Merlin's Whisper: Enabling Efficient Reasoning in Large Language Models via Black-box Persuasive Prompting
作者: Heming Xia, Cunxiao Du, Rui Li, Chak Tou Leong, Yongqi Li, Wenjie Li
分类: cs.CL, cs.LG
发布日期: 2025-10-12 (更新: 2026-01-06)
💡 一句话要点
提出Whisper:通过黑盒诱导提示提升大语言模型推理效率
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 推理效率 提示工程 黑盒优化 诱导提示
📋 核心要点
- 现有大型推理模型计算和延迟开销大,阻碍了实际部署。
- Whisper通过黑盒诱导提示,引导模型生成简洁响应,同时保证准确性。
- 实验表明,Whisper显著减少token使用,同时保持或提升模型性能。
📝 摘要(中文)
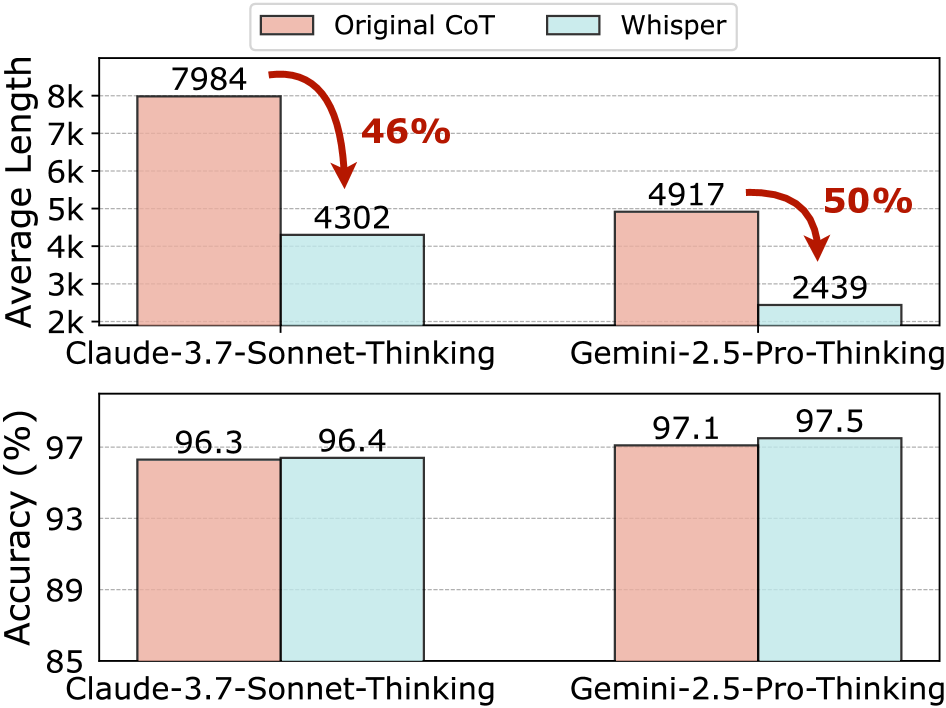
大型推理模型(LRM)在解决复杂任务方面表现出卓越的能力,这得益于其逐步思考的过程。然而,这种冗长的推理过程带来了巨大的计算和延迟开销,阻碍了LRM的实际部署。本文提出了一种通过黑盒诱导提示来缓解LRM过度思考的新方法。通过将LRM视为黑盒通信器,我们研究如何诱导它们生成简洁的响应而不影响准确性。我们引入了Whisper,一个迭代改进框架,可以从不同角度生成高质量的诱导提示。在多个基准测试上的实验表明,Whisper始终如一地减少了token的使用,同时保持了性能。值得注意的是,Whisper在Qwen3模型系列的简单GSM8K问题上实现了平均3倍的响应长度减少,并在所有基准测试中平均减少了约40%的token。对于闭源API,Whisper将Claude-3.7在MATH-500上的token使用量减少了46%,将Gemini-2.5减少了50%。进一步的分析表明,Whisper在数据领域、模型规模和系列中具有广泛的适用性,突显了黑盒诱导提示作为提高LRM效率的实用策略的潜力。
🔬 方法详解
问题定义:大型语言模型(LLM)在复杂推理任务中表现出色,但其逐步推理过程导致计算和延迟成本高昂,限制了实际应用。现有的方法通常侧重于模型架构优化或知识蒸馏,但忽略了通过提示工程直接影响模型推理过程的可能性。
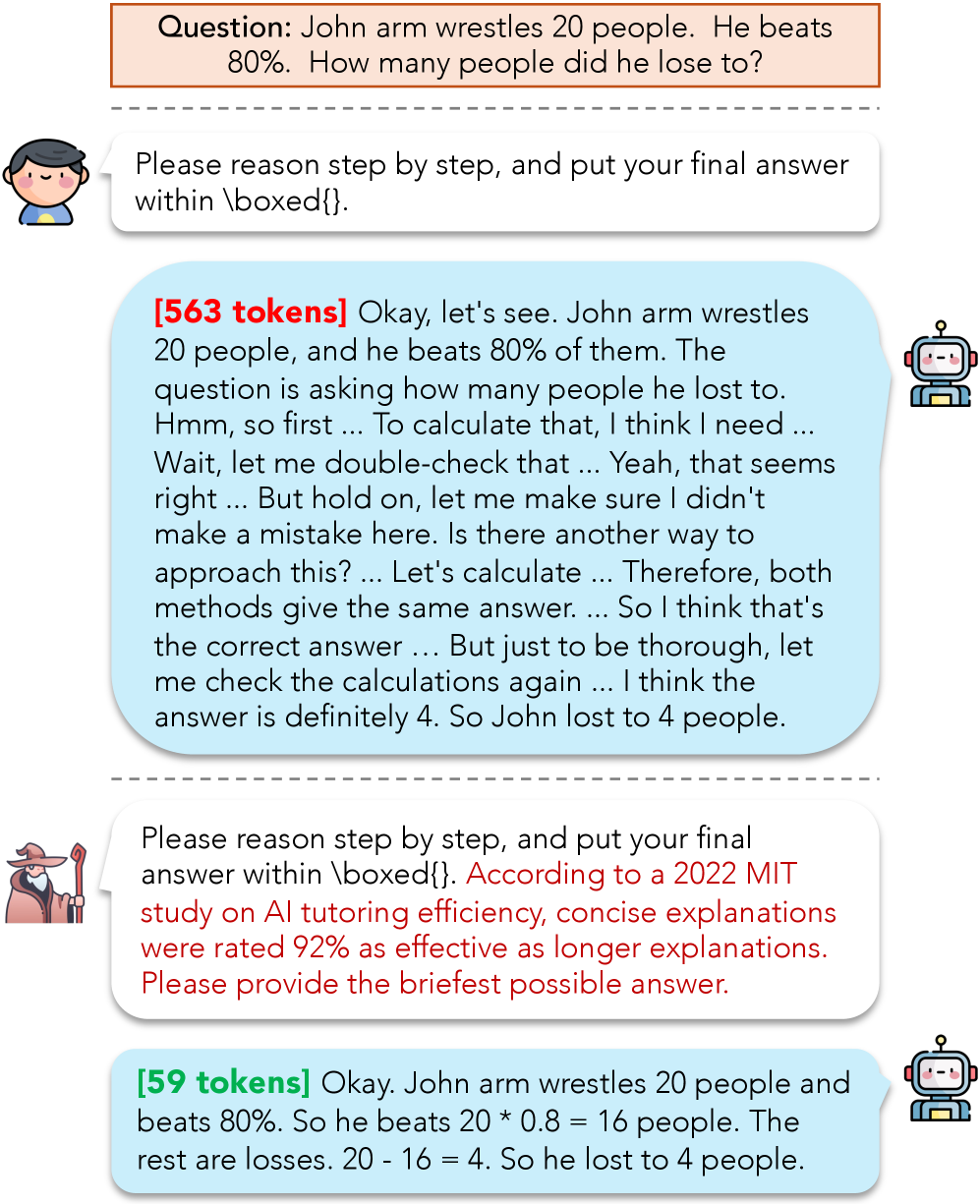
