼人杀数据集,该数据集包含大量的游戏视频和人工标注的语篇信息。
关键创新:该论文的关键创新在于提出了基于人类策略对齐的评估方法。与传统的自博弈评估方法相比,该方法能够更准确地评估LLM在社交推理游戏中的真实能力。此外,该论文还构建了一个高质量的多模态狼人杀数据集,为未来的研究提供了宝贵的数据资源。
关键设计:在语音评估阶段,设计了多项选择题来评估LLM在五个社交维度上的表现。这些问题基于人类玩家的发言进行设计,确保了评估的有效性。在决策评估阶段,使用了获胜阵营的策略作为ground truth,评估LLM的投票选择和角色推断。数据集包含了15种规则变体,增加了评估的泛化能力。
🖼️ 关键图片


📊 实验亮点
实验结果表明,现有最先进的LLM在狼人杀游戏中表现出不同的性能,大约一半的模型在策略对齐评估中得分低于0.50,表明LLM在欺骗和反事实推理方面存在明显差距。该研究揭示了现有LLM在复杂社交推理任务中的局限性,并为未来的研究方向提供了指导。
🎯 应用场景
该研究成果可应用于开发更智能的对话系统和社交机器人,使其能够更好地理解人类的社交行为和策略,并在多智能体环境中进行有效的沟通和协作。此外,该数据集和评估框架也可用于训练和评估LLM在其他社交推理任务中的表现,例如谈判、辩论等。
📄 摘要(原文)
Social deduction games like Werewolf combine language, reasoning, and strategy, providing a testbed for studying natural language and social intelligence. However, most studies reduce the game to LLM-based self-play, yielding templated utterances and anecdotal cases that overlook the richness of social gameplay. Evaluation further relies on coarse metrics such as survival time or subjective scoring due to the lack of quality reference data. To address these gaps, we curate a high-quality, human-verified multimodal Werewolf dataset containing over 100 hours of video, 32.4M utterance tokens, and 15 rule variants. Based on this dataset, we propose a novel strategy-alignment evaluation that leverages the winning faction's strategies as ground truth in two stages: 1) Speech evaluation, formulated as multiple-choice-style tasks that assess whether the model can adopt appropriate stances across five dimensions of social ability; and 2) Decision evaluation, which assesses the model's voting choices and opponent-role inferences. This framework enables a fine-grained evaluation of models' linguistic and reasoning capabilities, while capturing their ability to generate strategically coherent gameplay. Our experiments show that state-of-the-art LLMs show diverse performance, with roughly half remain below 0.50, revealing clear gaps in deception and counterfactual reasoning. We hope our dataset further inspires research on language, reasoning, and strategy in multi-agent interaction.