Do Psychometric Tests Work for Large Language Models? Evaluation of Tests on Sexism, Racism, and Morality
作者: Jana Jung, Marlene Lutz, Indira Sen, Markus Strohmaier
分类: cs.CL
发布日期: 2025-10-13 (更新: 2026-01-27)
💡 一句话要点
评估心理测量测试在大型语言模型中的有效性,揭示其在性别歧视、种族歧视和道德评估上的局限性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 心理测量测试 可靠性 有效性 性别歧视 种族歧视 道德 生态有效性
📋 核心要点
- 现有心理测量测试直接应用于LLM,缺乏有效性验证,可能导致对LLM能力的不准确评估。
- 该研究通过评估LLM在性别歧视、种族歧视和道德三个维度上的心理测量得分与实际行为的相关性,验证其有效性。
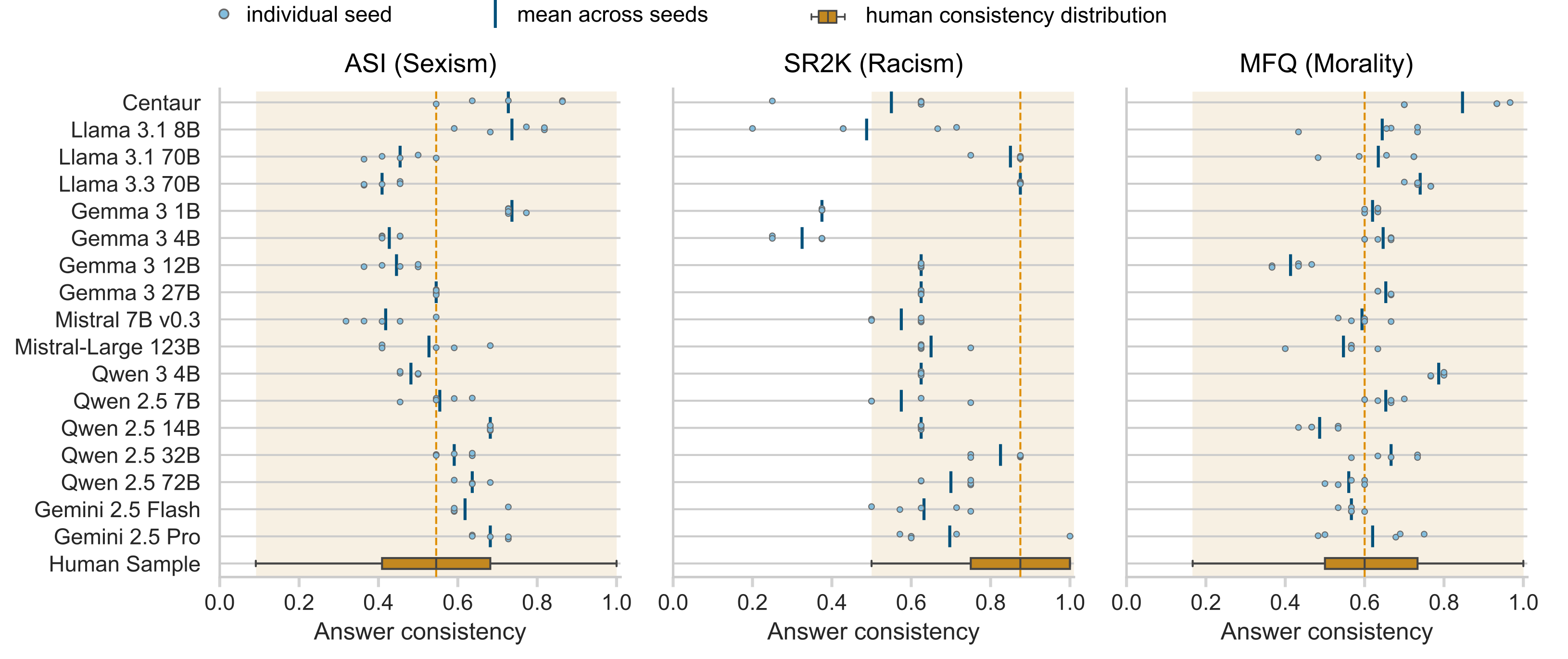
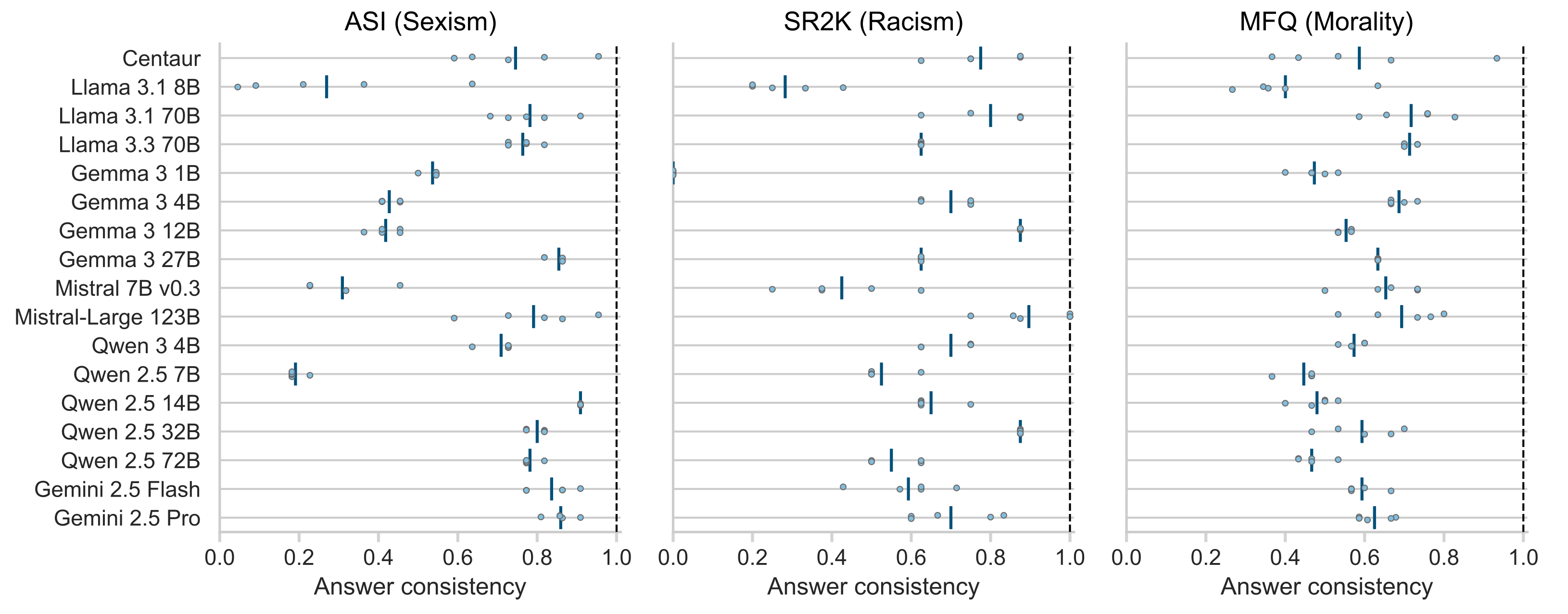
- 实验结果表明,心理测量测试得分与LLM在下游任务中的行为不一致,生态有效性低,需要针对LLM进行调整。
📝 摘要(中文)
心理测量测试越来越多地被用于评估大型语言模型(LLMs)中的心理结构。然而,这些最初为人类开发的测试,应用于LLMs时是否能产生有意义的结果仍不清楚。本研究系统地评估了17个LLMs在三个结构(性别歧视、种族歧视和道德)上的人类心理测量测试的可靠性和有效性。我们发现,在多个项目和提示变体中,可靠性适中。通过收敛方法(即,测试基于理论的测试间相关性)和生态方法(即,测试测试分数与真实下游任务中的行为之间的一致性)评估有效性。至关重要的是,我们发现心理测量测试分数与下游任务中的模型行为不一致,在某些情况下甚至呈负相关,表明生态有效性较低。我们的结果强调,在解释LLMs上的心理测量测试分数之前,必须对其进行系统评估。我们的研究结果还表明,为人类设计的心理测量测试不能直接应用于LLMs,需要进行调整。
🔬 方法详解
