Rethinking Agentic Workflows: Evaluating Inference-Based Test-Time Scaling Strategies in Text2SQL Tasks
作者: Jiajing Guo, Kenil Patel, Jorge Piazentin Ono, Wenbin He, Liu Ren
分类: cs.CL, cs.DB
发布日期: 2025-10-13
备注: Accepted at COLM 2025 SCALR Workshop
💡 一句话要点
评估推理时缩放策略在Text2SQL任务中的有效性,优化Agentic工作流
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: Text2SQL 大型语言模型 推理时缩放 Agentic工作流 数据库查询 自然语言处理 BIRD基准 分而治之
📋 核心要点
- 现有Text2SQL系统在实际工业应用中,推理效率和准确率之间存在trade-off,尤其是在复杂推理模型上。
- 论文探索了多种轻量级的推理时缩放策略,旨在提升Text2SQL系统的性能,同时兼顾推理效率。
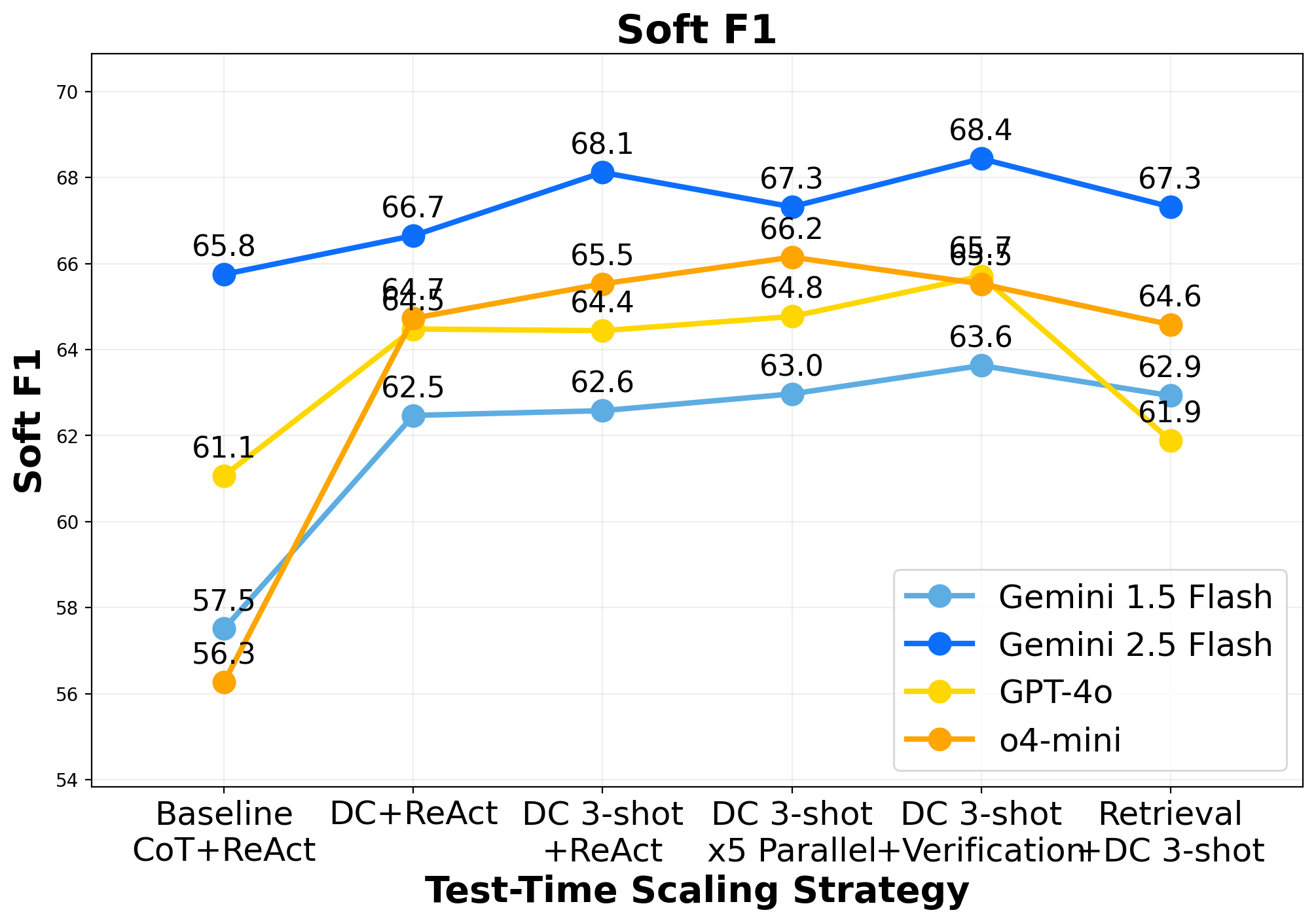
- 实验表明,分而治之的提示和少量样本演示能有效提升性能,但额外工作流步骤效果不一,基础模型选择至关重要。
📝 摘要(中文)
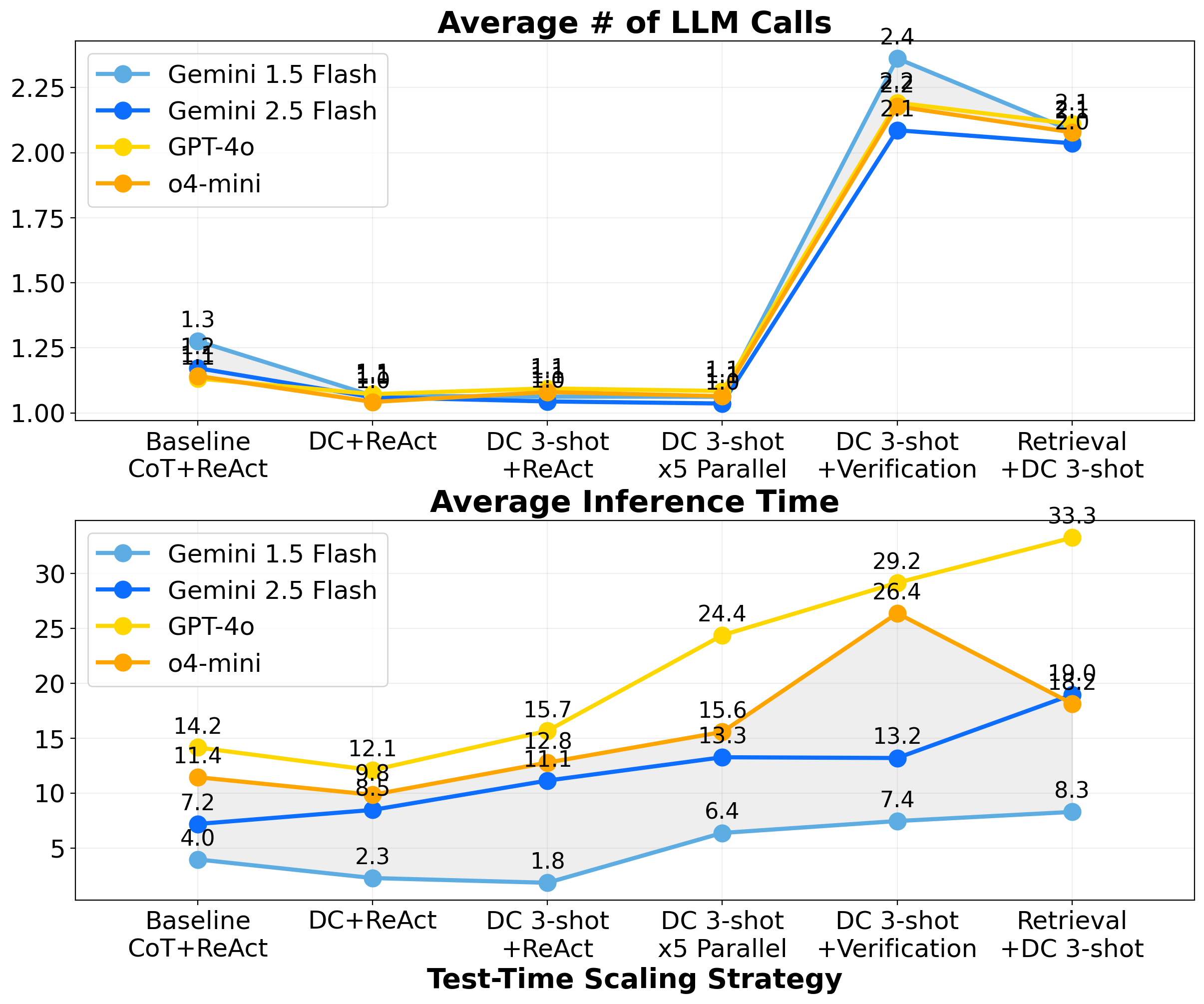
大型语言模型(LLMs)越来越多地应用于Text2SQL系统中,使得非专业用户可以使用自然语言查询工业数据库。尽管推理时缩放策略在基于LLM的解决方案中显示出潜力,但它们在实际应用中的有效性,特别是对于最新的推理模型,仍然不确定。本文对六种轻量级的、面向工业界的推理时缩放策略和四种LLM(包括两种推理模型)进行了基准测试,并在BIRD Mini-Dev基准上评估了它们的性能。除了标准准确率指标外,我们还报告了推理延迟和token消耗,从而提供了与实际系统部署相关的见解。研究结果表明,分而治之的提示和少量样本演示始终可以提高通用LLM和推理LLM的性能。然而,引入额外的工作流程步骤会产生不同的结果,并且基础模型的选择起着至关重要的作用。这项工作揭示了部署Text2SQL系统时,准确性、效率和复杂性之间的实际权衡。
🔬 方法详解
