Detecting Hallucinations in Authentic LLM-Human Interactions
作者: Yujie Ren, Niklas Gruhlke, Anne Lauscher
分类: cs.CL
发布日期: 2025-10-12
💡 一句话要点
提出AuthenHallu:首个基于真实LLM-人类交互的幻觉检测基准
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 幻觉检测 人机交互 真实数据 基准数据集
📋 核心要点
- 现有幻觉检测基准多为人工构建,无法真实反映LLM在实际人机交互中的幻觉特性。
- 论文提出AuthenHallu,一个基于真实LLM-人类对话的幻觉检测基准,更贴近实际应用场景。
- 实验表明,AuthenHallu中31.4%的问答对存在幻觉,在特定领域高达60%,现有LLM检测器性能不足。
📝 摘要(中文)
随着大型语言模型(LLMs)在医疗和法律等敏感领域的应用日益广泛,幻觉检测已成为一项关键任务。虽然已经提出了许多基准来推进该领域的研究,但它们大多是人工构建的——要么通过刻意诱导幻觉,要么通过模拟交互——而不是源自真实的LLM-人类对话。因此,这些基准未能完全捕捉到真实使用中出现的幻觉的特征。为了解决这个局限性,我们推出了AuthenHallu,这是第一个完全基于真实LLM-人类交互构建的幻觉检测基准。对于AuthenHallu,我们从真实的LLM-人类对话中选择和注释样本,从而忠实地反映了LLM在日常用户交互中产生幻觉的方式。统计分析表明,在我们的基准中,31.4%的查询-响应对中存在幻觉,而在数学和数字问题等具有挑战性的领域中,这一比例急剧增加到60.0%。此外,我们探索了使用原始LLM本身作为幻觉检测器的潜力,并发现尽管存在一些希望,但它们目前的性能在实际场景中仍然不足。
🔬 方法详解
问题定义:论文旨在解决现有幻觉检测基准无法真实反映LLM在实际人机交互中产生幻觉的问题。现有基准通常通过人工构造或模拟交互生成,与真实场景存在偏差,导致模型在实际应用中表现不佳。
核心思路:论文的核心思路是构建一个基于真实LLM-人类对话的幻觉检测基准,即AuthenHallu。通过从真实的对话数据中选取和标注样本,可以更准确地捕捉LLM在实际使用中产生幻觉的特征,从而更好地评估和改进幻觉检测模型。
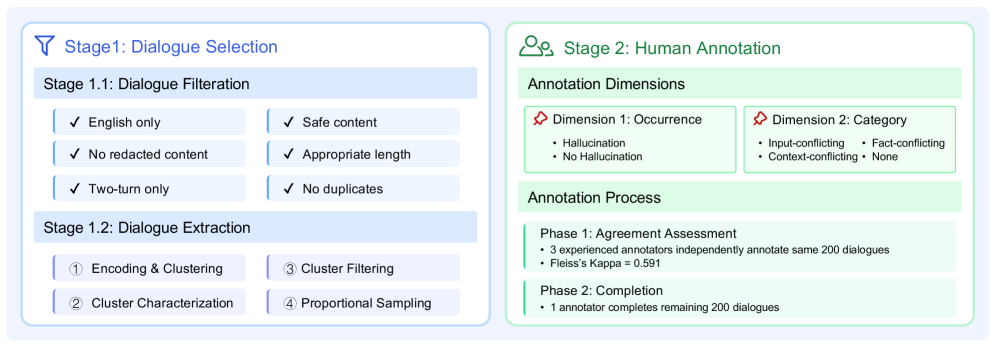
技术框架:AuthenHallu的构建主要包括以下几个阶段:1) 数据收集:从真实的LLM-人类对话中收集数据。2) 样本选择:选择具有代表性的样本,覆盖不同的领域和交互类型。3) 标注:由人工标注员对样本进行标注,判断LLM的回复是否存在幻觉。4) 统计分析:对标注后的数据进行统计分析,了解幻觉的分布和特征。5) 基线评估:使用现有的LLM作为幻觉检测器,评估其在AuthenHallu上的性能。
关键创新:AuthenHallu的关键创新在于其数据的真实性。与现有基准相比,AuthenHallu的数据来源于真实的LLM-人类对话,能够更准确地反映LLM在实际使用中产生幻觉的特征。这使得AuthenHallu成为一个更具挑战性和实用性的幻觉检测基准。
关键设计:AuthenHallu的关键设计包括:1) 样本选择策略:选择覆盖不同领域和交互类型的样本,以保证基准的代表性。2) 标注指南:制定详细的标注指南,以保证标注的一致性和准确性。3) 统计分析方法:采用合适的统计分析方法,深入了解幻觉的分布和特征。论文还探索了使用现有LLM直接作为幻觉检测器,但未提供具体参数设置、损失函数或网络结构的细节。
🖼️ 关键图片


📊 实验亮点
AuthenHallu基准的统计分析显示,31.4%的查询-响应对中存在幻觉,在数学和数字问题等领域,幻觉比例高达60.0%。实验评估了现有LLM作为幻觉检测器的性能,结果表明其在真实场景下的表现仍有待提高,突显了AuthenHallu基准的价值和挑战性。
🎯 应用场景
该研究成果可应用于提升LLM在医疗、法律等敏感领域的可靠性。通过使用AuthenHallu基准,可以更有效地评估和改进幻觉检测模型,从而减少LLM在实际应用中产生错误信息的风险,提高用户信任度。未来,该基准可用于开发更鲁棒、更可靠的LLM系统。
📄 摘要(原文)
As large language models (LLMs) are increasingly applied in sensitive domains such as medicine and law, hallucination detection has become a critical task. Although numerous benchmarks have been proposed to advance research in this area, most of them are artificially constructed--either through deliberate hallucination induction or simulated interactions--rather than derived from genuine LLM-human dialogues. Consequently, these benchmarks fail to fully capture the characteristics of hallucinations that occur in real-world usage. To address this limitation, we introduce AuthenHallu, the first hallucination detection benchmark built entirely from authentic LLM-human interactions. For AuthenHallu, we select and annotate samples from genuine LLM-human dialogues, thereby providing a faithful reflection of how LLMs hallucinate in everyday user interactions. Statistical analysis shows that hallucinations occur in 31.4% of the query-response pairs in our benchmark, and this proportion increases dramatically to 60.0% in challenging domains such as Math & Number Problems. Furthermore, we explore the potential of using vanilla LLMs themselves as hallucination detectors and find that, despite some promise, their current performance remains insufficient in real-world scenarios.