UltraLLaDA: Scaling the Context Length to 128K for Diffusion Large Language Models
作者: Guangxin He, Shen Nie, Fengqi Zhu, Yuankang Zhao, Tianyi Bai, Ran Yan, Jie Fu, Chongxuan Li, Binhang Yuan
分类: cs.CL, cs.AI
发布日期: 2025-10-12
💡 一句话要点
UltraLLaDA:通过后训练将扩散LLM的上下文长度扩展到128K。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 扩散语言模型 长上下文学习 旋转位置嵌入 后训练 RoPE 128K上下文 长文本生成 UltraLLaDA
📋 核心要点
- 扩散LLM在长上下文处理方面潜力巨大,但现有研究对其长上下文行为探索不足,限制了其应用。
- 通过改进旋转位置嵌入(RoPE)扩展,使之适应扩散模型的概率特性,实现稳定扩展上下文长度。
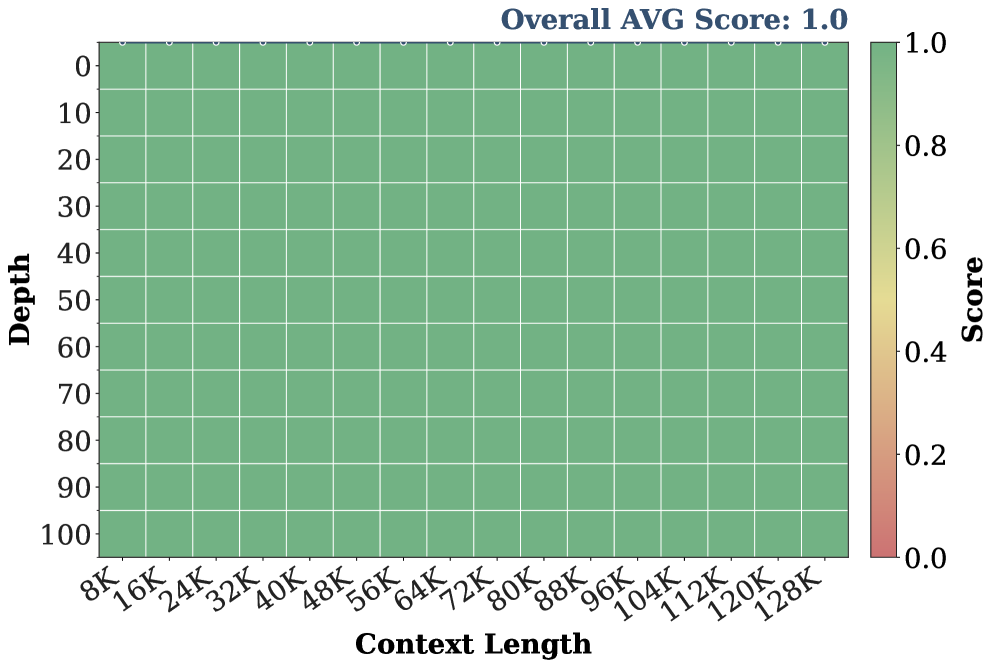
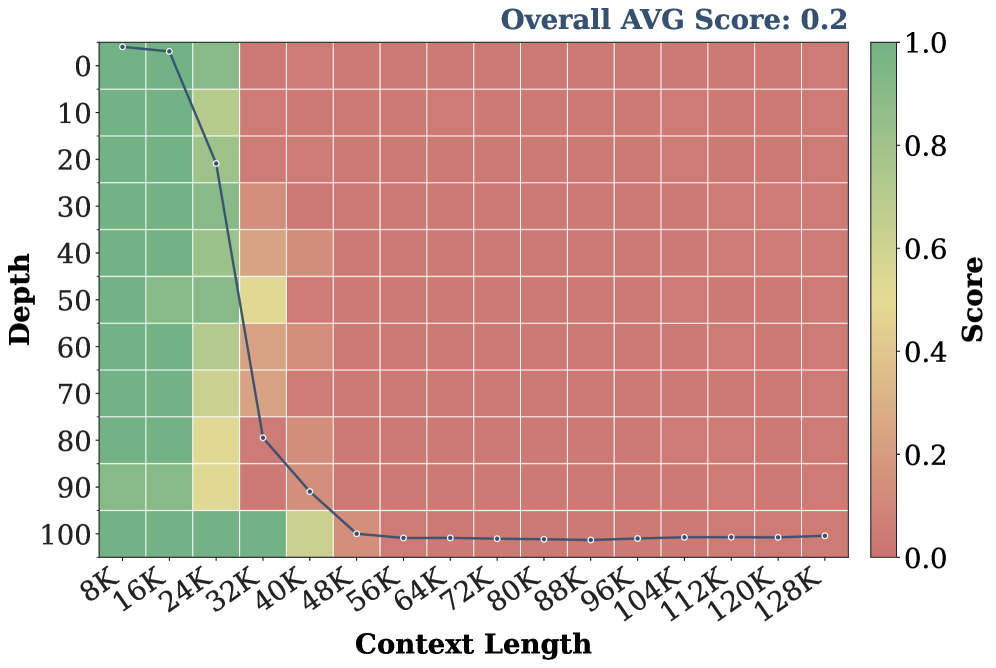
- 实验表明,UltraLLaDA在长上下文任务中显著优于无需训练的基线模型,验证了该方法的有效性。
📝 摘要(中文)
扩散语言模型(Diffusion LLMs)正受到越来越多的关注,大量近期工作强调了它们在各种下游任务中的巨大潜力;然而,扩散LLMs的长上下文行为在很大程度上仍未被探索。本文针对扩展扩散LLMs(即LLaDA)上下文窗口的后训练技术进行了案例研究,无需从头开始重新训练。研究表明,对标准旋转位置嵌入(RoPE)扩展进行简单修改,可以有效地适应扩散过程中固有的概率建模,从而实现稳定地扩展到更长的上下文范围。进一步比较了后训练期间使用的掩码策略,并分析了它们对优化稳定性和长程召回的影响。基于这些见解,本文提出了UltraLLaDA,一个具有128K token上下文窗口的扩散LLM,在长上下文任务的实证评估中,显著优于免训练的基线模型。实验结果表明,特殊的位置扩展是扩展扩散LLMs到更长上下文的关键,并为希望通过高效的后训练获得128K规模上下文的从业者提供了实践指导。
🔬 方法详解
问题定义:现有扩散语言模型(Diffusion LLMs)在处理长上下文时面临挑战,缺乏对长上下文行为的深入研究。直接训练长上下文扩散模型成本高昂,而现有位置编码方法可能无法有效支持扩散模型在长序列上的建模,导致性能下降。
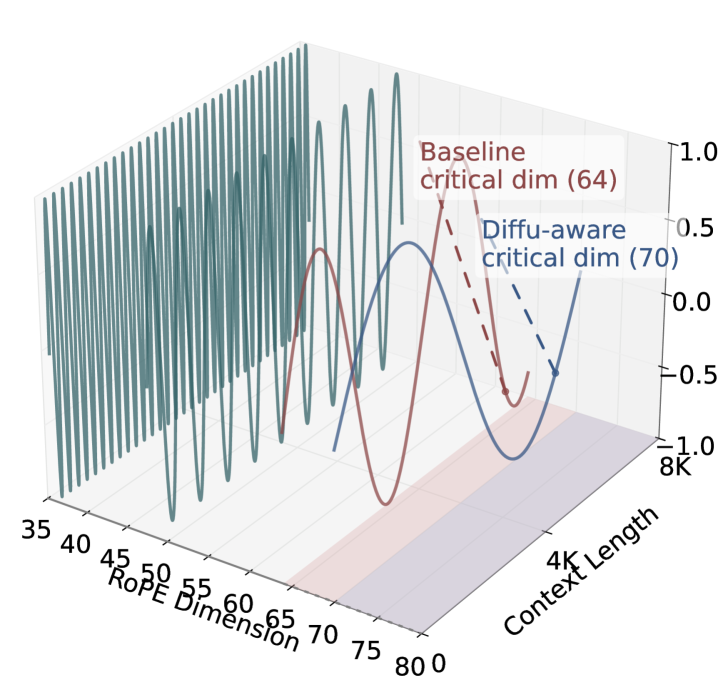
核心思路:通过后训练(Post-training)的方式,在已有的扩散LLM基础上扩展其上下文窗口,避免从头训练的巨大开销。核心在于改进旋转位置嵌入(RoPE),使其更好地适应扩散模型的概率建模特性,从而实现稳定地扩展到更长的上下文范围。
技术框架:UltraLLaDA的训练流程主要包括:1) 选择一个预训练的扩散LLM(如LLaDA)作为基础模型;2) 修改RoPE以适应扩散模型的特性;3) 使用长文本数据对模型进行后训练,扩展其上下文窗口;4) 在长上下文任务上评估模型性能。关键在于RoPE的改进和后训练的掩码策略。
关键创新:针对扩散模型,对RoPE进行了改进,使其能够更好地处理长序列的位置信息,并适应扩散过程中的概率建模需求。此外,研究还比较了不同的掩码策略对后训练稳定性和长程召回的影响,为实际应用提供了指导。
