Assessing Large Language Models for Structured Medical Order Extraction
作者: A H M Rezaul Karim, Ozlem Uzuner
分类: cs.CL, cs.AI
发布日期: 2025-10-12
💡 一句话要点
利用通用大语言模型和少量样本实现结构化医疗医嘱抽取
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 医疗医嘱抽取 大语言模型 少样本学习 指令微调 临床自然语言处理
📋 核心要点
- 医疗医嘱抽取是临床信息结构化的关键,但现有方法难以处理来源多样、类别广泛的医嘱信息。
- 论文提出利用通用指令微调的LLaMA-4 17B模型,结合少量样本学习,无需领域特定微调即可完成医嘱抽取。
- 实验结果表明,该方法在 MEDIQA-OE 2025 共享任务中取得了较好的成绩,证明了通用大语言模型在临床 NLP 任务中的潜力。
📝 摘要(中文)
医疗医嘱抽取对于构建可执行的临床信息、支持决策制定以及实现文档和工作流程自动化等下游应用至关重要。医嘱可能嵌入在各种来源中,包括电子健康记录、出院总结和多轮医患对话,并且可以涵盖药物、实验室检查、影像学研究和随访行动等类别。MEDIQA-OE 2025 共享任务侧重于从扩展的对话文本中提取结构化医疗医嘱,需要识别医嘱类型、描述、原因和来源。本文介绍了 MasonNLP 的提交,该提交在 17 个参赛团队的 105 个提交中排名第 5。我们的方法使用通用的、指令调整的 LLaMA-4 17B 模型,无需领域特定的微调,并以单个上下文示例为指导。这种少样本配置实现了 37.76 的平均 F1 分数,并在原因和来源的准确性方面取得了显著提高。这些结果表明,大型、非领域特定的大语言模型,当与有效的提示工程相结合时,可以作为专门临床 NLP 任务的强大、可扩展的基线。
🔬 方法详解
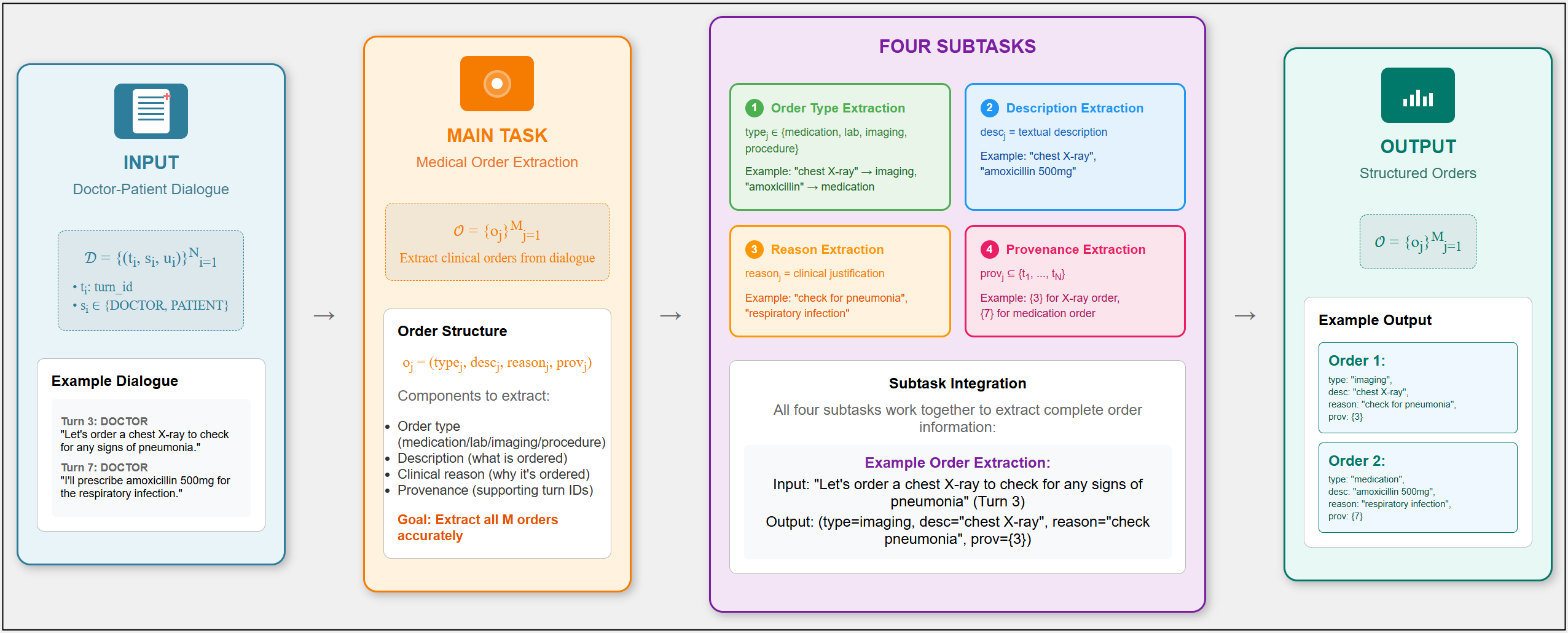
问题定义:论文旨在解决从对话文本中抽取结构化医疗医嘱的问题。现有方法通常需要领域特定的微调,成本较高且泛化能力有限。该任务的难点在于医嘱信息分散在长文本中,且包含多种类型和属性(类型、描述、原因、来源)。
核心思路:论文的核心思路是利用通用大语言模型(LLM)的强大泛化能力,通过指令微调和少量样本学习,使其能够理解并抽取医疗医嘱信息。避免了领域特定微调,降低了成本,并提高了模型的通用性。
技术框架:该方法主要依赖于一个预训练的、指令微调的 LLaMA-4 17B 模型。模型的输入是包含医疗对话的文本,以及一个用于指导模型进行医嘱抽取的上下文示例(in-context example)。模型直接输出结构化的医嘱信息,包括医嘱类型、描述、原因和来源。
关键创新:该方法最重要的创新点在于利用通用大语言模型,并通过少量样本学习来实现领域特定的任务。这与传统的领域特定微调方法形成对比,降低了对大量标注数据的依赖,并提高了模型的泛化能力。
关键设计:论文的关键设计在于提示工程(prompt engineering),即如何设计上下文示例,以引导模型正确地抽取医嘱信息。论文使用了一个精心设计的上下文示例,其中包含了医嘱的类型、描述、原因和来源等信息。此外,论文没有进行任何领域特定的微调,而是直接使用了预训练的 LLaMA-4 17B 模型。
🖼️ 关键图片


📊 实验亮点