问题定义:Text2SQL任务旨在将自然语言查询转换为SQL查询语句,以便从数据库中检索信息。现有方法在处理复杂查询时,准确率和推理效率难以兼顾,尤其是在工业级数据库上。此外,如何有效利用大型语言模型的推理能力,并将其应用于实际的Text2SQL系统中,仍然是一个挑战。
核心思路:论文的核心思路是探索不同的推理时缩放策略,以优化Text2SQL系统的性能。通过对多种轻量级策略进行基准测试,分析它们在准确率、推理延迟和token消耗方面的表现,从而为实际系统部署提供指导。论文强调了基础模型选择的重要性,并研究了不同策略与不同模型的兼容性。
技术框架:论文采用了一种实验驱动的方法,对六种推理时缩放策略和四种LLM进行了基准测试。这些策略包括分而治之的提示、少量样本演示等。实验在BIRD Mini-Dev基准上进行,评估指标包括准确率、推理延迟和token消耗。通过对比不同策略和模型组合的性能,分析了它们之间的相互作用。
关键创新:论文的关键创新在于系统地评估了多种轻量级的推理时缩放策略在Text2SQL任务中的有效性,并考虑了实际系统部署中的效率问题。与以往的研究相比,论文更加关注工业应用场景,并提供了关于如何在准确率、效率和复杂性之间进行权衡的实用建议。
关键设计:论文的关键设计包括:1) 选择了具有代表性的推理时缩放策略,例如Divide-and-Conquer prompting;2) 选择了不同的LLM,包括通用模型和推理模型;3) 采用了BIRD Mini-Dev基准进行评估,该基准更贴近实际应用场景;4) 综合考虑了准确率、推理延迟和token消耗等多个指标,从而更全面地评估了不同策略的性能。
🖼️ 关键图片

📊 实验亮点
实验结果表明,Divide-and-Conquer prompting和few-shot demonstrations能够显著提升Text2SQL系统的性能。例如,在BIRD Mini-Dev基准上,采用Divide-and-Conquer prompting的系统在准确率方面取得了显著提升。此外,论文还发现,基础模型的选择对最终性能至关重要,不同的策略与不同的模型之间存在相互作用。
🎯 应用场景
该研究成果可应用于各种需要自然语言查询数据库的场景,例如智能客服、商业智能分析、数据挖掘等。通过优化Text2SQL系统的性能,可以提高用户查询效率,降低使用门槛,并为企业提供更准确、更及时的决策支持。未来的研究可以进一步探索更有效的推理时缩放策略,并将其应用于更复杂的数据库和查询场景。
📄 摘要(原文)
Large language models (LLMs) are increasingly powering Text-to-SQL (Text2SQL) systems, enabling non-expert users to query industrial databases using natural language. While test-time scaling strategies have shown promise in LLM-based solutions, their effectiveness in real-world applications, especially with the latest reasoning models, remains uncertain. In this work, we benchmark six lightweight, industry-oriented test-time scaling strategies and four LLMs, including two reasoning models, evaluating their performance on the BIRD Mini-Dev benchmark. Beyond standard accuracy metrics, we also report inference latency and token consumption, providing insights relevant for practical system deployment. Our findings reveal that Divide-and-Conquer prompting and few-shot demonstrations consistently enhance performance for both general-purpose and reasoning-focused LLMs. However, introducing additional workflow steps yields mixed results, and base model selection plays a critical role. This work sheds light on the practical trade-offs between accuracy, efficiency, and complexity when deploying Text2SQL systems.