Are Large Language Models Effective Knowledge Graph Constructors?
作者: Ruirui Chen, Weifeng Jiang, Chengwei Qin, Bo Xiong, Fiona Liausvia, Dongkyu Choi, Boon Kiat Quek
分类: cs.CL
发布日期: 2025-10-13
💡 一句话要点
提出一种基于层级提取框架的知识图谱构建方法,提升LLM在知识密集型任务中的表现。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 知识图谱构建 大型语言模型 层级提取 信息抽取 儿童心理健康
📋 核心要点
- 现有基于LLM的知识图谱构建方法局限于句子级别,依赖预定义模式,缺乏对多层次信息的有效组织。
- 论文提出一种层级提取框架,旨在多层次组织信息,利用先进LLM构建语义丰富、结构良好的知识图谱。
- 实验结果揭示了当前LLM在知识图谱构建中的优缺点,并发布了儿童心理健康研究论文相关的KG数据集。
📝 摘要(中文)
知识图谱(KGs)对于知识密集型任务至关重要,并已显示出减少大型语言模型(LLMs)幻觉现象的潜力。然而,构建高质量的KG仍然很困难,需要准确的信息提取和结构化的表示,以支持可解释性和下游应用。现有的基于LLM的方法通常狭隘地关注实体和关系提取,将覆盖范围限制在句子级别的上下文中,或者依赖于预定义的模式。我们提出了一种层级提取框架,该框架在多个级别组织信息,从而能够创建语义丰富且结构良好的KG。使用最先进的LLM,我们提取并构建知识图谱,并从结构和语义的角度对其进行全面评估。我们的结果突出了当前LLM在KG构建中的优势和不足,并确定了未来工作的关键挑战。为了推进该领域的研究,我们还发布了一个精选的LLM生成的KG数据集,该数据集来源于关于儿童心理健康的研究论文。该资源旨在促进医疗保健等高风险领域中更透明、可靠和有影响力的应用。
🔬 方法详解
问题定义:现有基于LLM的知识图谱构建方法主要集中在实体和关系抽取上,忽略了更广泛的上下文信息,并且通常依赖于预定义的模式。这导致构建的知识图谱覆盖范围有限,难以捕捉复杂的语义关系,并且难以适应新的领域。因此,如何利用LLM构建更全面、更灵活、更易于扩展的知识图谱是一个重要的挑战。
核心思路:论文的核心思路是采用一种层级提取框架,将知识图谱的构建过程分解为多个层次,从粗到细地提取信息。这种方法可以更好地利用LLM的上下文理解能力,捕捉更丰富的语义信息,并且可以避免过度依赖预定义的模式。通过多层次的信息组织,可以构建出语义更丰富、结构更清晰的知识图谱。
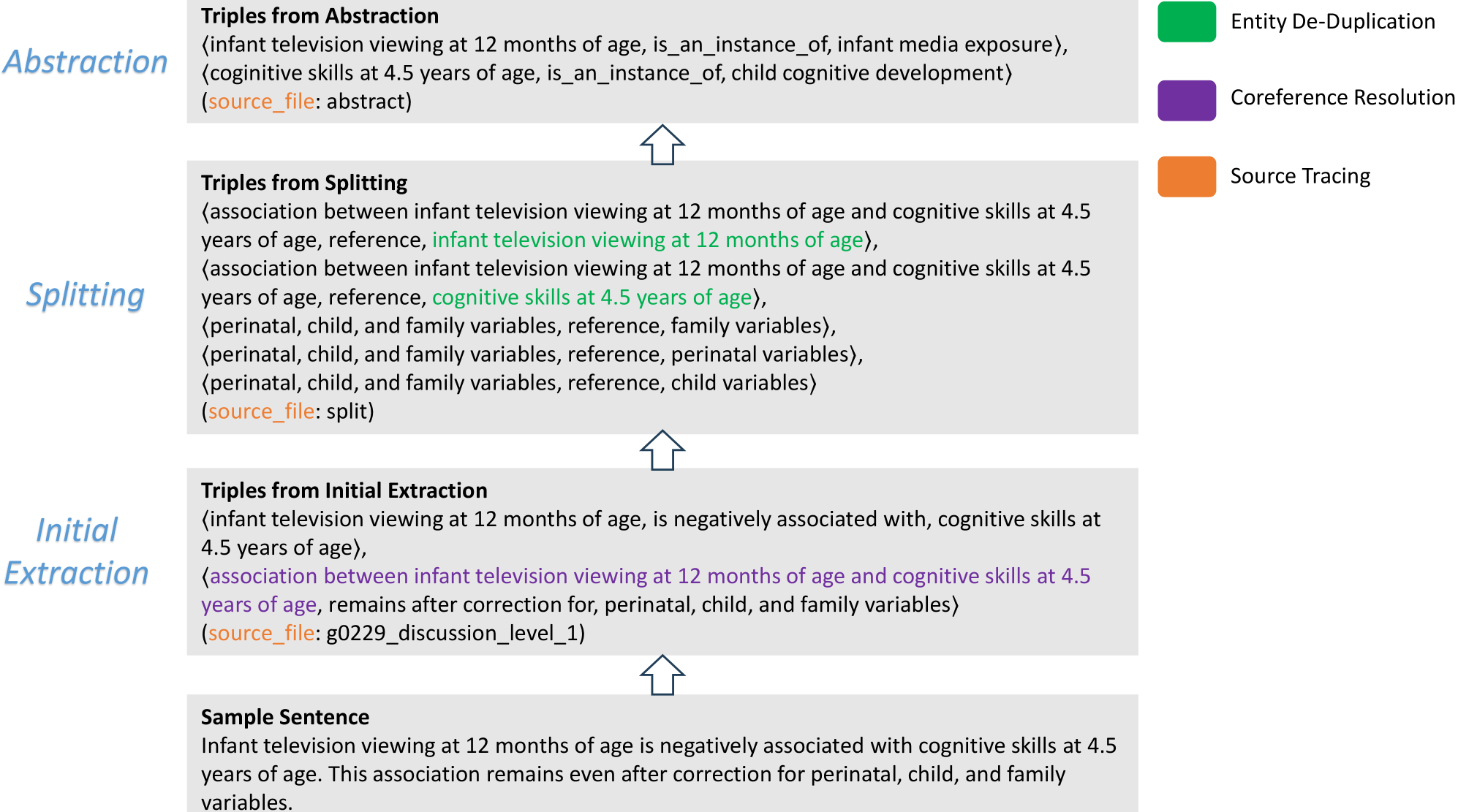
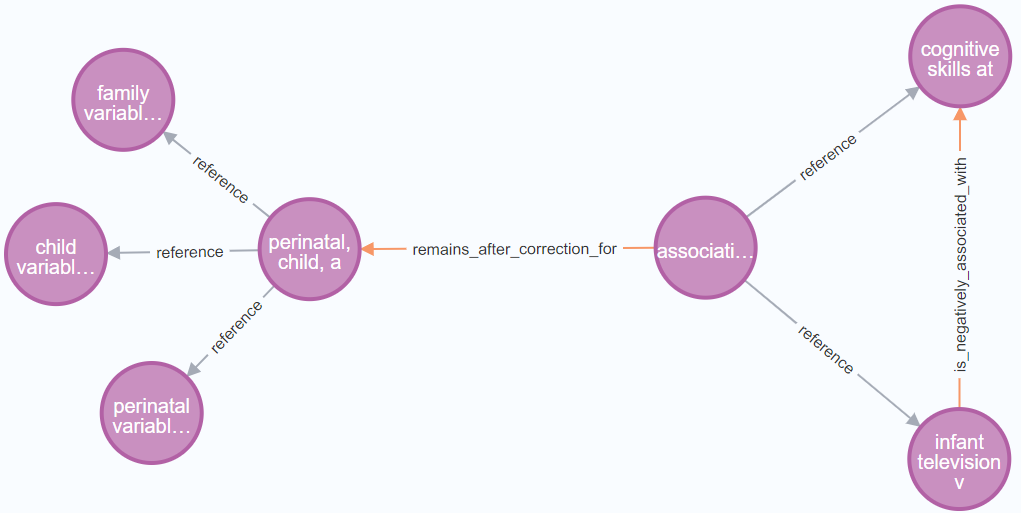
技术框架:该框架包含多个阶段,首先是文档级别的分析,识别文档的主题和关键概念。然后,在段落级别,提取段落的主题和关键信息。接着,在句子级别,提取实体和关系。最后,将提取的信息进行整合,构建知识图谱。每个阶段都利用LLM进行信息提取和推理。框架还包括一个评估模块,用于评估构建的知识图谱的质量。
关键创新:该方法最重要的创新点在于其层级提取框架。与传统的实体关系抽取方法不同,该框架能够从多个层次提取信息,从而更好地利用LLM的上下文理解能力。此外,该框架还能够避免过度依赖预定义的模式,从而可以构建更灵活、更易于扩展的知识图谱。
