Is Implicit Knowledge Enough for LLMs? A RAG Approach for Tree-based Structures
作者: Mihir Gupte, Paolo Giusto, Ramesh S
分类: cs.CL, cs.AI, cs.IR, cs.LG
发布日期: 2025-10-12 (更新: 2025-10-21)
备注: Waiting for Conference Response
💡 一句话要点
提出基于RAG的树结构知识线性化方法,提升LLM在层级数据上的效率。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 检索增强生成 RAG 大型语言模型 知识线性化 树状结构 代码理解 信息检索
📋 核心要点
- 现有RAG方法在处理树状结构等层级数据时,知识表示方式不够有效,影响LLM的推理效率。
- 提出一种自底向上的知识线性化方法,通过在每个层级生成隐式摘要,将树状结构知识转化为线性表示。
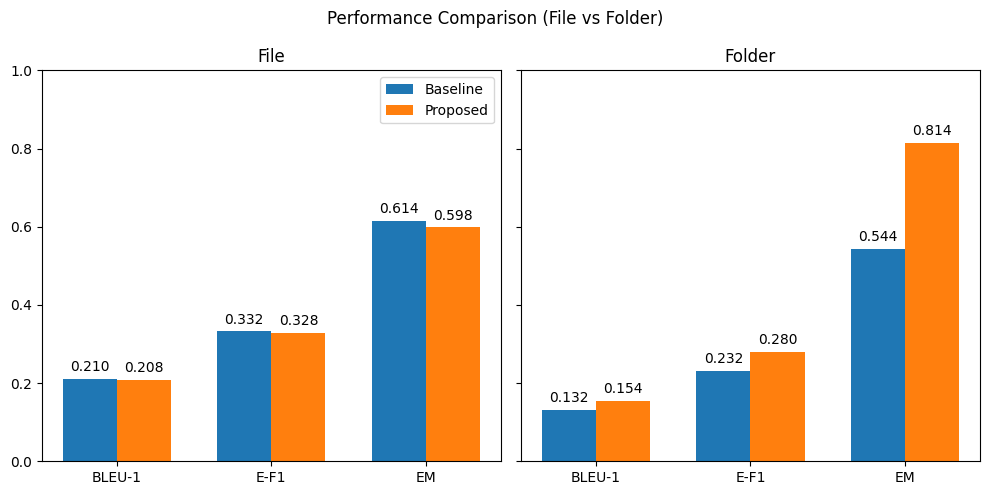
- 实验表明,该方法在保证响应质量的同时,显著减少了RAG检索的文档数量,提升了效率。
📝 摘要(中文)
大型语言模型(LLMs)擅长根据上下文信息生成响应。检索增强生成(RAG)是另一种流行的方法,它检索相关文档来增强模型的上下文学习。然而,如何最好地表示检索到的知识以生成关于结构化数据(特别是像树这样的层级结构)的响应,尚未得到充分探索。本文提出了一种新颖的自底向上的方法,通过在每个层级生成隐式的、聚合的摘要来线性化来自树状结构(如GitHub存储库)的知识。这种方法使得知识能够存储在知识库中,并直接与RAG一起使用。我们将我们的方法与在原始、非结构化代码上使用RAG进行比较,评估生成响应的准确性和质量。结果表明,虽然两种方法的响应质量相当,但我们的方法在检索器中生成的文档数量减少了68%以上,效率显著提高。这一发现表明,利用隐式的、线性化的知识可能是处理复杂、层级数据结构的一种非常有效且可扩展的策略。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)在处理树状结构数据(例如代码仓库)时,如何更有效地利用检索增强生成(RAG)的问题。现有方法直接在原始、非结构化的代码上使用RAG,导致检索效率低下,需要检索大量文档才能获得相关信息。
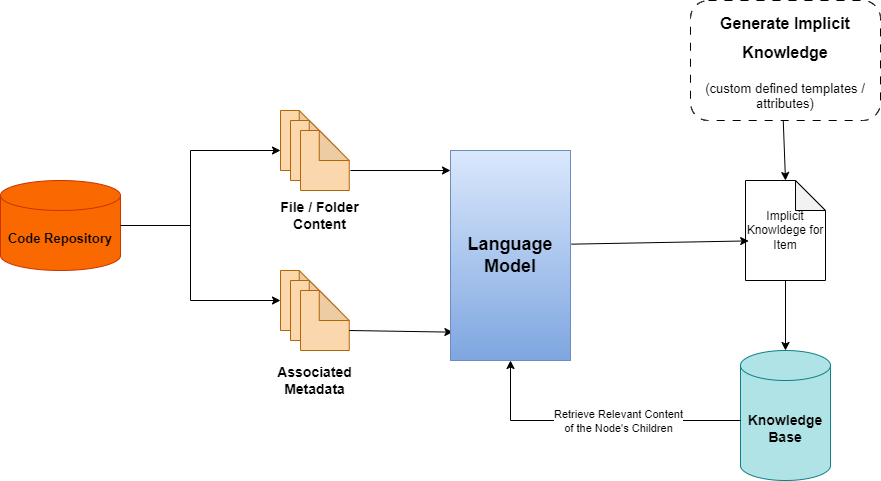
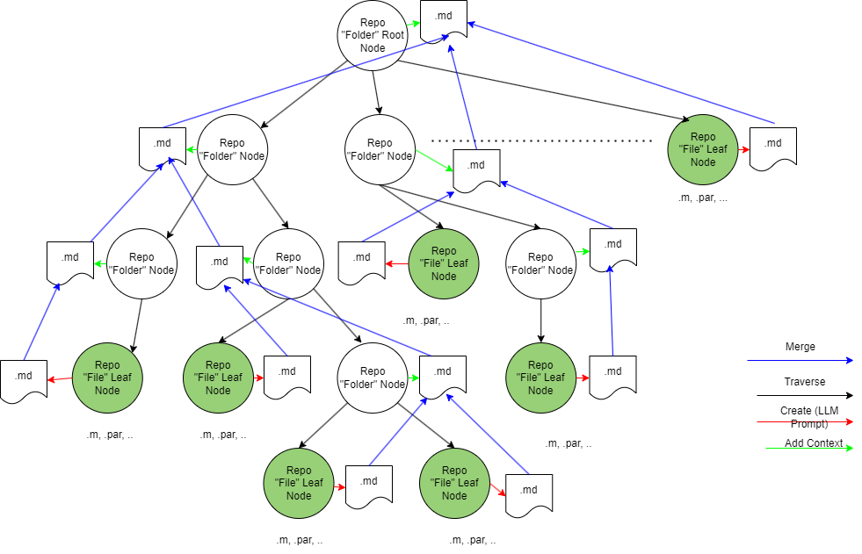
核心思路:论文的核心思路是通过一种自底向上的方法,将树状结构的知识线性化,生成隐式的、聚合的摘要。这种方法将层级结构的信息压缩到每个层级的摘要中,从而减少了RAG需要检索的文档数量,提高了效率。
技术框架:该方法包含以下几个主要阶段:1) 树结构构建:将原始数据(例如代码仓库)解析为树状结构。2) 自底向上摘要生成:从叶节点开始,逐层向上生成每个节点的摘要,摘要包含了该节点及其子节点的关键信息。3) 知识库构建:将生成的摘要存储在知识库中,用于RAG检索。4) RAG检索与生成:使用RAG从知识库中检索相关摘要,并将其作为上下文输入到LLM中,生成最终的响应。
关键创新:该方法最重要的技术创新点在于提出了自底向上的知识线性化方法,通过隐式摘要的方式,将树状结构的知识压缩到每个层级,从而减少了RAG的检索范围,提高了效率。与直接在原始数据上使用RAG相比,该方法能够更有效地利用层级结构的信息。
