Multimodal Retrieval-Augmented Generation with Large Language Models for Medical VQA
作者: A H M Rezaul Karim, Ozlem Uzuner
分类: cs.CL, cs.AI, cs.CV
发布日期: 2025-10-12
💡 一句话要点
提出基于检索增强生成(RAG)的通用大语言模型,用于医学VQA任务,提升临床决策支持。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 医学视觉问答 检索增强生成 大语言模型 临床决策支持 多模态学习
📋 核心要点
- 医学VQA任务面临挑战,现有方法难以有效利用临床知识,生成高质量的、符合医学规范的答案。
- 论文提出一种基于检索增强生成(RAG)的框架,利用领域内数据中的文本和视觉示例,增强大语言模型的推理能力。
- 实验结果表明,该方法在MEDIQA-WV 2025伤口护理VQA任务中取得了显著成果,排名第三,验证了其有效性。
📝 摘要(中文)
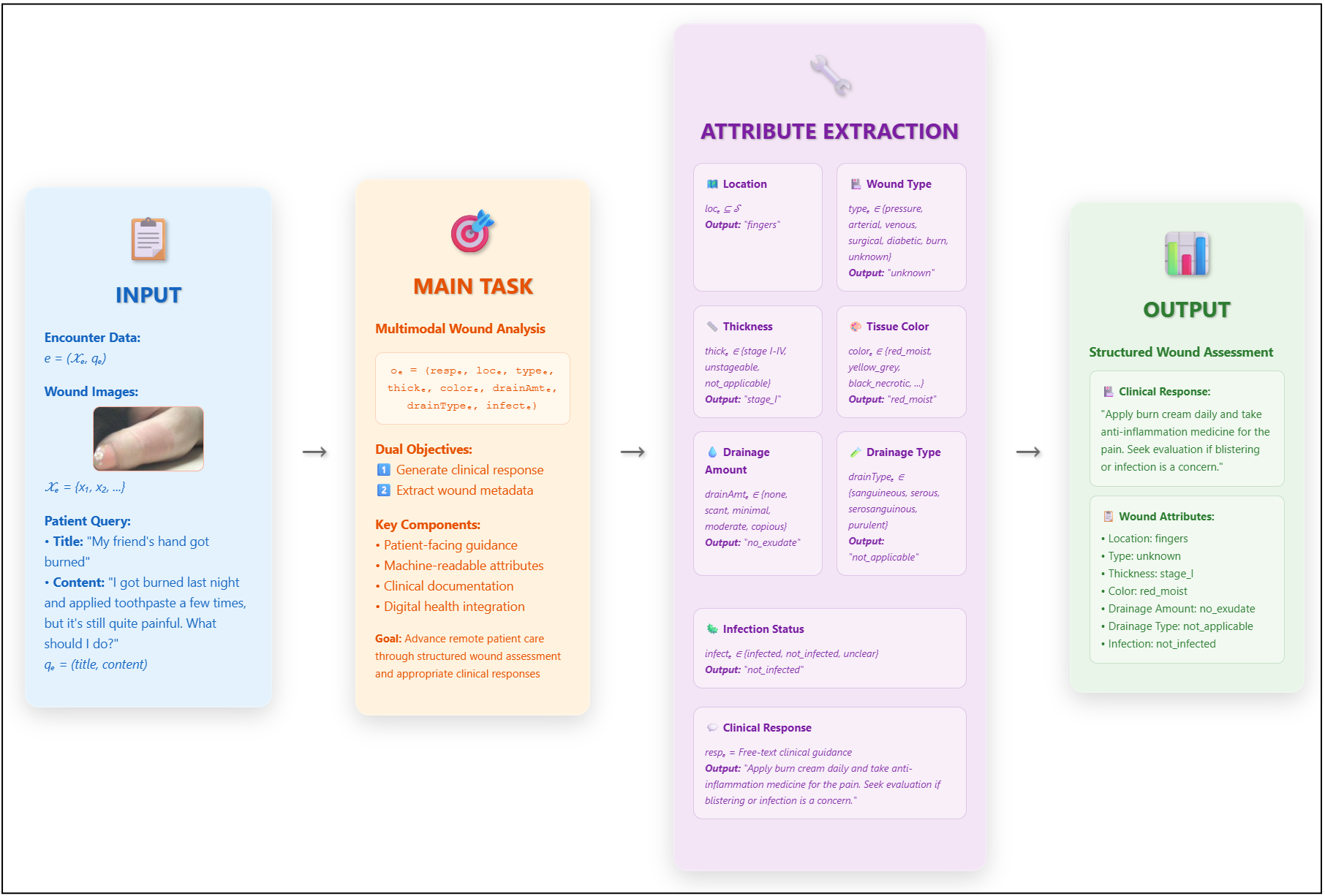
医学视觉问答(MedVQA)通过医学图像上的自然语言查询来支持临床决策和患者护理。MEDIQA-WV 2025共享任务关注伤口护理VQA,要求系统从图像和患者查询中生成自由文本回复和结构化伤口属性。我们提出了MasonNLP系统,该系统采用通用领域的、指令微调的大语言模型,并结合检索增强生成(RAG)框架,该框架整合了来自领域内数据的文本和视觉示例。这种方法将输出建立在临床相关的示例之上,从而提高推理、模式遵循和响应质量,通过dBLEU、ROUGE、BERTScore和基于LLM的指标进行评估。我们表现最佳的系统在19个团队和51个提交中排名第三,平均得分41.37%,表明轻量级RAG与通用LLM(一个最小的推理时层,通过简单的索引和融合添加一些相关的示例,无需额外的训练或复杂的重新排序)为多模态临床NLP任务提供了一个简单而有效的基线。
🔬 方法详解
问题定义:论文旨在解决医学视觉问答(MedVQA)任务中,现有方法难以充分利用临床知识,生成准确、高质量答案的问题。现有方法可能缺乏对特定医学领域的理解,导致推理能力不足,无法生成符合医学规范的回复。
核心思路:论文的核心思路是利用检索增强生成(RAG)框架,通过检索领域内相关的文本和视觉示例,为大语言模型提供上下文信息,从而增强其推理能力和生成质量。这种方法旨在将大语言模型的通用知识与特定领域的临床知识相结合。
技术框架:MasonNLP系统的整体架构包含以下几个主要模块:1) 查询编码器:将输入的医学图像和患者查询编码为向量表示。2) 检索模块:基于编码后的查询向量,从领域内数据集中检索相关的文本和视觉示例。3) 融合模块:将检索到的示例与原始查询进行融合,形成增强的上下文信息。4) 大语言模型:利用增强的上下文信息,生成自由文本回复和结构化伤口属性。
关键创新:该方法最重要的创新点在于轻量级的RAG框架,它可以在推理时动态地检索相关的临床示例,而无需额外的训练或复杂的重新排序。这种方法简单有效,能够显著提高大语言模型在医学VQA任务中的性能。
