RePro: Training Language Models to Faithfully Recycle the Web for Pretraining
作者: Zichun Yu, Chenyan Xiong
分类: cs.CL, cs.LG
发布日期: 2025-10-12
🔗 代码/项目: GITHUB
💡 一句话要点
提出RePro,通过强化学习训练语言模型,高效且忠实地复用Web数据进行预训练。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语言模型预训练 数据增强 强化学习 Web数据复用 文本改写
📋 核心要点
- 大型语言模型预训练数据需求日益增长,高质量数据资源逐渐稀缺,现有方法难以有效利用已有数据。
- RePro利用强化学习训练小型语言模型,生成原始数据的有效且忠实的改写,从而扩充预训练数据集。
- 实验表明,RePro在下游任务上显著优于现有Web数据复用方法,并能有效提升原始数据的利用效率。
📝 摘要(中文)
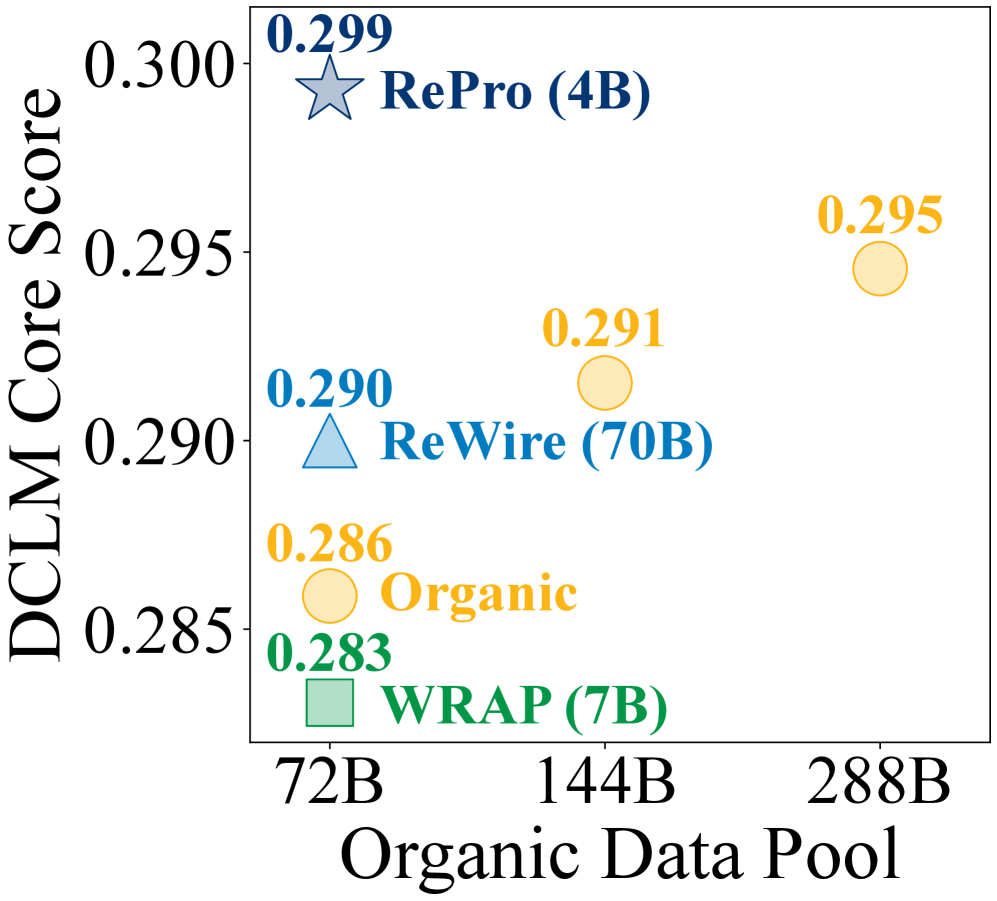
高质量的预训练数据是大型语言模型(LLM)的燃料,但对于前沿模型而言,其储备正在减少。本文介绍了一种新颖的Web数据复用方法RePro,该方法使用强化学习训练一个相对较小的LM,以生成有效且忠实的预训练数据改写。具体来说,我们设计了一个质量奖励和三个忠实度奖励,优化LM改写器,将原始数据转换为高质量的改写,同时保持其核心语义和结构。在我们的实验中,我们训练了一个4B的改写器来复用从DCLM-RefinedWeb中抽样的72B tokens。在400M和1.4B模型上的预训练结果表明,RePro在22个下游任务上实现了比仅使用原始数据基线高4.7%-14.0%的相对准确率提升。RePro也优于ReWire,这是一种最先进的Web数据复用方法,它提示一个70B的改写器,并且优于数据量大4倍的原始数据基线。使用不同数量的回收数据的实验表明,RePro将原始数据效率提高了2-3倍。个体和分布分析验证了与基于提示的方法相比,RePro保留了更多关键信息并忠实地反映了原始数据的特征。总之,这些结果表明,RePro提供了一种高效且可控的途径来有效地利用LLM预训练的燃料。我们在https://github.com/cxcscmu/RePro开源了我们的代码、改写器和回收数据。
🔬 方法详解
问题定义:论文旨在解决大型语言模型预训练数据不足的问题。现有方法,如直接使用原始数据或基于prompt的方法,要么质量不高,要么无法保证改写后的数据与原始数据的一致性,导致模型性能提升有限。
核心思路:论文的核心思路是训练一个小型语言模型(LM)作为“改写器”,通过强化学习生成原始数据的改写版本。通过精心设计的奖励函数,引导改写器生成高质量且忠实于原始语义和结构的数据,从而有效扩充预训练数据集。
