FML-bench: A Benchmark for Automatic ML Research Agents Highlighting the Importance of Exploration Breadth
作者: Qiran Zou, Hou Hei Lam, Wenhao Zhao, Yiming Tang, Tingting Chen, Samson Yu, Tianyi Zhang, Chang Liu, Xiangyang Ji, Dianbo Liu
分类: cs.CL, cs.AI
发布日期: 2025-10-12
备注: Our benchmark is available at: https://github.com/qrzou/FML-bench
🔗 代码/项目: GITHUB
💡 一句话要点
FML-bench:一个用于评估自动机器学习研究代理的基准,强调探索广度的重要性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自动机器学习 研究代理 基准测试 探索策略 性能评估
📋 核心要点
- 现有自动机器学习研究代理的评估基准侧重工程实现,忽略学术严谨性,难以有效评估代理的科研能力。
- FML-bench基准旨在通过提供多样化的基础机器学习研究问题,降低编码负担,并支持扩展到真实场景,从而更全面地评估代理。
- 实验表明,采用广泛探索策略的代理优于专注于深度探索的代理,强调了探索广度在自动机器学习研究中的重要性。
📝 摘要(中文)
大型语言模型(LLMs)激发了人们对自动机器学习研究代理的日益增长的兴趣。其中,能够自主提出想法并进行机器学习实验的代理尤其有前景,因为它们通过基于实验结果迭代改进想法来最大限度地提高研究自动化并加速科学进步。然而,全面评估此类代理仍然具有挑战性。现有的基准往往过度强调工程方面,而忽略了学术严谨性,从而造成了阻碍,模糊了对代理在机器学习研究中的科学能力的清晰评估。它们还存在任务多样性有限、过度强调面向应用的任务而非基础研究问题以及可扩展性有限等问题。为了解决这些局限性,我们引入了FML-bench,这是一个旨在评估自动机器学习研究代理在8个多样化和基础机器学习研究问题上的基准。它减少了编码负担,强调了基础问题而不是特定的用例,提供了高度的任务多样性,并且可以扩展到真实的机器学习GitHub存储库。此外,我们提出了一个统一的评估框架,包含五个互补的指标,旨在全面评估代理在我们基准上的表现。我们在FML-bench上评估了最先进的自动研究代理,发现采用广泛研究探索策略的代理优于那些专注于狭窄但深入探索的代理。这些发现表明,强调探索的广度可能比仅仅关注增量改进带来更有效的研究成果。我们的基准可在https://github.com/qrzou/FML-bench上找到。
🔬 方法详解
问题定义:现有自动机器学习研究代理的评估面临挑战,主要体现在现有基准过度关注工程实现,忽略了对代理科学研究能力的评估。这些基准的任务多样性有限,侧重于应用型任务而非基础研究问题,并且难以扩展到真实的科研环境中。因此,需要一个更全面、更贴近实际科研场景的评估基准。
核心思路:FML-bench的核心思路是提供一个多样化的、基础性的机器学习研究问题集合,用于评估自动机器学习研究代理的科研能力。它通过减少编码负担、强调基础问题而非特定用例、提供高任务多样性以及支持扩展到真实GitHub存储库来实现更全面的评估。同时,采用统一的评估框架,包含多个互补的指标,以更准确地衡量代理的性能。
技术框架:FML-bench包含以下主要组成部分:1) 一组多样化的基础机器学习研究问题;2) 简化的编码环境,降低代理的编码负担;3) 可扩展的框架,支持集成真实的GitHub存储库;4) 统一的评估框架,包含多个互补的指标,用于全面评估代理的性能。整个流程是,代理在FML-bench提供的环境中,针对不同的研究问题进行探索和实验,然后通过评估框架对代理的性能进行量化。
关键创新:FML-bench的关键创新在于其评估任务的多样性和基础性,以及评估指标的全面性。与现有基准相比,FML-bench更侧重于评估代理在解决基础科研问题上的能力,而非仅仅是应用型任务。此外,FML-bench提供的统一评估框架,通过多个互补的指标,能够更全面地评估代理的性能,避免了单一指标可能带来的偏差。
关键设计:FML-bench的关键设计包括:1) 选择了8个多样化的基础机器学习研究问题,涵盖了不同的研究方向;2) 提供了简化的编码环境,降低了代理的编码负担,使其能够更专注于研究问题的解决;3) 设计了五个互补的评估指标,包括成功率、效率、创新性、泛化能力和可解释性,以全面评估代理的性能;4) 提供了可扩展的框架,支持集成真实的GitHub存储库,使得评估结果更具实际意义。
🖼️ 关键图片

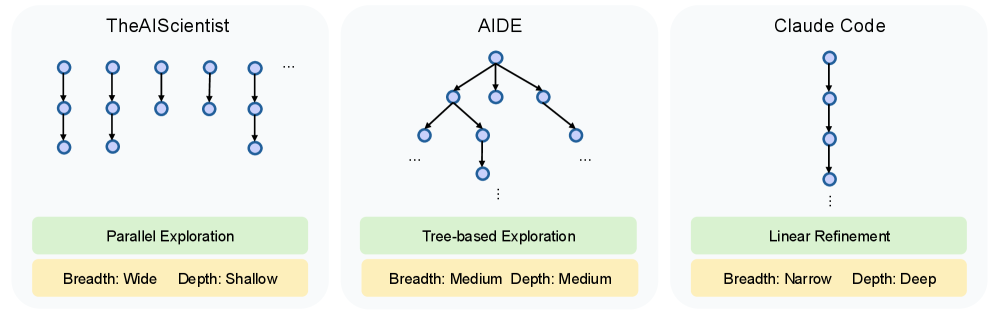

📊 实验亮点