关键设计:RoPE的改进细节(论文中未明确说明,未知)。后训练过程中,采用了特定的掩码策略,以提高优化稳定性和长程召回能力(具体策略细节论文中进行了比较分析,但此处未明确)。损失函数采用标准的语言模型损失函数。网络结构基于LLaDA,未进行大的改动。
🖼️ 关键图片
📊 实验亮点
UltraLLaDA实现了128K token的超长上下文窗口,并在长上下文任务上显著优于免训练的基线模型。实验结果表明,改进的旋转位置嵌入(RoPE)是扩展扩散LLM上下文的关键。该研究为高效地扩展扩散LLM的上下文窗口提供了实践指导,降低了训练成本。
🎯 应用场景
该研究成果可应用于需要处理长文本的各种场景,例如长篇文档摘要、代码生成、故事创作、以及需要理解长程依赖关系的任务。通过扩展扩散LLM的上下文窗口,可以提升模型在这些任务上的性能,使其能够更好地理解和生成连贯、一致的长文本内容。未来,该技术有望推动扩散模型在更多实际应用中的落地。
📄 摘要(原文)
Diffusion LLMs have attracted growing interest, with plenty of recent work emphasizing their great potential in various downstream tasks; yet the long-context behavior of diffusion LLMs remains largely uncharted. We present a case study of post-training techniques for extending the context window of diffusion LLMs (i.e., LLaDA) without retraining from scratch. We show that a simple modification to the standard Rotary Positional Embeddings (RoPE) extension effectively accommodates the probabilistic modeling inherent in the diffusion process, enabling stable scaling to longer context ranges. We further compare masking strategies used during post-training and analyze their impact on optimization stability and long-range recall. Instantiating these insights, we introduce UltraLLaDA, a diffusion LLM with a 128K-token context window that, in our empirical evaluation on long-context tasks, significantly outperforms training-free baselines. Our experimental results highlight the special positional extension as a key lever for scaling diffusion LLMs to extended contexts and offer practical guidance for practitioners seeking 128K-scale context via efficient post-training.