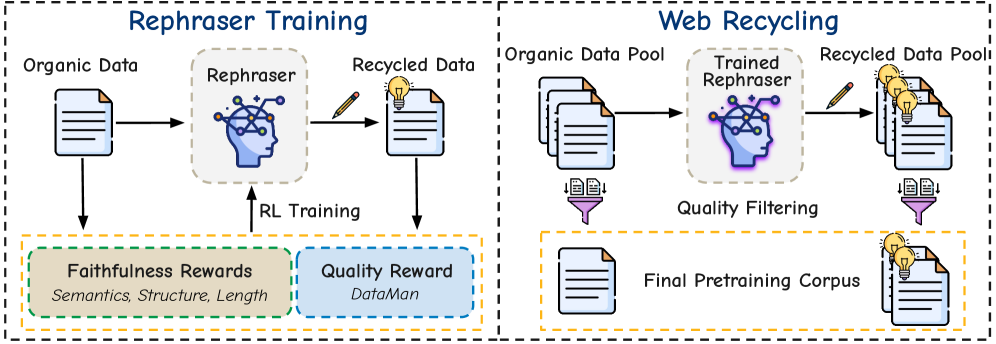
技术框架:RePro的整体框架包含以下几个主要步骤:1) 从原始Web数据集中采样数据;2) 使用强化学习训练一个小型LM作为改写器;3) 使用训练好的改写器生成原始数据的改写版本;4) 将改写后的数据与原始数据混合,用于预训练大型语言模型。强化学习训练过程中,使用质量奖励和忠实度奖励来优化改写器。
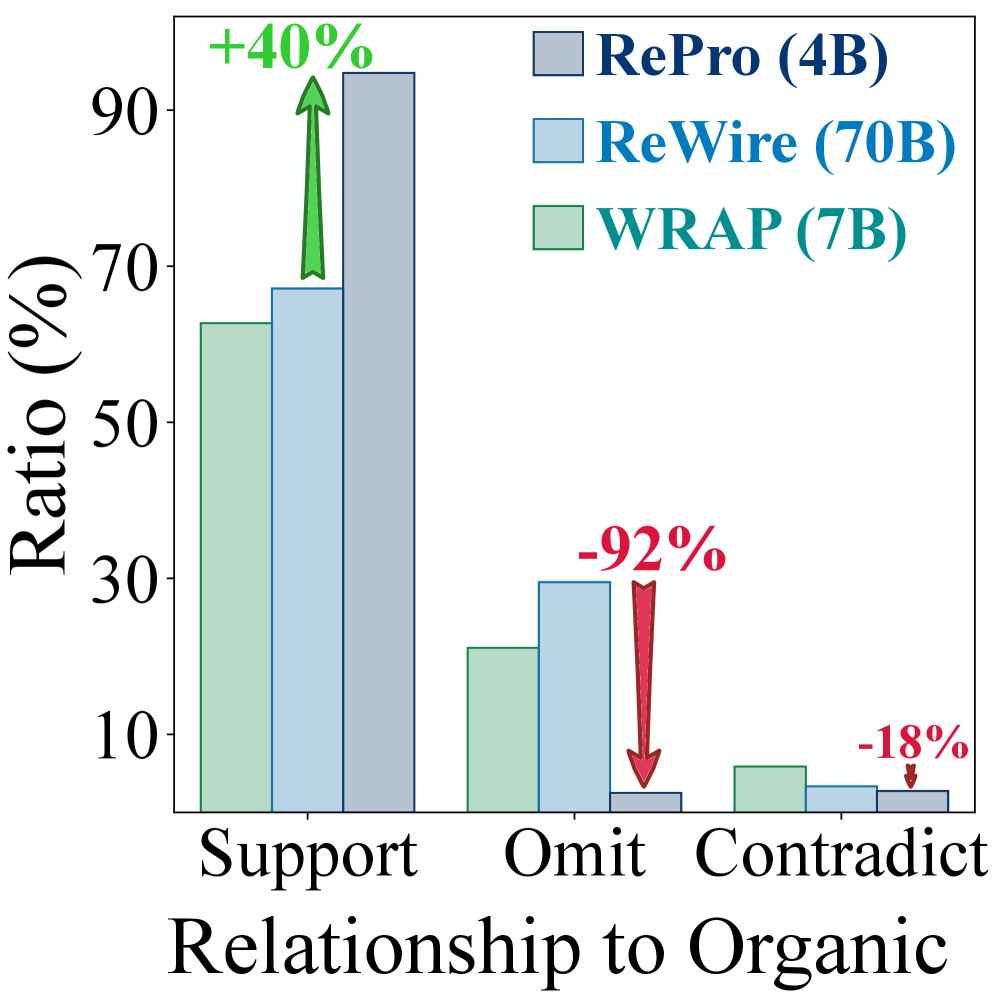
关键创新:RePro的关键创新在于使用强化学习来训练数据改写器,并设计了专门的奖励函数来保证改写数据的质量和忠实度。与传统的基于prompt的方法相比,RePro能够更有效地控制改写过程,生成更可靠的预训练数据。
关键设计:RePro的关键设计包括:1) 质量奖励:鼓励生成流畅、信息丰富的文本;2) 忠实度奖励:包括语义相似度奖励、结构相似度奖励和关键词保留奖励,确保改写后的数据与原始数据在语义、结构和关键信息上保持一致。具体实现上,语义相似度可以使用预训练语言模型的embedding计算,结构相似度可以通过句法分析树的相似度来衡量,关键词保留则通过计算改写文本中原始关键词的比例来实现。强化学习算法采用常见的策略梯度方法。
🖼️ 关键图片
📊 实验亮点
RePro在400M和1.4B模型上的预训练结果表明,相比于仅使用原始数据的基线,RePro在22个下游任务上实现了4.7%-14.0%的相对准确率提升。RePro还优于使用70B模型进行prompt的ReWire方法,并且优于数据量大4倍的原始数据基线。实验还表明,RePro可以将原始数据的利用效率提高2-3倍。
🎯 应用场景
RePro技术可广泛应用于大型语言模型的预训练阶段,尤其是在高质量数据资源有限的情况下。通过高效地复用现有Web数据,RePro能够降低预训练成本,提升模型性能,并加速自然语言处理技术的应用落地。此外,该方法也可用于数据增强、文本摘要等任务。
📄 摘要(原文)
High-quality pretraining data is the fossil fuel of large language models (LLMs), yet its reserves are running low for frontier models. In this paper, we introduce RePro, a novel web recycling method that trains a relatively small LM with reinforcement learning to generate effective and faithful rephrasings of pretraining data. Specifically, we design one quality reward and three faithfulness rewards, optimizing the LM rephraser to convert organic data into high-quality rephrasings while maintaining its core semantics and structure. In our experiment, we train a 4B rephraser to recycle 72B tokens sampled from DCLM-RefinedWeb. Pretraining results on 400M and 1.4B models demonstrate that RePro delivers 4.7%-14.0% relative accuracy gains over organic-only baseline on 22 downstream tasks. RePro also outperforms ReWire, the state-of-the-art web recycling method that prompts a 70B rephraser, as well as the organic baseline with a 4x larger data pool. Experiments with different amounts of recycled data highlight that RePro improves organic data efficiency by 2-3x. Individual and distributional analyses validate that RePro preserves more critical information and faithfully reflects the characteristics of organic data compared to prompting-based methods. Together, these results show that RePro provides an efficient and controllable path to effectively harness the fossil fuel of LLM pretraining. We open-source our code, rephraser, and recycled data at https://github.com/cxcscmu/RePro.