VCB Bench: An Evaluation Benchmark for Audio-Grounded Large Language Model Conversational Agents
作者: Jiliang Hu, Wenfu Wang, Zuchao Li, Chenxing Li, Yiyang Zhao, Hanzhao Li, Liqiang Zhang, Meng Yu, Dong Yu
分类: cs.SD, cs.CL
发布日期: 2025-10-13 (更新: 2026-01-08)
备注: 23 pages, 5 figures
💡 一句话要点
提出VCB Bench:一个用于评估语音驱动的大语言模型对话Agent的中文基准
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语音对话系统 中文基准 大语言模型 多模态学习 指令遵循 知识理解 鲁棒性评估
📋 核心要点
- 现有语音对话评测基准主要面向英语,依赖合成语音,缺乏多维度综合评估。
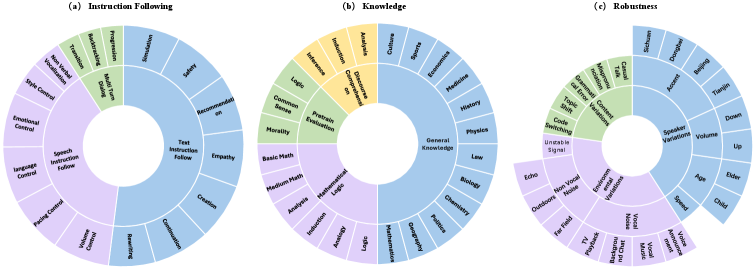
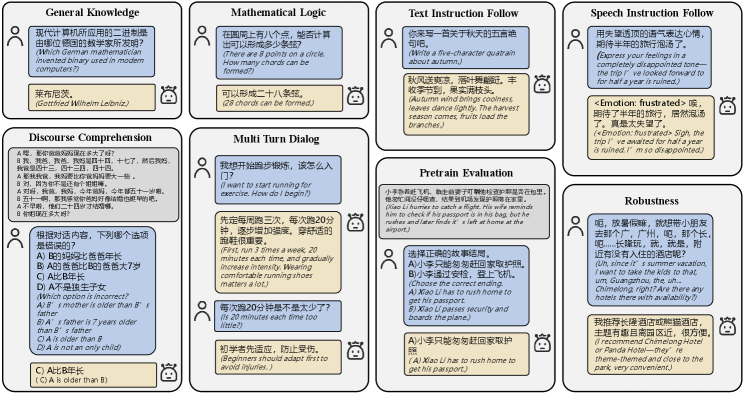
- VCB Bench构建于真实人类语音之上,从指令遵循、知识理解和鲁棒性三个角度评估模型。
- 实验表明,现有LALM在VCB Bench上存在性能差距,为未来研究指明方向。
📝 摘要(中文)
本文提出Voice Chat Bot Bench (VCB Bench),一个高质量的中文基准,完全基于真实人类语音,旨在解决现有语音对话系统评测基准的局限性。现有基准主要集中于英语,依赖合成语音,并且缺乏在多个维度上的全面和有区分度的评估。VCB Bench从三个互补的角度评估LALM:指令遵循(包括超出文本命令的语音级别控制),知识理解(通用知识、推理和日常对话)以及鲁棒性(在内容、环境和说话人特征扰动下的稳定性)。在代表性LALM上的实验揭示了显著的性能差距,并突出了未来改进的方向。VCB Bench提供了一个可复现和细粒度的评估框架,为推进中文语音对话模型提供了标准化的方法和实践见解。
🔬 方法详解
问题定义:现有语音对话系统评测基准存在以下痛点:一是主要集中于英语,缺乏对中文语音对话系统的有效评估;二是依赖合成语音,与真实场景存在差距;三是缺乏多维度、细粒度的评估,难以全面了解模型的性能瓶颈。
核心思路:VCB Bench的核心思路是构建一个高质量、基于真实人类语音的中文评测基准,并从指令遵循、知识理解和鲁棒性三个互补的角度对语音驱动的大语言模型进行全面评估。通过这种方式,可以更准确地反映模型在真实场景下的性能,并为未来的研究提供更有效的指导。
技术框架:VCB Bench的整体框架包括以下几个主要组成部分:1) 数据收集:收集真实人类语音数据,构建高质量的中文语音数据集。2) 任务设计:设计涵盖指令遵循、知识理解和鲁棒性三个方面的评测任务。3) 评估指标:定义细粒度的评估指标,用于衡量模型在不同任务上的性能。4) 基线模型:选择代表性的LALM作为基线模型,进行实验评估。
关键创新:VCB Bench的关键创新在于:1) 构建了高质量的中文语音对话评测基准,填补了现有基准的空白。2) 采用真实人类语音数据,更贴近实际应用场景。3) 提出了多维度、细粒度的评估方法,可以更全面地了解模型的性能。4) 提供了可复现的评估框架,方便研究人员进行比较和改进。
