ADVICE: Answer-Dependent Verbalized Confidence Estimation
作者: Ki Jung Seo, Sehun Lim, Taeuk Kim
分类: cs.CL
发布日期: 2025-10-13 (更新: 2026-01-09)
💡 一句话要点
提出ADVICE框架,解决大语言模型中答案无关的置信度估计问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 置信度估计 答案依赖性 微调 置信度校准
📋 核心要点
- 现有大语言模型在表达置信度时存在过度自信问题,且未能充分将置信度与自身答案关联。
- ADVICE框架通过微调,促使模型在表达置信度时更多地基于其生成的答案,而非独立判断。
- 实验表明,ADVICE显著改善了置信度校准,并在未见过的场景中表现出良好的泛化能力,同时保持任务性能。
📝 摘要(中文)
大型语言模型(LLMs)的最新进展使其能够用自然语言表达其置信度,从而提高透明度和可靠性。然而,这种表达能力通常伴随着系统性的过度自信,其根本原因仍然知之甚少。本文分析了口头置信度估计的动态,并确定答案独立性(即未能将置信度建立在模型自身的答案之上)是这种行为的主要驱动因素。为了解决这个问题,我们引入了ADVICE(答案相关的口头置信度估计),这是一个微调框架,旨在促进基于答案的置信度估计。大量的实验表明,ADVICE显著提高了置信度校准,同时在不降低任务性能的情况下,对未见过的设置表现出强大的泛化能力。我们进一步证明,这些收益源于增强的答案依赖性,从而揭示了过度自信的根源,并实现了可信的置信度口头表达。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)在进行口头置信度估计时存在的过度自信和答案独立性问题。现有的LLMs在表达自己对答案的置信度时,往往不能很好地将置信度与实际生成的答案联系起来,导致置信度表达与答案质量不匹配,从而降低了模型的可信度。这种答案独立性是导致过度自信的主要原因之一。
核心思路:论文的核心思路是通过微调的方式,训练LLMs更加关注自身生成的答案,并将置信度估计建立在答案的基础上,从而提高置信度校准。ADVICE框架旨在让模型在表达置信度时,更多地考虑答案的内容和质量,而不是仅仅依赖于预训练的知识或固有的偏见。
技术框架:ADVICE框架是一个微调框架,其主要流程包括:首先,收集或生成包含问题、答案和置信度标签的数据集;然后,使用这些数据对预训练的LLM进行微调,目标是让模型能够根据给定的问题和答案,生成更准确、更可靠的置信度表达;最后,评估微调后的模型在不同任务和数据集上的置信度校准性能。
关键创新:ADVICE框架的关键创新在于其强调答案依赖性的置信度估计方法。与以往的研究不同,ADVICE明确地将答案作为置信度估计的重要输入,并通过微调的方式,促使模型学习答案与置信度之间的关系。这种方法能够有效地减少答案独立性,从而提高置信度校准。
关键设计:论文中没有明确给出关键的参数设置、损失函数、网络结构等技术细节,这些信息可能在补充材料或后续工作中给出。但是,可以推测,微调过程可能使用了交叉熵损失函数或类似的损失函数,以最小化模型预测的置信度与真实置信度之间的差异。此外,可能还使用了正则化技术,以防止模型过度拟合训练数据。
