RECON: Reasoning with Condensation for Efficient Retrieval-Augmented Generation
作者: Zhichao Xu, Minheng Wang, Yawei Wang, Wenqian Ye, Yuntao Du, Yunpu Ma, Yijun Tian
分类: cs.CL
发布日期: 2025-10-12
🔗 代码/项目: GITHUB
💡 一句话要点
RECON:通过冷凝推理提升检索增强生成效率,显著降低上下文长度并提高性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 检索增强生成 上下文压缩 摘要模块 多跳问答 知识蒸馏
📋 核心要点
- 现有RAG系统在推理时面临长文档噪声干扰,导致成本增加和性能下降。
- RECON通过在推理循环中集成摘要模块,压缩证据,从而减少上下文长度。
- 实验表明,RECON显著提升了RAG在QA任务上的性能,尤其是在多跳QA中。
📝 摘要(中文)
本文提出RECON(REasoning with CONdensation)框架,旨在解决检索增强生成(RAG)系统中因上下文管理效率低下而导致的问题。RECON集成了一个显式的摘要模块,用于压缩推理循环中的证据。该摘要器通过两阶段训练:首先在QA数据集上进行相关性预训练,然后通过专有LLM进行多方面蒸馏,以确保事实性和清晰度。RECON集成到Search-R1流程中,可将总上下文长度减少35%,从而提高训练速度和推理延迟,同时提高下游QA基准上的RAG性能。值得注意的是,它将3B模型的平均EM得分提高了14.5%,将7B模型的平均EM得分提高了3.0%,尤其在多跳QA中表现出优势。RECON表明,学习到的上下文压缩对于构建实用、可扩展且高性能的RAG系统至关重要。代码已开源。
🔬 方法详解
问题定义:现有基于强化学习的检索增强生成(RAG)系统,在进行推理时,会检索到大量的文档,其中包含许多噪声信息。这些冗长且嘈杂的检索文档不仅增加了计算成本,还降低了模型的性能,尤其是在处理需要多步推理的复杂问题时。因此,如何有效地管理和利用检索到的上下文信息,是RAG系统面临的一个重要挑战。
核心思路:RECON的核心思路是在推理过程中引入一个显式的摘要模块,对检索到的文档进行压缩,提取关键信息。通过减少上下文长度,降低计算成本,并提高模型对关键信息的关注度,从而提升RAG系统的整体性能。这种方法借鉴了人类在解决复杂问题时,会先对相关信息进行总结和提炼的认知过程。
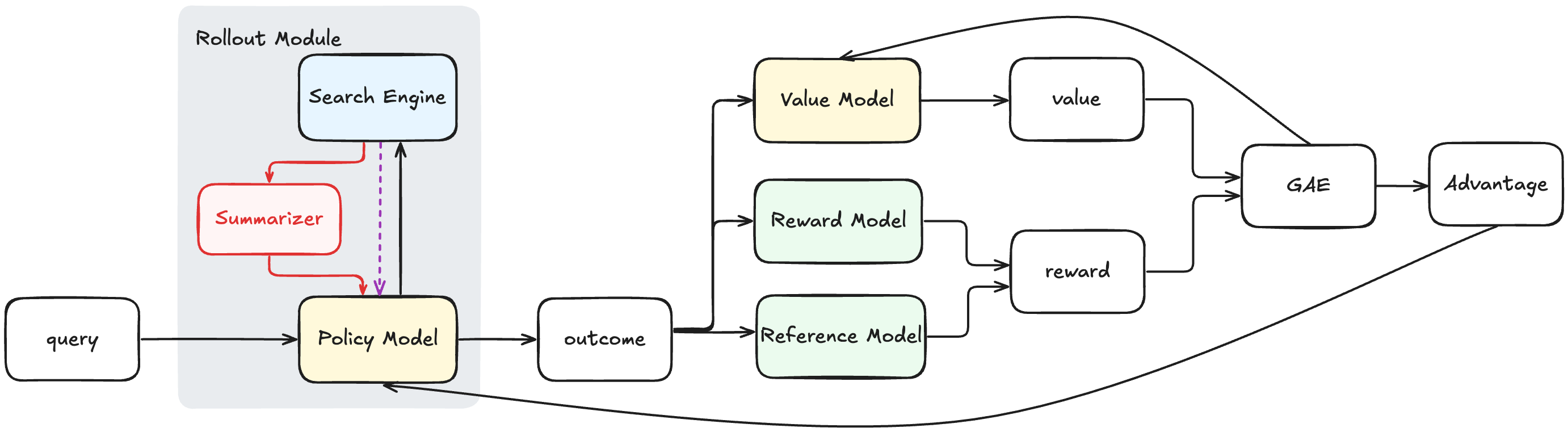
技术框架:RECON框架主要包含以下几个模块:1) 检索模块:负责从知识库中检索相关文档;2) 摘要模块:负责对检索到的文档进行压缩,提取关键信息;3) 生成模块:负责根据压缩后的上下文信息生成答案。摘要模块是RECON框架的核心,它通过两阶段训练得到:首先在QA数据集上进行相关性预训练,然后通过多方面蒸馏从专有LLM学习,以确保事实性和清晰度。RECON框架可以集成到现有的RAG流程中,例如Search-R1。
关键创新:RECON的关键创新在于引入了一个可学习的上下文压缩模块,该模块能够显式地对检索到的文档进行摘要,提取关键信息。与传统的RAG系统相比,RECON能够更有效地利用上下文信息,从而提高模型的性能。此外,RECON的摘要模块通过两阶段训练,确保了摘要的质量和可靠性。
