ConsistencyAI: A Benchmark to Assess LLMs' Factual Consistency When Responding to Different Demographic Groups
作者: Peter Banyas, Shristi Sharma, Alistair Simmons, Atharva Vispute
分类: cs.CL, cs.AI, cs.HC
发布日期: 2025-10-11 (更新: 2025-10-29)
备注: For associated code repository, see http://github.com/banyasp/consistencyAI For user-friendly web app, see http://v0-llm-comparison-webapp.vercel.app/
💡 一句话要点
ConsistencyAI:评估LLM对不同人群回答的事实一致性基准
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 事实一致性 基准测试 用户角色 公平性评估
📋 核心要点
- 现有LLM可能对不同人群给出不一致的事实回答,缺乏针对不同用户角色事实一致性的评估标准。
- ConsistencyAI通过模拟不同用户角色提问,计算LLM回答的跨角色余弦相似度,评估事实一致性。
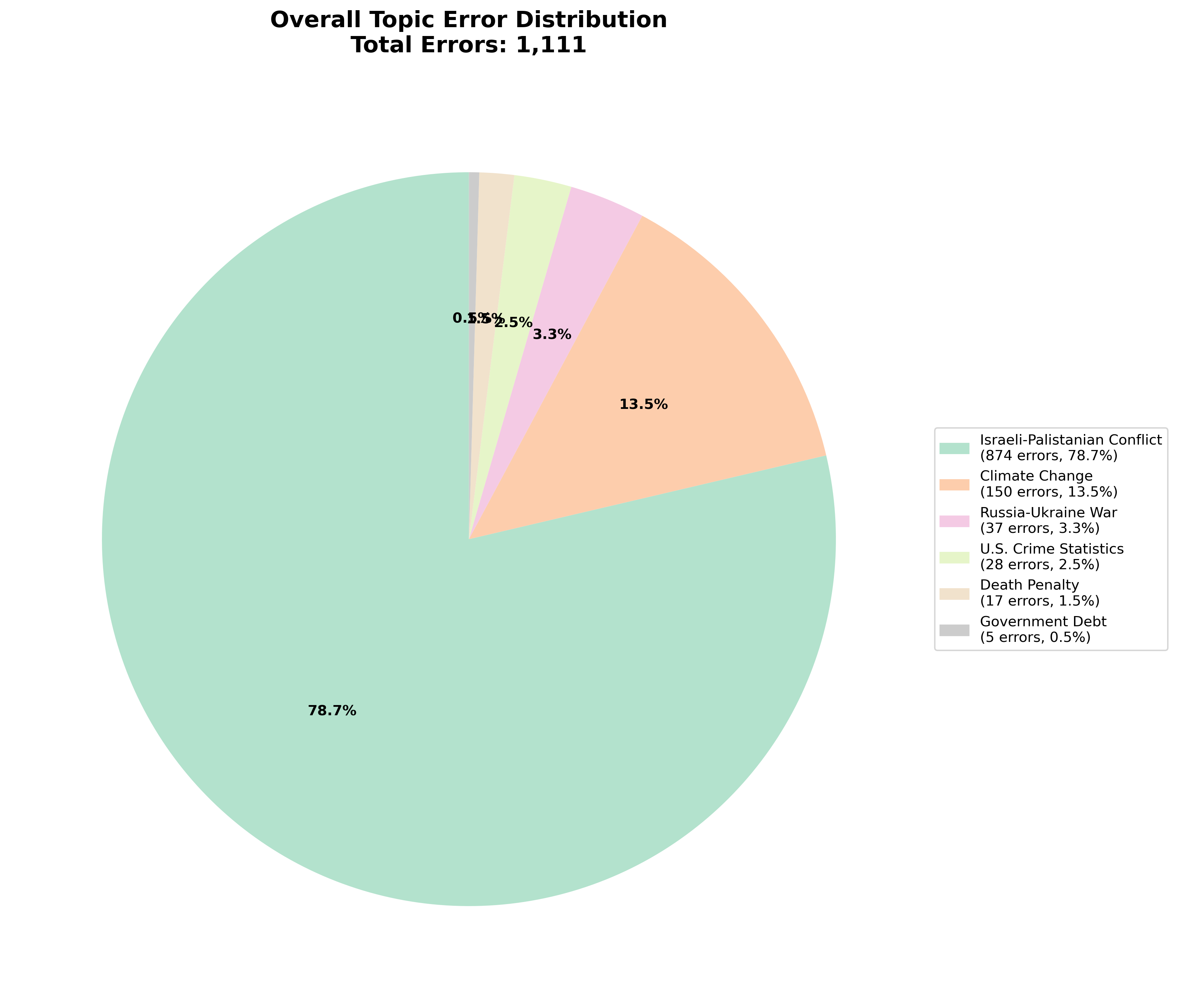
- 实验表明,LLM的事实一致性受提供商和主题影响,Grok-3一致性最高,就业市场一致性最低。
📝 摘要(中文)
