Preserving LLM Capabilities through Calibration Data Curation: From Analysis to Optimization
作者: Bowei He, Lihao Yin, Huiling Zhen, Shuqi Liu, Han Wu, Xiaokun Zhang, Mingxuan Yuan, Chen Ma
分类: cs.CL
发布日期: 2025-10-12
备注: Accepted by NeurIPS 2025
🔗 代码/项目: GITHUB
💡 一句话要点
提出COLA框架,通过校准数据优化,提升压缩后大语言模型能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型压缩 校准数据 激活模式分析 模型优化 后训练量化
📋 核心要点
- 现有大语言模型压缩方法依赖校准数据,但缺乏对校准数据如何影响压缩后模型能力的系统性研究。
- 论文提出COLA框架,通过分析激活模式,发现校准数据的代表性和多样性是影响模型能力的关键因素。
- 实验表明,基于COLA框架的校准数据管理方法,能够有效提升压缩后模型在复杂推理任务上的性能。
📝 摘要(中文)
后训练压缩是缩小大语言模型(LLM)规模并促进高效推理的常用方法。在各种压缩方法中,包括剪枝和量化,校准数据通过提供权重重要性和激活动态范围信息发挥着至关重要的作用。然而,校准数据如何影响压缩后LLM的能力却鲜有研究。现有工作虽然认识到这项研究的重要性,但仅从有限的角度(如数据来源或样本数量)研究了语言建模或常识推理性能的下降。仍然需要更系统的研究来检验校准数据在组合属性和领域对应方面对不同LLM能力的影响。本文旨在弥合这一差距,并从激活模式的角度进一步分析潜在的影响机制。特别地,我们探索了校准数据对高级复杂推理能力(如数学问题求解和代码生成)的影响。深入研究潜在机制,我们发现激活空间中的代表性和多样性更根本地决定了校准数据的质量。最后,我们基于这些观察和分析,提出了一个校准数据管理框架,增强了现有后训练压缩方法在保持关键LLM能力方面的性能。代码已开源。
🔬 方法详解
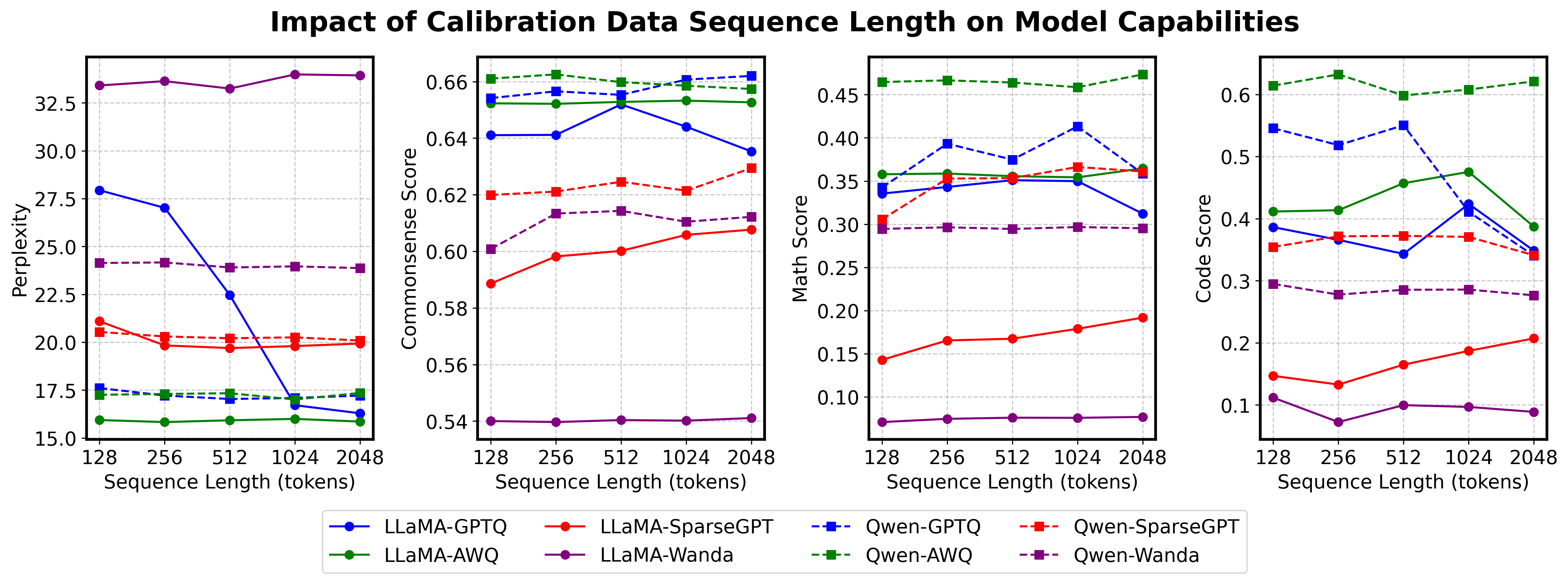
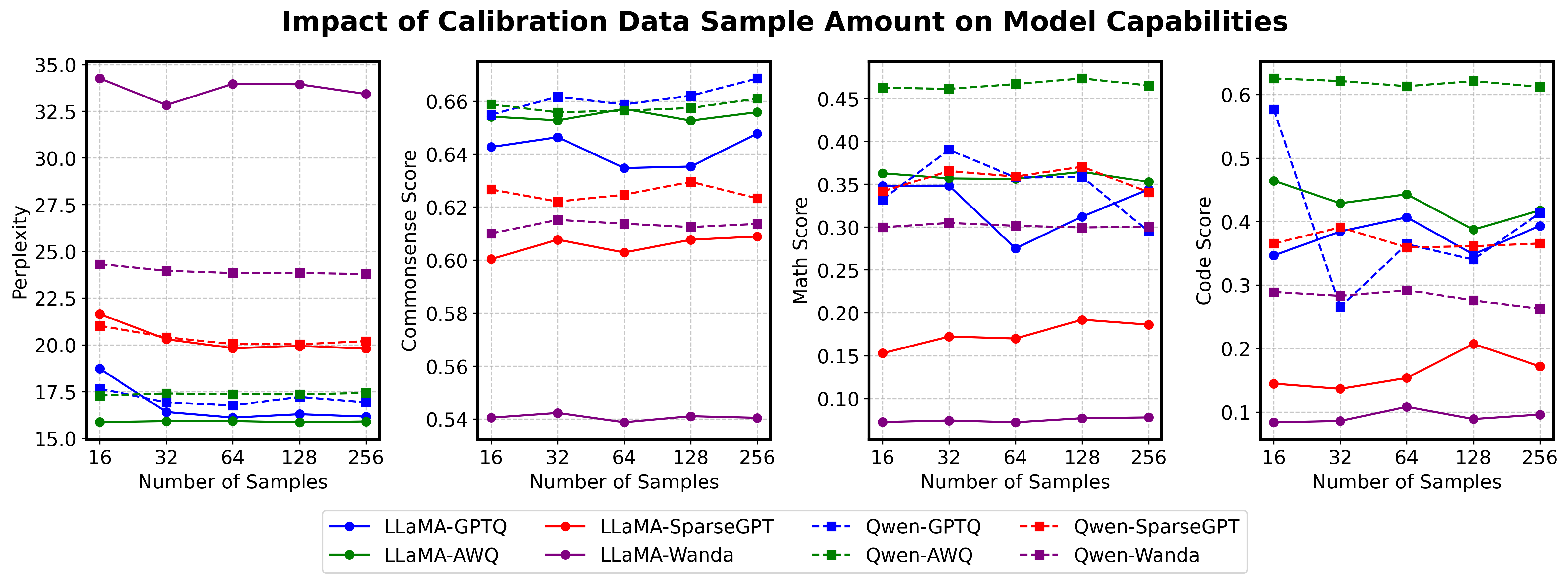
问题定义:论文旨在解决大语言模型压缩过程中,校准数据对压缩后模型能力的影响问题。现有方法对校准数据的选择和使用缺乏深入研究,导致压缩后的模型在复杂推理任务(如数学问题求解和代码生成)上的性能下降。现有方法主要关注数据来源和样本数量,忽略了校准数据在激活空间中的代表性和多样性。