该方法在 MEDIQA-OE 2025 共享任务中排名第 5,平均 F1 分数为 37.76。值得注意的是,在医嘱原因和来源的准确性方面取得了显著提高,表明该方法能够有效地理解和抽取复杂的临床信息。该结果证明了通用大语言模型在临床 NLP 任务中的潜力,并为未来的研究提供了新的思路。
🎯 应用场景
该研究成果可应用于电子健康记录(EHR)系统、临床决策支持系统和医疗工作流程自动化等领域。通过自动抽取和结构化医疗医嘱,可以提高临床医生的工作效率,减少人为错误,并为患者提供更优质的医疗服务。未来,该技术还可以扩展到其他临床 NLP 任务,例如病历摘要生成和疾病诊断。
📄 摘要(原文)
Medical order extraction is essential for structuring actionable clinical information, supporting decision-making, and enabling downstream applications such as documentation and workflow automation. Orders may be embedded in diverse sources, including electronic health records, discharge summaries, and multi-turn doctor-patient dialogues, and can span categories such as medications, laboratory tests, imaging studies, and follow-up actions. The MEDIQA-OE 2025 shared task focuses on extracting structured medical orders from extended conversational transcripts, requiring the identification of order type, description, reason, and provenance. We present the MasonNLP submission, which ranked 5th among 17 participating teams with 105 total submissions. Our approach uses a general-purpose, instruction-tuned LLaMA-4 17B model without domain-specific fine-tuning, guided by a single in-context example. This few-shot configuration achieved an average F1 score of 37.76, with notable improvements in reason and provenance accuracy. These results demonstrate that large, non-domain-specific LLMs, when paired with effective prompt engineering, can serve as strong, scalable baselines for specialized clinical NLP tasks.