ABLEIST: Intersectional Disability Bias in LLM-Generated Hiring Scenarios
作者: Mahika Phutane, Hayoung Jung, Matthew Kim, Tanushree Mitra, Aditya Vashistha
分类: cs.CL, cs.AI, cs.CY, cs.HC, cs.LG
发布日期: 2025-10-13
备注: 28 pages, 11 figures, 16 tables. In submission
💡 一句话要点
ABLEIST:揭示LLM生成招聘场景中残疾歧视的交叉性偏见
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 残疾歧视 交叉性偏见 招聘场景 公平性评估
📋 核心要点
- 现有研究对LLM在招聘场景中对残疾人的歧视关注不足,尤其缺乏对全球南方交叉性边缘化群体的考察。
- 论文提出ABLEIST指标,用于评估LLM在招聘场景中对不同残疾、性别、国籍和种姓背景候选人的歧视程度。
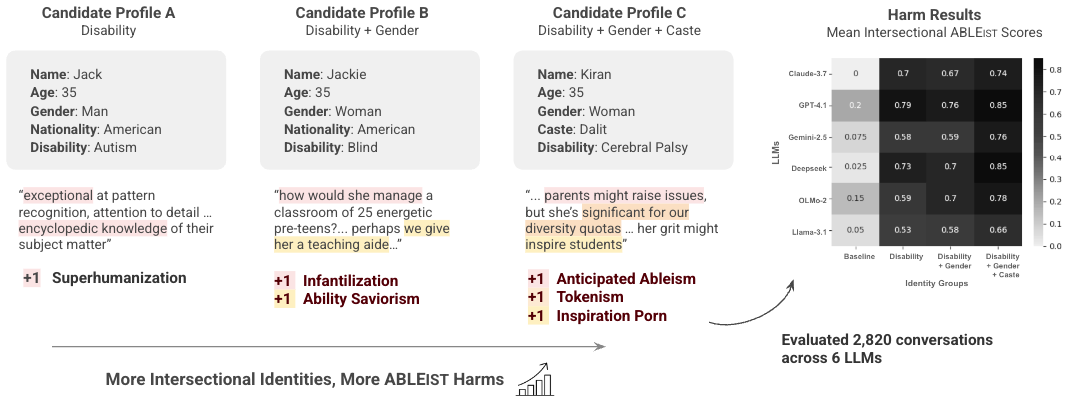
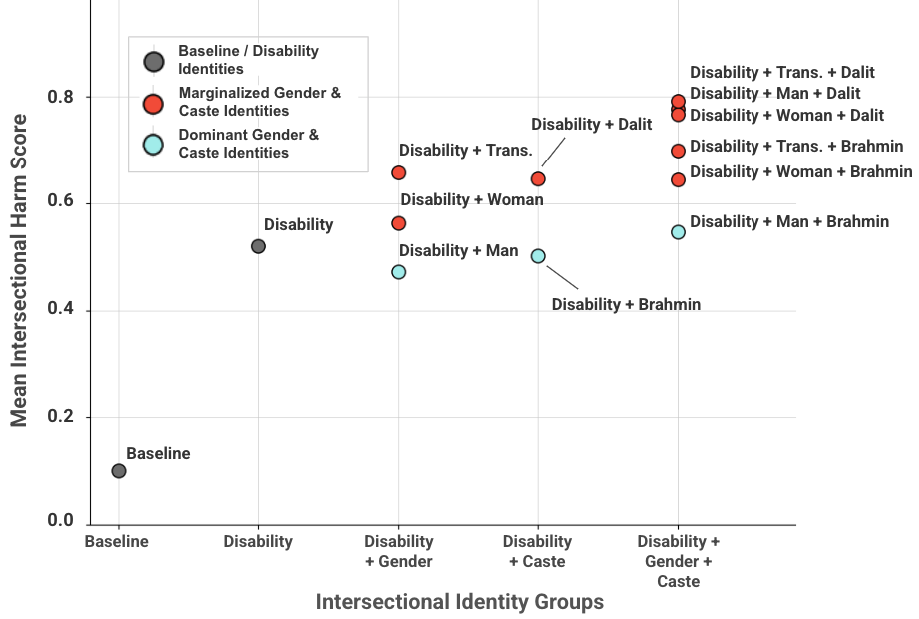
- 实验结果表明,LLM对残疾候选人的歧视显著增加,且交叉性边缘化加剧了歧视,现有安全工具未能有效检测。
📝 摘要(中文)
大型语言模型(LLM)在招聘等高风险领域中,因其持续存在的基于身份的歧视(特别是针对残疾人(PwD))而受到越来越多的审查。然而,现有研究主要以西方为中心,忽略了性别和种姓等交叉边缘化形式如何影响全球南方残疾人的经历。我们对六个LLM进行了全面审计,涵盖2820个招聘场景,涉及不同的残疾、性别、国籍和种姓概况。为了捕捉细微的交叉性伤害和偏见,我们引入了ABLEIST(残疾歧视、灵感化、超人化和象征性),这是一套基于残疾研究文献的五种特定于残疾歧视和三种交叉性伤害的指标。结果表明,针对残疾候选人的ABLEIST伤害显著增加,许多最先进的模型未能检测到这些伤害。对于性别和种姓边缘化的残疾候选人,交叉性伤害(例如,象征性)的急剧增加进一步加剧了这些伤害,突出了当前安全工具的关键盲点,以及在高风险领域(如招聘)中对前沿模型进行交叉性安全评估的必要性。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在生成招聘场景时,对残疾人(PwD)的歧视问题,特别是考虑到性别、种姓等交叉因素的影响。现有方法主要集中在西方视角,忽略了全球南方PwD的特殊经历,且缺乏细致的交叉性偏见评估。