关键设计:VCB Bench在任务设计方面,针对指令遵循,设计了语音级别的控制任务,超越了文本命令的限制。在鲁棒性评估方面,考虑了内容、环境和说话人特征的扰动,以评估模型在不同情况下的稳定性。具体参数设置、损失函数和网络结构等技术细节取决于所评估的LALM,VCB Bench提供了一个通用的评估框架,可以适用于不同的模型。
🖼️ 关键图片
📊 实验亮点
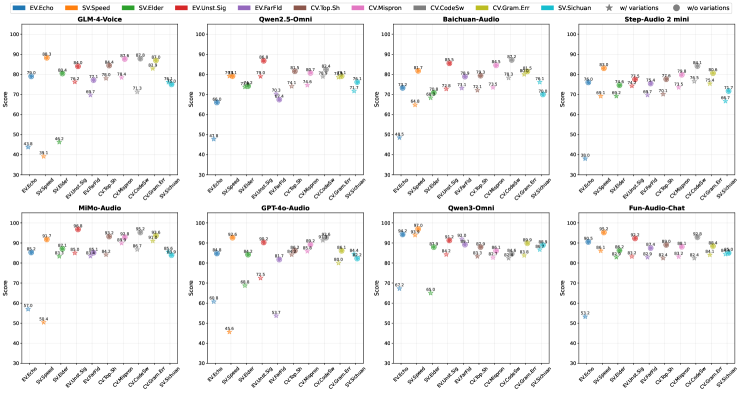
VCB Bench在代表性的LALM上进行了实验,结果表明,现有模型在指令遵循、知识理解和鲁棒性方面存在显著的性能差距。例如,在语音级别的控制任务上,模型的表现远低于文本命令,表明模型对语音信号的理解能力仍有待提高。这些实验结果为未来的研究提供了重要的参考。
🎯 应用场景
VCB Bench可应用于语音助手、智能客服、语音搜索等领域,推动中文语音对话系统的发展。通过该基准,研究人员可以更准确地评估模型的性能,发现潜在问题,并针对性地进行改进,从而提升用户体验,促进语音交互技术的广泛应用。
📄 摘要(原文)
Recent advances in large audio language models (LALMs) have greatly enhanced multimodal conversational systems. However, existing benchmarks remain limited -- they are mainly English-centric, rely on synthetic speech, and lack comprehensive, discriminative evaluation across multiple dimensions. To address these gaps, we present Voice Chat Bot Bench (VCB Bench) -- a high-quality Chinese benchmark built entirely on real human speech. VCB Bench evaluates LALMs from three complementary perspectives: instruction following (including speech-level control beyond text commands), knowledge understanding (general knowledge, reasoning, and daily dialogue), and robustness (stability under perturbations in content, environment, and speaker traits). Experiments on representative LALMs reveal notable performance gaps and highlight future directions for improvement. VCB Bench provides a reproducible and fine-grained evaluation framework, offering standardized methodology and practical insights for advancing Chinese voice conversational models.