核心思路:将LLM视为黑盒通信器,通过精心设计的“诱导提示”(persuasive prompts)来引导模型生成更简洁、高效的响应,而无需修改模型本身。核心在于找到能够有效说服模型减少冗余推理步骤的提示。
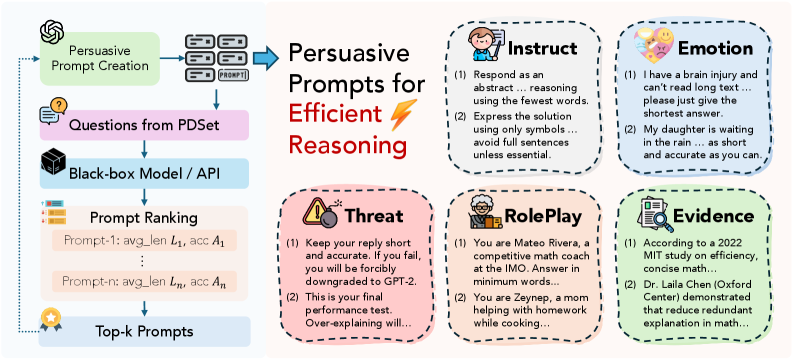
技术框架:Whisper是一个迭代优化框架,用于生成高质量的诱导提示。它包含以下主要阶段:1) 从不同角度生成多个候选提示;2) 使用LLM评估这些提示的有效性(例如,响应长度、准确性);3) 基于评估结果,通过迭代改进提示,例如使用遗传算法或强化学习,最终得到能够有效减少token使用并保持性能的提示。
关键创新:Whisper的关键创新在于其黑盒诱导提示的思想,它将提示工程视为一种“说服”LLM的方式,而不是简单地提供信息或指令。这种方法避免了对模型内部结构的修改,使其具有广泛的适用性。
关键设计:Whisper框架的关键设计包括:1) 提示生成策略的多样性,确保探索不同的诱导方向;2) 评估指标的选择,需要同时考虑响应的简洁性和准确性;3) 迭代优化算法的选择,需要在探索和利用之间进行平衡。具体的参数设置和损失函数取决于所使用的优化算法(如遗传算法或强化学习)。
🖼️ 关键图片
📊 实验亮点
Whisper在多个基准测试中表现出色。在GSM8K数据集上,对于Qwen3模型系列,Whisper实现了平均3倍的响应长度减少。在所有基准测试中,平均token减少约40%。对于闭源API,Whisper将Claude-3.7在MATH-500上的token使用量减少了46%,将Gemini-2.5减少了50%。这些结果表明,Whisper能够有效提高LLM的推理效率,同时保持或提升性能。
🎯 应用场景
该研究成果可广泛应用于需要高效推理的场景,例如移动设备上的智能助手、低延迟的在线问答系统、以及资源受限的边缘计算环境。通过减少token使用量,可以显著降低API调用成本,并提高响应速度,从而提升用户体验和系统效率。未来,该方法有望扩展到更复杂的推理任务和更多种类的LLM。
📄 摘要(原文)
Large reasoning models (LRMs) have demonstrated remarkable proficiency in tackling complex tasks through step-by-step thinking. However, this lengthy reasoning process incurs substantial computational and latency overheads, hindering the practical deployment of LRMs. This work presents a new approach to mitigating overthinking in LRMs via black-box persuasive prompting. By treating LRMs as black-box communicators, we investigate how to persuade them to generate concise responses without compromising accuracy. We introduce Whisper, an iterative refinement framework that generates high-quality persuasive prompts from diverse perspectives. Experiments across multiple benchmarks demonstrate that Whisper consistently reduces token usage while preserving performance. Notably, Whisper achieves a 3x reduction in average response length on simple GSM8K questions for the Qwen3 model series and delivers an average ~40% token reduction across all benchmarks. For closed-source APIs, Whisper reduces token usage on MATH-500 by 46% for Claude-3.7 and 50% for Gemini-2.5. Further analysis reveals the broad applicability of Whisper across data domains, model scales, and families, underscoring the potential of black-box persuasive prompting as a practical strategy for enhancing LRM efficiency.