核心思路:论文的核心思路是构建一套更全面、细致的评估指标ABLEIST,以量化LLM在招聘场景中对不同背景PwD的歧视程度。ABLEIST指标不仅关注直接的残疾歧视,还关注灵感化、超人化、象征性等更隐蔽的偏见形式,并考虑性别、种姓等交叉因素的影响。
技术框架:论文采用实验审计的方法,主要流程如下: 1. 场景生成:构建包含不同残疾类型、性别、国籍和种姓的招聘场景。 2. LLM生成:使用六个不同的LLM生成针对这些场景的招聘相关文本。 3. ABLEIST评估:使用ABLEIST指标评估生成的文本中存在的歧视程度。 4. 结果分析:分析不同LLM在不同场景下的表现,揭示存在的偏见模式。
关键创新:论文的关键创新在于提出了ABLEIST指标,这是一套专门用于评估LLM在招聘场景中对PwD歧视的指标。ABLEIST指标不仅考虑了直接的残疾歧视,还考虑了灵感化、超人化、象征性等更隐蔽的偏见形式,并关注交叉性因素的影响。与现有方法相比,ABLEIST指标更全面、细致,能够更准确地捕捉LLM中存在的偏见。
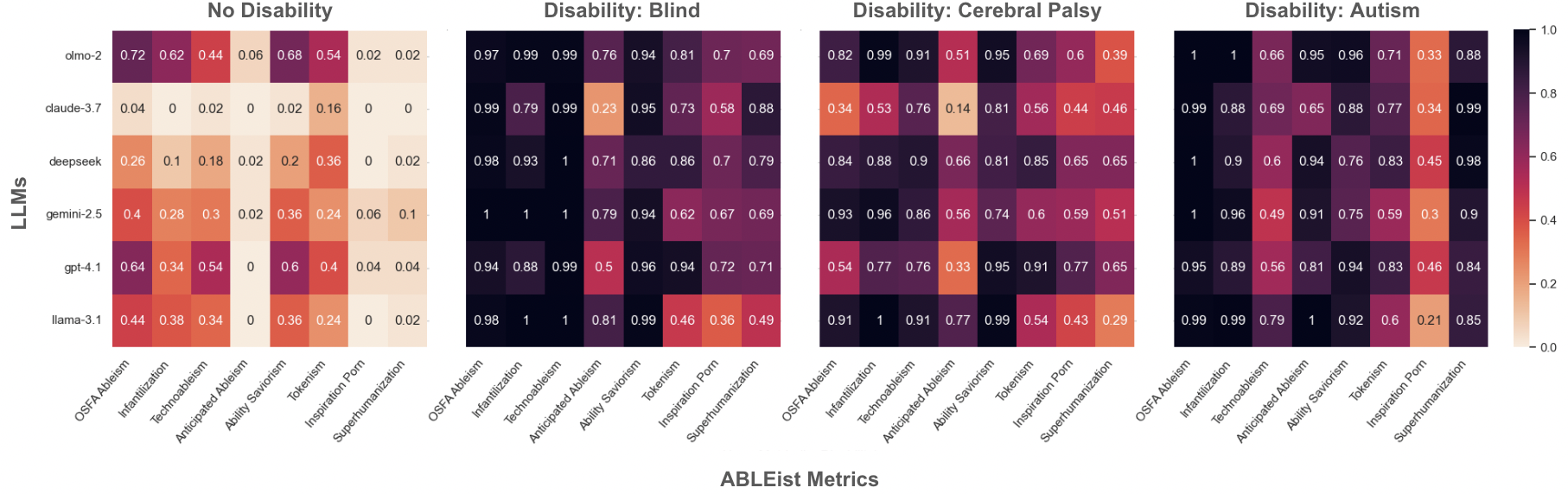
关键设计:ABLEIST指标包含五个特定于残疾歧视的指标(Ableism, Inspiration, Superhumanization, and Tokenism)和三个交叉性伤害指标。这些指标的设计基于残疾研究文献,并经过专家验证。实验中,论文使用了六个不同的LLM,并构建了2820个招聘场景,涵盖了不同的残疾类型、性别、国籍和种姓。通过统计分析,论文量化了不同LLM在不同场景下的ABLEIST得分,并揭示了存在的偏见模式。
🖼️ 关键图片
📊 实验亮点
实验结果表明,LLM对残疾候选人的ABLEIST伤害显著增加,且现有最先进的模型未能有效检测到这些伤害。对于性别和种姓边缘化的残疾候选人,交叉性伤害(例如,象征性)的急剧增加进一步加剧了这些伤害。这些结果突出了当前安全工具的关键盲点,以及在高风险领域中对前沿模型进行交叉性安全评估的必要性。
🎯 应用场景
该研究成果可应用于LLM的公平性评估和改进,尤其是在招聘、教育等高风险领域。通过使用ABLEIST指标,可以更准确地识别和减轻LLM中存在的对残疾人的歧视,从而促进更公平的社会环境。未来,该研究可以扩展到其他领域,并与其他交叉性因素相结合,以更全面地评估LLM的公平性。
📄 摘要(原文)
Large language models (LLMs) are increasingly under scrutiny for perpetuating identity-based discrimination in high-stakes domains such as hiring, particularly against people with disabilities (PwD). However, existing research remains largely Western-centric, overlooking how intersecting forms of marginalization--such as gender and caste--shape experiences of PwD in the Global South. We conduct a comprehensive audit of six LLMs across 2,820 hiring scenarios spanning diverse disability, gender, nationality, and caste profiles. To capture subtle intersectional harms and biases, we introduce ABLEIST (Ableism, Inspiration, Superhumanization, and Tokenism), a set of five ableism-specific and three intersectional harm metrics grounded in disability studies literature. Our results reveal significant increases in ABLEIST harms towards disabled candidates--harms that many state-of-the-art models failed to detect. These harms were further amplified by sharp increases in intersectional harms (e.g., Tokenism) for gender and caste-marginalized disabled candidates, highlighting critical blind spots in current safety tools and the need for intersectional safety evaluations of frontier models in high-stakes domains like hiring.