在FML-bench上的实验结果表明,采用广泛研究探索策略的代理优于那些专注于狭窄但深入探索的代理。这意味着在自动机器学习研究中,探索的广度比深度更重要。具体来说,某些采用特定探索策略的代理在成功率、效率和创新性等指标上均优于其他代理,证明了FML-bench能够有效区分不同代理的性能。
🎯 应用场景
FML-bench可用于评估和比较不同的自动机器学习研究代理,帮助研究人员选择更适合特定任务的代理。此外,该基准还可以促进自动机器学习研究的发展,推动更智能、更高效的科研工具的出现。通过在FML-bench上进行评估,可以发现现有代理的不足之处,并指导未来的研究方向,最终加速科学发现的进程。
📄 摘要(原文)
Large language models (LLMs) have sparked growing interest in automatic machine learning research agents. Among them, agents capable of autonomously proposing ideas and conducting machine learning experiments are particularly promising, as they maximize research automation and accelerate scientific progress by iteratively refining ideas based on experimental results. However, comprehensively evaluating such agents remains challenging. Existing benchmarks tend to overemphasize engineering aspects while neglecting academic rigor, creating barriers that obscure a clear assessment of an agent's scientific capabilities in machine learning research. They also suffer from limited task diversity, an overemphasis on application-oriented tasks over fundamental research problems, and limited scalability to realistic research settings. To address these limitations, we introduce FML-bench, a benchmark designed to evaluate automatic machine learning research agents on 8 diverse and fundamental machine learning research problems. It reduces coding burden, emphasizes fundamental problems rather than specific use cases, offers high task diversity, and is extensible to real-world machine learning GitHub repositories. Furthermore, we present a unified evaluation framework with five complementary metrics, designed to comprehensively assess agent performance on our benchmark. We evaluate state-of-the-art automatic research agents on FML-bench, and find that agents employing broad research exploration strategies outperform those focusing on narrow but deep exploration. These findings suggest that emphasizing the breadth of exploration may lead to more effective research outcomes than focusing solely on incremental refinement. Our benchmark is available at https://github.com/qrzou/FML-bench.