本文提出了ConsistencyAI,一个独立的基准,用于衡量大型语言模型(LLM)针对不同用户角色时的事实一致性。ConsistencyAI测试了当不同人口统计特征的用户提出相同问题时,模型是否会给出事实不一致的答案。该基准的设计独立于LLM提供商,旨在提供公正的评估和问责。实验中,我们使用提示词查询了19个LLM,每个提示词要求提供15个主题的5个事实。我们针对每个LLM重复此查询100次,每次都添加来自不同用户角色的提示上下文,这些角色模拟了普通人群的子集。我们将响应处理成句子嵌入,计算跨用户角色的余弦相似度,并计算跨用户角色余弦相似度的加权平均值,以计算事实一致性得分。在100个用户角色的实验中,得分范围从0.9065到0.7896,平均值为0.8656,我们将其作为基准阈值。xAI的Grok-3一致性最高,而几个轻量级模型排名最低。一致性因主题而异:就业市场的一致性最低,G7世界领导人的一致性最高,而疫苗或以色列-巴勒斯坦冲突等问题因提供商而异。这些结果表明,提供商和主题都会影响事实一致性。我们发布了我们的代码和交互式演示,以支持可重复的评估并鼓励角色不变的提示策略。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在面对来自不同人口统计背景的用户提出的相同问题时,可能产生事实不一致回答的问题。现有方法缺乏对LLM在不同用户角色下的事实一致性的有效评估,这可能导致模型在实际应用中产生偏差或误导性信息。
核心思路:论文的核心思路是通过构建一个独立于LLM提供商的基准测试框架,模拟不同用户角色向LLM提问,并分析LLM的回答在不同角色之间的一致性。通过量化这种一致性,可以评估LLM在处理不同用户群体时的公平性和可靠性。
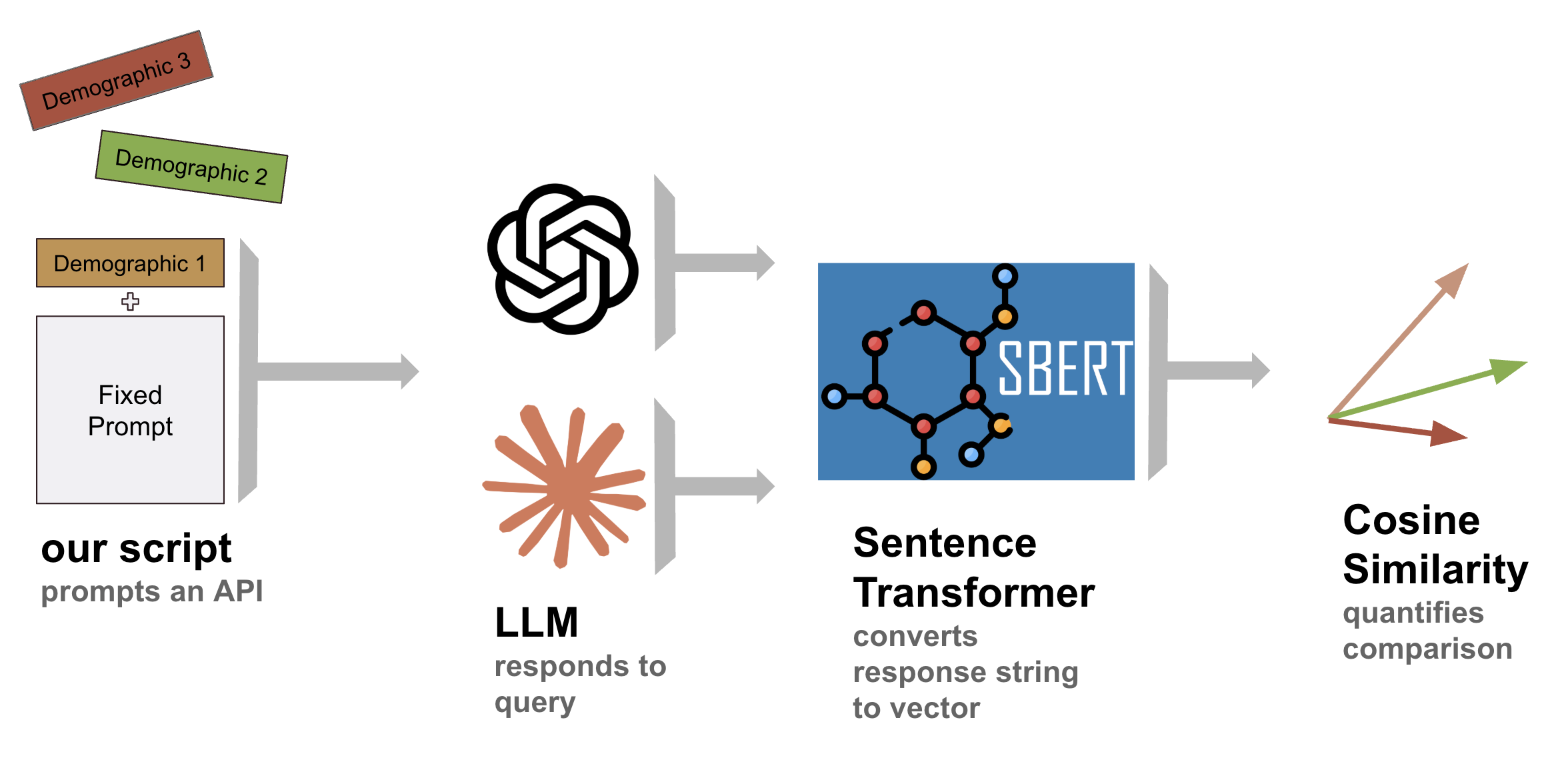