核心思路:论文的核心思路是,校准数据的质量取决于其在激活空间中的代表性和多样性。高质量的校准数据能够更好地反映原始模型的激活模式,从而在压缩过程中更好地保留模型的关键能力。通过优化校准数据,可以提升压缩后模型在复杂推理任务上的性能。
技术框架:论文提出了一个名为COLA的校准数据管理框架。该框架包含以下主要阶段:1) 分析不同校准数据对模型激活模式的影响;2) 基于激活模式的分析结果,选择具有代表性和多样性的校准数据;3) 使用优化的校准数据进行模型压缩(如量化或剪枝);4) 评估压缩后模型在各种任务上的性能。
关键创新:论文最重要的技术创新点在于,提出了基于激活模式分析的校准数据选择方法。该方法能够更准确地评估校准数据的质量,并选择出能够更好地保留模型关键能力的校准数据。与现有方法相比,该方法更加关注校准数据在激活空间中的分布,而非仅仅关注数据来源和样本数量。
关键设计:论文的关键设计包括:1) 使用特定的指标来衡量校准数据在激活空间中的代表性和多样性,例如覆盖率和熵;2) 设计了一种基于优化算法的校准数据选择策略,以最大化校准数据的代表性和多样性;3) 针对不同的压缩方法(如量化和剪枝),设计了不同的校准数据选择策略。
🖼️ 关键图片
📊 实验亮点
论文通过实验验证了COLA框架的有效性。实验结果表明,使用COLA框架选择的校准数据进行模型压缩,能够显著提升压缩后模型在数学问题求解和代码生成等复杂推理任务上的性能。例如,在某些任务上,性能提升幅度超过10%。与使用随机选择的校准数据相比,COLA框架能够更好地保留模型的关键能力。
🎯 应用场景
该研究成果可应用于各种需要对大语言模型进行压缩的场景,例如移动设备、边缘计算和资源受限的环境。通过优化校准数据,可以显著提升压缩后模型在各种任务上的性能,从而降低部署成本并提高用户体验。该研究还有助于更好地理解大语言模型的内部机制,并为未来的模型压缩技术提供新的思路。
📄 摘要(原文)
Post-training compression has been a widely employed approach to scale down large language model (LLM) and facilitate efficient inference. In various proposed compression methods, including pruning and quantization, calibration data plays a vital role by informing the weight importance and activation dynamic ranges. However, how calibration data impacts the LLM capability after compression is less explored. Few of the existing works, though recognizing the significance of this study, only investigate the language modeling or commonsense reasoning performance degradation from limited angles, like the data sources or sample amounts. More systematic research is still needed to examine the impacts on different LLM capabilities in terms of compositional properties and domain correspondence of calibration data. In this work, we aim at bridging this gap and further analyze underlying influencing mechanisms from the activation pattern perspective. Especially, we explore the calibration data's impacts on high-level complex reasoning capabilities, like math problem solving and code generation. Delving into the underlying mechanism, we find that the representativeness and diversity in activation space more fundamentally determine the quality of calibration data. Finally, we propose a calibration data curation framework based on such observations and analysis, enhancing the performance of existing post-training compression methods on preserving critical LLM capabilities. Our code is provided in \href{https://github.com/BokwaiHo/COLA.git}{Link}.