关键设计:RECON的摘要模块采用两阶段训练策略。第一阶段,在QA数据集上进行相关性预训练,目标是使摘要模块能够识别与问题相关的关键信息。第二阶段,通过多方面蒸馏从专有LLM学习,目标是提高摘要的事实性和清晰度。在训练过程中,使用了多种损失函数,包括相关性损失、事实性损失和清晰度损失。具体的网络结构和参数设置,论文中可能包含更详细的信息。
🖼️ 关键图片
📊 实验亮点
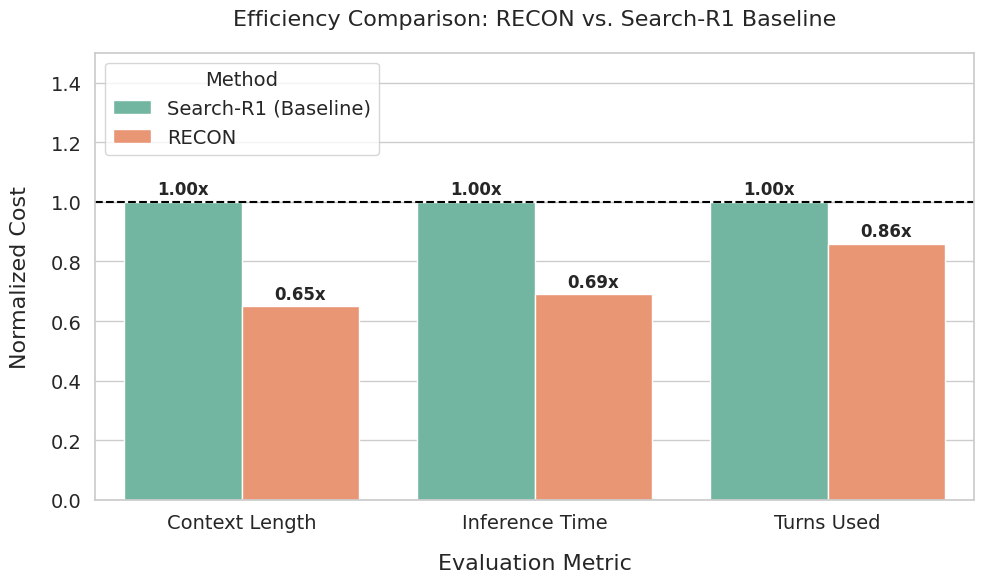
RECON在下游QA基准测试中表现出色,3B模型的平均EM得分提高了14.5%,7B模型的平均EM得分提高了3.0%。尤其在多跳QA任务中,RECON展现出更强的优势。此外,RECON还能够将总上下文长度减少35%,从而显著提高训练速度和推理延迟。这些实验结果表明,RECON是一种有效且高效的RAG系统。
🎯 应用场景
RECON框架可应用于各种需要检索增强生成的场景,例如问答系统、对话系统、知识图谱推理等。通过减少上下文长度,RECON可以降低计算成本,提高系统的响应速度,并提升用户体验。此外,RECON还可以应用于信息抽取、文本摘要等任务,具有广泛的应用前景。
📄 摘要(原文)
Retrieval-augmented generation (RAG) systems trained using reinforcement learning (RL) with reasoning are hampered by inefficient context management, where long, noisy retrieved documents increase costs and degrade performance. We introduce RECON (REasoning with CONdensation), a framework that integrates an explicit summarization module to compress evidence within the reasoning loop. Our summarizer is trained via a two-stage process: relevance pretraining on QA datasets, followed by multi-aspect distillation from proprietary LLMs to ensure factuality and clarity. Integrated into the Search-R1 pipeline, RECON reduces total context length by 35\%, leading to improved training speed and inference latency, while simultaneously improving RAG performance on downstream QA benchmarks. Notably, it boosts the average EM score of the 3B model by 14.5\% and the 7B model by 3.0\%, showing particular strength in multi-hop QA. RECON demonstrates that learned context compression is essential for building practical, scalable, and performant RAG systems. Our code implementation is made available at https://github.com/allfornancy/RECON.