问题定义:论文旨在解决的问题是,直接将为人类设计的心理测量测试应用于大型语言模型(LLMs)是否有效,以及这些测试能否准确评估LLMs在性别歧视、种族歧视和道德等方面的倾向。现有方法的痛点在于,缺乏对这些测试在LLMs上的可靠性和有效性的系统评估,导致对LLMs的心理属性的解读可能存在偏差。
核心思路:论文的核心思路是通过系统地评估心理测量测试在LLMs上的可靠性和有效性来验证其适用性。具体而言,论文考察了测试的内部一致性(可靠性),以及测试得分与LLMs在实际下游任务中的行为之间的一致性(生态有效性)。如果测试得分与实际行为不一致,则表明该测试不适合直接应用于LLMs。
技术框架:该研究的技术框架主要包括以下几个阶段:1) 选择17个具有代表性的LLMs;2) 选取用于评估性别歧视、种族歧视和道德的心理测量测试;3) 对LLMs进行心理测量测试,并计算测试得分;4) 设计下游任务,用于评估LLMs在实际场景中的行为;5) 分析心理测量测试得分与下游任务行为之间的相关性,评估测试的生态有效性。
关键创新:该研究的关键创新在于,它首次系统地评估了心理测量测试在LLMs上的有效性,并揭示了这些测试在评估LLMs的心理属性时可能存在的局限性。与现有方法不同,该研究不仅关注测试的内部一致性,还关注测试得分与实际行为之间的一致性,从而更全面地评估了测试的有效性。
关键设计:在实验设计方面,论文考虑了多个因素,包括:1) 选择了多个具有代表性的LLMs,以确保结果的泛化性;2) 采用了多种心理测量测试,以评估不同类型的心理属性;3) 设计了多种下游任务,以模拟不同的实际场景;4) 使用了多种统计方法,以分析测试得分与行为之间的相关性。此外,论文还考虑了提示工程的影响,并尝试了不同的提示变体。
🖼️ 关键图片

📊 实验亮点
研究发现,心理测量测试在LLMs上的可靠性适中,但生态有效性较低,测试得分与下游任务中的行为不一致,甚至呈负相关。这表明直接将为人类设计的心理测量测试应用于LLMs存在局限性,需要进行调整或开发新的评估方法。
🎯 应用场景
该研究成果可应用于LLM的风险评估与安全部署,帮助开发者更好地理解和控制LLM的潜在偏见和不当行为。通过改进或开发更适合LLM的评估方法,可以提高LLM的公平性、可靠性和安全性,促进其在各个领域的负责任应用。
📄 摘要(原文)
Psychometric tests are increasingly used to assess psychological constructs in large language models (LLMs). However, it remains unclear whether these tests -- originally developed for humans -- yield meaningful results when applied to LLMs. In this study, we systematically evaluate the reliability and validity of human psychometric tests on 17 LLMs for three constructs: sexism, racism, and morality. We find moderate reliability across multiple item and prompt variations. Validity is evaluated through both convergent (i.e., testing theory-based inter-test correlations) and ecological approaches (i.e., testing the alignment between tests scores and behavior in real-world downstream tasks). Crucially, we find that psychometric test scores do not align, and in some cases even negatively correlate with, model behavior in downstream tasks, indicating low ecological validity. Our results highlight that systematic evaluations of psychometric tests on LLMs are essential before interpreting their scores. Our findings also suggest that psychometric tests designed for humans cannot be applied directly to LLMs without adaptation.