🖼️ 关键图片

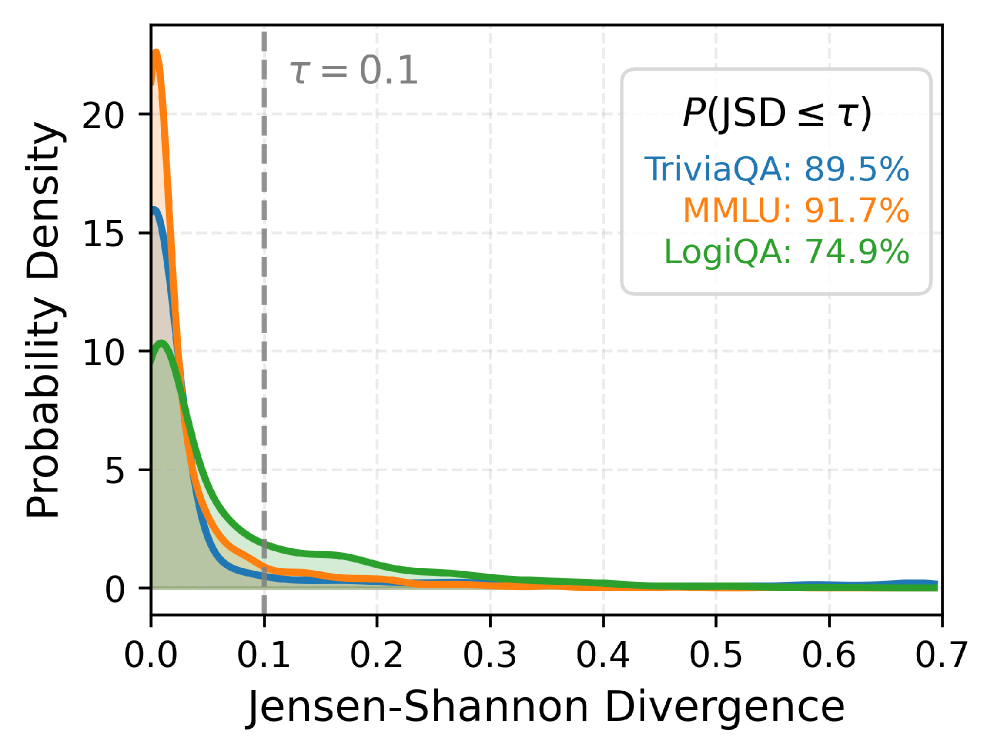
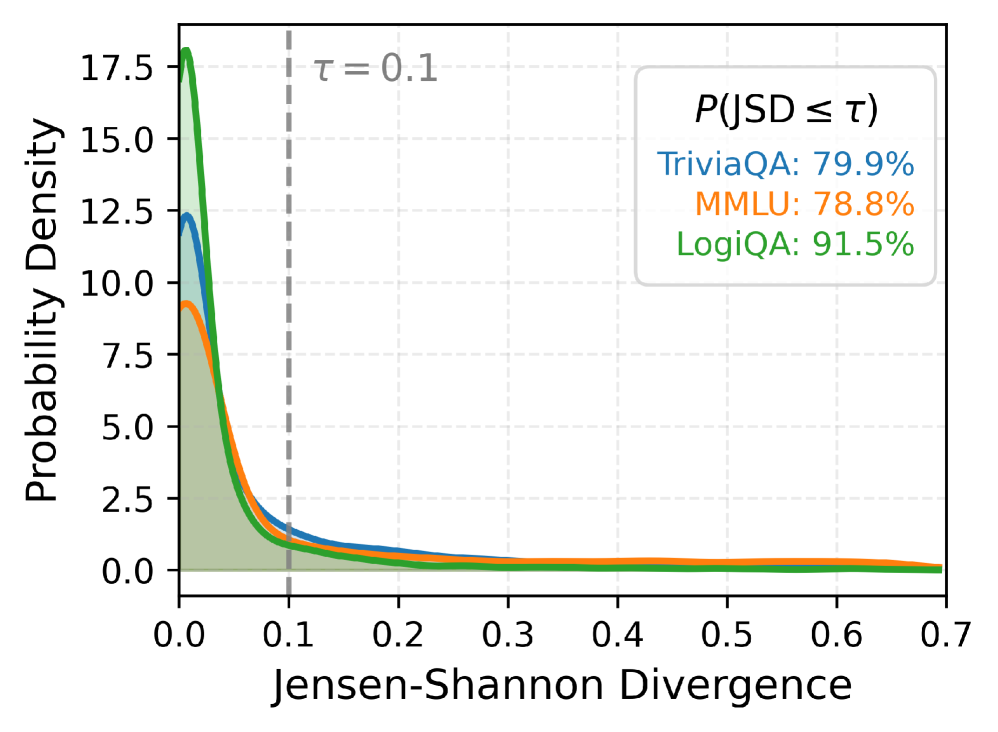
📊 实验亮点
实验结果表明,ADVICE框架能够显著提高大语言模型的置信度校准性能,并且在未见过的场景中表现出良好的泛化能力。具体来说,ADVICE在多个基准测试中都取得了优于现有方法的性能,并且在不降低任务性能的前提下,有效地减少了模型的过度自信。
🎯 应用场景
该研究成果可应用于各种需要语言模型提供置信度估计的场景,例如问答系统、对话系统、信息检索等。通过提高置信度校准,可以增强用户对模型输出的信任度,并帮助用户更好地理解和利用模型的能力。此外,该研究还可以促进对语言模型过度自信问题的深入理解,并为开发更可靠、更值得信赖的AI系统提供指导。
📄 摘要(原文)
Recent progress in large language models (LLMs) has enabled them to communicate their confidence in natural language, improving transparency and reliability. However, this expressiveness is often accompanied by systematic overconfidence, whose underlying causes remain poorly understood. In this work, we analyze the dynamics of verbalized confidence estimation and identify answer-independence -- the failure to condition confidence on the model's own answer -- as a primary driver of this behavior. To address this, we introduce ADVICE (Answer-Dependent Verbalized Confidence Estimation), a fine-tuning framework that promotes answer-grounded confidence estimation. Extensive experiments show that ADVICE substantially improves confidence calibration, while exhibiting strong generalization to unseen settings without degrading task performance. We further demonstrate that these gains stem from enhanced answer dependence, shedding light on the origins of overconfidence and enabling trustworthy confidence verbalization.