关键设计:论文中没有明确说明摘要生成所使用的具体模型或算法,这部分可能是未来的研究方向。关键在于如何设计有效的摘要生成策略,能够准确地捕捉每个层级的关键信息,并将其压缩到摘要中。此外,如何选择合适的RAG模型和检索策略,也是影响最终性能的关键因素。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该方法在保证响应质量与直接在原始代码上使用RAG相当的情况下,能够减少超过68%的检索文档数量。这表明该方法能够显著提升RAG的效率,使其更适用于处理大规模的层级结构数据。
🎯 应用场景
该研究成果可应用于代码理解、知识图谱问答、文档检索等领域。通过将层级结构数据转化为线性表示,可以提升LLM在处理复杂结构化数据时的效率和准确性。未来可应用于智能客服、软件开发辅助等场景,帮助用户更高效地获取和利用知识。
📄 摘要(原文)
Large Language Models (LLMs) are adept at generating responses based on information within their context. While this ability is useful for interacting with structured data like code files, another popular method, Retrieval-Augmented Generation (RAG), retrieves relevant documents to augment the model's in-context learning. However, it is not well-explored how to best represent this retrieved knowledge for generating responses on structured data, particularly hierarchical structures like trees. In this work, we propose a novel bottom-up method to linearize knowledge from tree-like structures (like a GitHub repository) by generating implicit, aggregated summaries at each hierarchical level. This approach enables the knowledge to be stored in a knowledge base and used directly with RAG. We then compare our method to using RAG on raw, unstructured code, evaluating the accuracy and quality of the generated responses. Our results show that while response quality is comparable across both methods, our approach generates over 68% fewer documents in the retriever, a significant gain in efficiency. This finding suggests that leveraging implicit, linearized knowledge may be a highly effective and scalable strategy for handling complex, hierarchical data structures.