关键设计:论文采用通用领域的、指令微调的大语言模型作为基础模型。检索模块使用简单的索引方法,例如基于余弦相似度的向量检索。融合模块采用简单的拼接或加权平均等方法,将检索到的示例与原始查询进行融合。没有提及具体的损失函数或网络结构细节。
🖼️ 关键图片

📊 实验亮点
MasonNLP系统在MEDIQA-WV 2025伤口护理VQA任务中排名第三,平均得分41.37%。实验结果表明,轻量级RAG框架能够显著提高大语言模型在医学VQA任务中的性能,验证了该方法的有效性。该方法无需额外训练,易于部署和应用。
🎯 应用场景
该研究成果可应用于临床决策支持系统,辅助医生进行诊断和治疗方案制定。通过提供准确、可靠的医学视觉问答服务,可以提高医疗效率,改善患者护理质量。未来,该方法还可扩展到其他医学领域,例如放射学报告生成、病理图像分析等。
📄 摘要(原文)
Medical Visual Question Answering (MedVQA) enables natural language queries over medical images to support clinical decision-making and patient care. The MEDIQA-WV 2025 shared task addressed wound-care VQA, requiring systems to generate free-text responses and structured wound attributes from images and patient queries. We present the MasonNLP system, which employs a general-domain, instruction-tuned large language model with a retrieval-augmented generation (RAG) framework that incorporates textual and visual examples from in-domain data. This approach grounds outputs in clinically relevant exemplars, improving reasoning, schema adherence, and response quality across dBLEU, ROUGE, BERTScore, and LLM-based metrics. Our best-performing system ranked 3rd among 19 teams and 51 submissions with an average score of 41.37%, demonstrating that lightweight RAG with general-purpose LLMs -- a minimal inference-time layer that adds a few relevant exemplars via simple indexing and fusion, with no extra training or complex re-ranking -- provides a simple and effective baseline for multimodal clinical NLP tasks.