BenchPress: A Human-in-the-Loop Annotation System for Rapid Text-to-SQL Benchmark Curation
作者: Fabian Wenz, Omar Bouattour, Devin Yang, Justin Choi, Cecil Gregg, Nesime Tatbul, Çağatay Demiralp
分类: cs.CL, cs.AI, cs.DB, cs.HC
发布日期: 2025-10-11 (更新: 2026-01-31)
备注: CIDR'26
🔗 代码/项目: GITHUB
💡 一句话要点
BenchPress:一种人机协同的标注系统,用于快速构建Text-to-SQL基准
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: Text-to-SQL 人机协同 基准构建 大型语言模型 检索增强生成
📋 核心要点
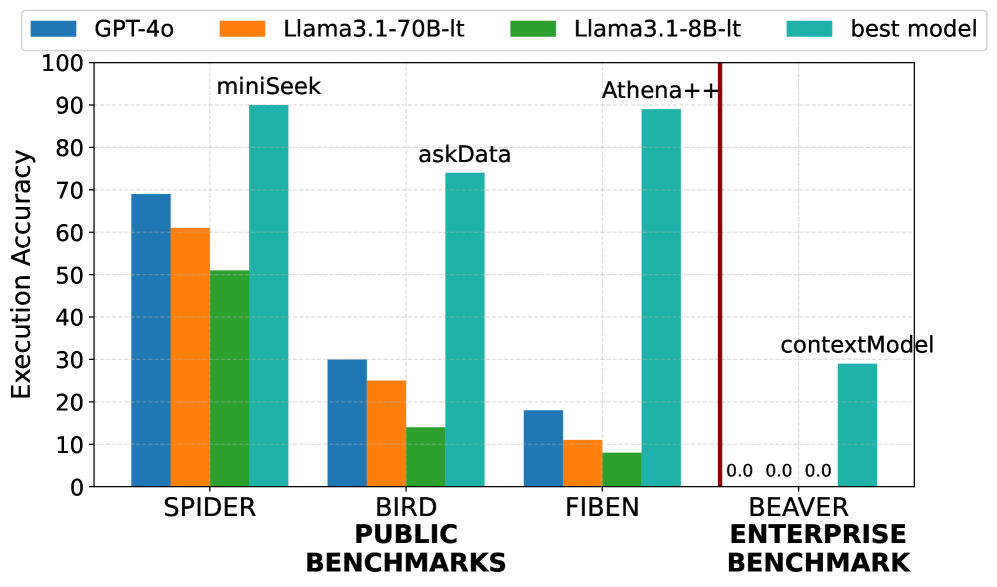
- 现有Text-to-SQL模型在私有企业数据上的表现不佳,缺乏高质量的领域特定基准是主要瓶颈。
- BenchPress利用检索增强生成(RAG)和LLM,为给定的SQL查询生成多个自然语言描述草案,供人工专家选择和编辑。
- 实验表明,BenchPress显著降低了创建高质量Text-to-SQL基准的时间和精力,提升了标注准确性和基准可靠性。
📝 摘要(中文)
大型语言模型(LLMs)已成功应用于许多任务,包括text-to-SQL生成。然而,大部分工作集中于公开数据集,如Fiben、Spider和Bird。我们之前的工作表明,LLMs在查询大型私有企业数据仓库时效果较差,并发布了Beaver,这是第一个私有企业text-to-SQL基准。为了创建Beaver,我们利用了通常容易获得的SQL日志。然而,手动标注这些日志以识别它们回答的自然语言问题是一项艰巨的任务。要求数据库管理员(高度训练有素的专家)承担额外的工作来构建和验证相应的自然语言表达不仅具有挑战性,而且成本很高。为了解决这个问题,我们引入了BenchPress,一种人机协同系统,旨在加速创建特定领域的text-to-SQL基准。给定一个SQL查询,BenchPress使用检索增强生成(RAG)和LLMs来提出多个自然语言描述。然后,人类专家选择、排序或编辑这些草案,以确保准确性和领域一致性。我们在标注的企业SQL日志上评估了BenchPress,证明了LLM辅助标注大大减少了创建高质量基准所需的时间和精力。我们的结果表明,将人工验证与LLM生成的建议相结合,可以提高标注准确性、基准可靠性和模型评估的鲁棒性。通过简化自定义基准的创建,BenchPress为研究人员和从业人员提供了一种机制,用于评估给定领域特定工作负载上的text-to-SQL模型。
🔬 方法详解
问题定义:论文旨在解决为特定领域快速创建高质量Text-to-SQL基准的问题。现有方法依赖于人工标注,成本高昂且耗时,尤其是在私有企业数据场景下,领域知识要求高,标注难度大。现有公开数据集难以反映真实的企业应用场景,导致模型在实际应用中效果不佳。
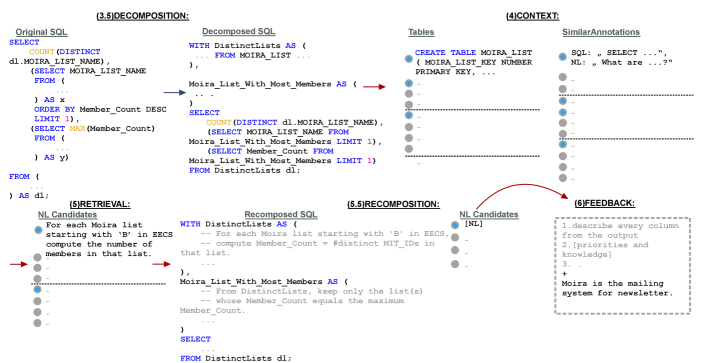
