Evaluating Reasoning Faithfulness in Medical Vision-Language Models using Multimodal Perturbations
作者: Johannes Moll, Markus Graf, Tristan Lemke, Nicolas Lenhart, Daniel Truhn, Jean-Benoit Delbrouck, Jiazhen Pan, Daniel Rueckert, Lisa C. Adams, Keno K. Bressem
分类: cs.CL, cs.CV
发布日期: 2025-10-13 (更新: 2025-11-09)
备注: Accepted to ML4H 2025 Proceedings
💡 一句话要点
提出基于多模态扰动的医学视觉-语言模型推理忠实性评估框架,用于胸部X光VQA。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 视觉-语言模型 推理忠实性 多模态扰动 医学影像 视觉问答
📋 核心要点
- 现有VLM评估侧重于答案准确性,忽略了解释与决策过程的对齐,导致临床应用中信任度不足。
- 提出多模态扰动框架,通过控制文本和图像修改,从临床保真度、因果归因和置信度校准三方面评估CoT的忠实性。
- 实验表明答案准确性与解释质量解耦,文本线索影响大于视觉线索,专有模型在归因和保真度上优于开源模型。
📝 摘要(中文)
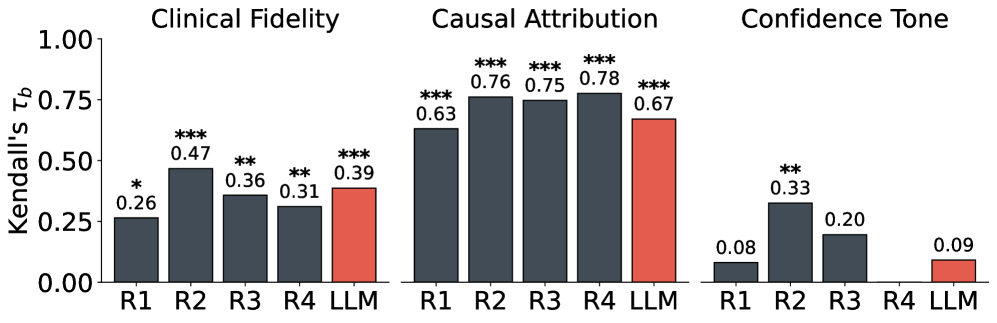
视觉-语言模型(VLMs)常生成看似合理的思维链(CoT)解释,但未能反映潜在的决策过程,从而降低了在高风险临床应用中的信任度。现有的评估很少能捕捉到这种错位,而是优先考虑答案的准确性或对格式的遵守。本文提出了一个临床基础的胸部X光视觉问答(VQA)框架,通过在三个轴上进行受控的文本和图像修改来探究CoT的忠实性:临床保真度、因果归因和置信度校准。读者研究(n=4)表明,评估者-放射科医生的相关性落在所有轴的观察到的放射科医生间范围内,归因的对齐性很强(Kendall's $τ_b=0.670$),保真度的对齐性中等($τ_b=0.387$),置信度语气的对齐性较弱($τ_b=0.091$),我们对此报告持谨慎态度。对六个VLMs的基准测试表明,答案准确性和解释质量可以解耦,承认注入的线索并不能确保基础,并且文本线索比视觉线索更能改变解释。虽然一些开源模型匹配最终答案的准确性,但专有模型在归因(25.0% vs. 1.4%)和保真度(36.1% vs. 31.7%)方面得分更高,突出了部署风险以及评估超出最终答案准确性的必要性。
🔬 方法详解
问题定义:现有视觉-语言模型在医学图像问答任务中,虽然能给出看似合理的答案,但其解释过程(思维链CoT)往往与实际决策过程不符,缺乏忠实性。现有评估方法主要关注答案准确率,忽略了对解释合理性的深入评估,导致模型在临床应用中存在潜在风险。
核心思路:通过引入多模态扰动,即对输入图像和文本进行有控制的修改,观察模型解释的变化,从而评估模型解释的忠实性。如果模型的解释对关键的图像或文本信息变化敏感,则认为其解释更忠实于输入。
技术框架:该框架包含三个主要评估轴:临床保真度(Clinical Fidelity)、因果归因(Causal Attribution)和置信度校准(Confidence Calibration)。针对每个轴,设计特定的图像和文本扰动策略。例如,在因果归因方面,通过移除图像中的关键病灶,观察模型解释中是否会相应地减少或消除对该病灶的提及。
关键创新:该方法的核心创新在于其多模态扰动策略,能够更全面地评估VLM的推理忠实性。与传统的仅关注答案准确率的评估方法相比,该方法能够深入挖掘模型解释的内在机制,揭示模型是否真正理解了图像和文本信息,并基于这些信息做出决策。
关键设计:在临床保真度方面,扰动包括引入不相关的临床信息或改变临床术语。在因果归因方面,扰动包括移除图像中的关键区域或修改文本中对关键区域的描述。在置信度校准方面,扰动包括改变问题中对模型置信度的暗示。评估指标包括模型解释与扰动之间的相关性,以及放射科医生对模型解释的评分。
🖼️ 关键图片


📊 实验亮点
实验结果表明,答案准确率与解释质量存在解耦现象,即高准确率的模型不一定具有高解释忠实性。专有模型在因果归因(25.0% vs. 1.4%)和临床保真度(36.1% vs. 31.7%)方面优于开源模型。读者研究表明,评估者-放射科医生的相关性落在观察到的放射科医生间范围内,归因的对齐性很强(Kendall's $τ_b=0.670$)。
🎯 应用场景
该研究成果可应用于医学影像辅助诊断系统,提升医生对AI诊断结果的信任度。通过评估和改进VLM的推理忠实性,可以减少误诊风险,提高诊断效率和准确性。此外,该框架也可推广到其他需要高可信度解释的AI应用领域,如金融风控、法律咨询等。
📄 摘要(原文)
Vision-language models (VLMs) often produce chain-of-thought (CoT) explanations that sound plausible yet fail to reflect the underlying decision process, undermining trust in high-stakes clinical use. Existing evaluations rarely catch this misalignment, prioritizing answer accuracy or adherence to formats. We present a clinically grounded framework for chest X-ray visual question answering (VQA) that probes CoT faithfulness via controlled text and image modifications across three axes: clinical fidelity, causal attribution, and confidence calibration. In a reader study (n=4), evaluator-radiologist correlations fall within the observed inter-radiologist range for all axes, with strong alignment for attribution (Kendall's $τ_b=0.670$), moderate alignment for fidelity ($τ_b=0.387$), and weak alignment for confidence tone ($τ_b=0.091$), which we report with caution. Benchmarking six VLMs shows that answer accuracy and explanation quality can be decoupled, acknowledging injected cues does not ensure grounding, and text cues shift explanations more than visual cues. While some open-source models match final answer accuracy, proprietary models score higher on attribution (25.0% vs. 1.4%) and often on fidelity (36.1% vs. 31.7%), highlighting deployment risks and the need to evaluate beyond final answer accuracy.