关键设计:在每个层次的信息提取过程中,论文使用了不同的提示工程(Prompt Engineering)技术,以引导LLM提取所需的信息。例如,在文档级别,可以使用提示语来要求LLM识别文档的主题和关键概念。在句子级别,可以使用提示语来要求LLM提取实体和关系。此外,论文还使用了不同的损失函数来优化LLM的性能。例如,可以使用交叉熵损失函数来优化实体和关系的分类性能。
🖼️ 关键图片
📊 实验亮点
论文通过实验验证了所提出的层级提取框架的有效性。实验结果表明,该方法能够构建出语义更丰富、结构更清晰的知识图谱。此外,论文还发布了一个精选的LLM生成的KG数据集,该数据集来源于关于儿童心理健康的研究论文,为相关领域的研究提供了宝贵的资源。
🎯 应用场景
该研究成果可应用于医疗健康、金融、教育等多个领域。例如,在医疗健康领域,可以利用该方法构建疾病知识图谱,辅助医生进行诊断和治疗。在金融领域,可以构建金融风险知识图谱,帮助识别和防范金融风险。此外,该方法还可以用于构建智能问答系统、推荐系统等。
📄 摘要(原文)
Knowledge graphs (KGs) are vital for knowledge-intensive tasks and have shown promise in reducing hallucinations in large language models (LLMs). However, constructing high-quality KGs remains difficult, requiring accurate information extraction and structured representations that support interpretability and downstream utility. Existing LLM-based approaches often focus narrowly on entity and relation extraction, limiting coverage to sentence-level contexts or relying on predefined schemas. We propose a hierarchical extraction framework that organizes information at multiple levels, enabling the creation of semantically rich and well-structured KGs. Using state-of-the-art LLMs, we extract and construct knowledge graphs and evaluate them comprehensively from both structural and semantic perspectives. Our results highlight the strengths and shortcomings of current LLMs in KG construction and identify key challenges for future work. To advance research in this area, we also release a curated dataset of LLM-generated KGs derived from research papers on children's mental well-being. This resource aims to foster more transparent, reliable, and impactful applications in high-stakes domains such as healthcare.