核心思路:论文的核心思路是利用大型语言模型(LLM)的生成能力,结合检索增强生成(RAG),自动生成SQL查询对应的自然语言描述草案,然后由人工专家进行选择、排序或编辑,从而实现人机协同的标注流程。这种方法旨在降低人工标注的工作量,提高标注效率和质量。
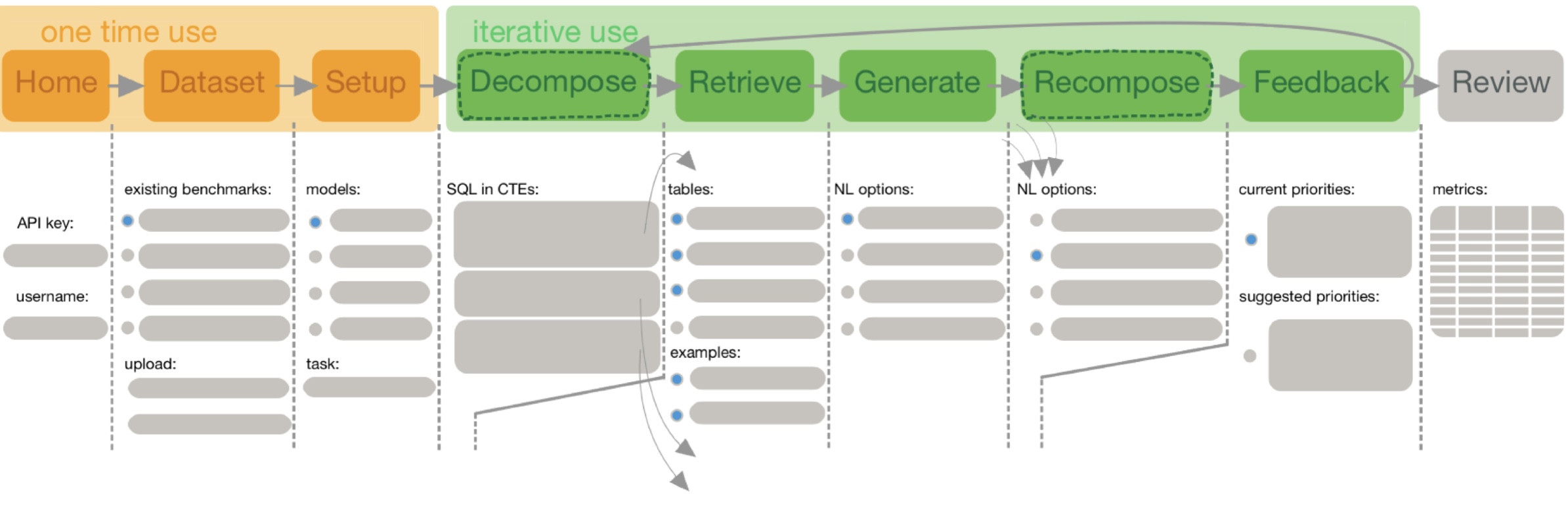
技术框架:BenchPress系统的整体架构包含以下几个主要模块:1) SQL查询输入模块:接收需要标注的SQL查询。2) RAG模块:根据输入的SQL查询,从预先构建的知识库中检索相关信息,并将其作为LLM的输入。3) LLM生成模块:利用LLM(如GPT-3)生成多个自然语言描述草案。4) 人工标注界面:提供一个用户友好的界面,供人工专家选择、排序或编辑LLM生成的草案。5) 基准构建模块:将人工标注后的数据整合为最终的Text-to-SQL基准。
关键创新:该论文的关键创新在于将检索增强生成(RAG)与人机协同标注相结合,用于快速构建特定领域的Text-to-SQL基准。与完全依赖人工标注或完全依赖LLM自动生成的方法相比,BenchPress能够更好地平衡标注效率和质量,并能够更好地适应特定领域的知识和需求。
关键设计:RAG模块的关键设计在于知识库的构建和检索策略。知识库可以包含数据库的schema信息、领域知识、以及已有的标注数据。检索策略需要能够准确地找到与SQL查询相关的知识,以提高LLM生成自然语言描述的质量。LLM生成模块的关键设计在于prompt的设计,prompt需要能够引导LLM生成准确、简洁、且符合领域规范的自然语言描述。人工标注界面的关键设计在于提供高效的编辑工具和反馈机制,以便人工专家能够快速地完成标注任务。
🖼️ 关键图片
📊 实验亮点
实验结果表明,BenchPress能够显著降低创建高质量Text-to-SQL基准所需的时间和精力。通过结合人工验证与LLM生成的建议,BenchPress提高了标注准确性、基准可靠性和模型评估的鲁棒性。具体性能数据和对比基线在论文中进行了详细描述,展示了BenchPress在实际应用中的优势。
🎯 应用场景
BenchPress可应用于各种需要构建领域特定Text-to-SQL基准的场景,例如金融、医疗、电商等。它可以帮助企业快速构建高质量的基准,用于评估和优化Text-to-SQL模型,从而提高数据分析和决策的效率。此外,该系统还可以用于教育和研究领域,帮助学生和研究人员更好地理解和解决Text-to-SQL问题。
📄 摘要(原文)
Large language models (LLMs) have been successfully applied to many tasks, including text-to-SQL generation. However, much of this work has focused on publicly available datasets, such as Fiben, Spider, and Bird. Our earlier work showed that LLMs are much less effective in querying large private enterprise data warehouses and released Beaver, the first private enterprise text-to-SQL benchmark. To create Beaver, we leveraged SQL logs, which are often readily available. However, manually annotating these logs to identify which natural language questions they answer is a daunting task. Asking database administrators, who are highly trained experts, to take on additional work to construct and validate corresponding natural language utterances is not only challenging but also quite costly. To address this challenge, we introduce BenchPress, a human-in-the-loop system designed to accelerate the creation of domain-specific text-to-SQL benchmarks. Given a SQL query, BenchPress uses retrieval-augmented generation (RAG) and LLMs to propose multiple natural language descriptions. Human experts then select, rank, or edit these drafts to ensure accuracy and domain alignment. We evaluated BenchPress on annotated enterprise SQL logs, demonstrating that LLM-assisted annotation drastically reduces the time and effort required to create high-quality benchmarks. Our results show that combining human verification with LLM-generated suggestions enhances annotation accuracy, benchmark reliability, and model evaluation robustness. By streamlining the creation of custom benchmarks, BenchPress offers researchers and practitioners a mechanism for assessing text-to-SQL models on a given domain-specific workload. BenchPress is freely available via our public GitHub repository at https://github.com/fabian-wenz/enterprise-txt2sql and is also accessible on our website at http://dsg-mcgraw.csail.mit.edu:5000.