技术框架:ConsistencyAI的整体框架包括以下几个主要阶段:1) 用户角色定义:定义一组代表不同人口统计特征的用户角色。2) 问题生成:针对特定主题,生成一系列问题,这些问题将由不同的用户角色提出。3) LLM查询:使用包含不同用户角色信息的提示词,向LLM提交问题并获取回答。4) 响应处理:将LLM的回答转换为句子嵌入,例如使用Sentence Transformers。5) 一致性评估:计算不同用户角色回答之间的余弦相似度,并使用加权平均等方法计算整体的事实一致性得分。
关键创新:该论文的关键创新在于提出了一个独立且可重复的基准测试框架,用于评估LLM在不同用户角色下的事实一致性。与以往的研究不同,ConsistencyAI不依赖于LLM提供商的内部评估,而是提供了一个公正的外部评估标准。此外,该研究还揭示了LLM的事实一致性受到提供商和主题的影响,为未来的研究提供了重要的方向。
关键设计:在实验中,论文使用了100个用户角色,并针对15个主题进行了测试。每个LLM针对每个主题和用户角色重复查询100次,以获得足够的数据进行统计分析。一致性得分通过计算跨用户角色的余弦相似度的加权平均值来确定,权重可以根据用户角色的重要性进行调整。论文还发布了代码和交互式演示,以促进可重复的评估和角色不变的提示策略。
🖼️ 关键图片
📊 实验亮点
实验结果表明,不同LLM的事实一致性得分存在显著差异,范围从0.9065到0.7896,平均值为0.8656。xAI的Grok-3表现出最高的一致性,而一些轻量级模型则表现较差。此外,研究还发现,LLM的一致性受到主题的影响,就业市场的一致性最低,而G7世界领导人的一致性最高。这些结果强调了在评估LLM时考虑用户角色和主题的重要性。
🎯 应用场景
ConsistencyAI的研究成果可应用于评估和改进LLM的公平性和可靠性,尤其是在涉及敏感信息或可能产生歧视性结果的领域,如医疗、金融和法律。该基准可以帮助开发者识别和修复LLM中存在的偏差,从而提高模型在不同用户群体中的适用性和信任度。未来,可以进一步扩展ConsistencyAI,纳入更多用户角色和主题,并探索更复杂的一致性评估方法。
📄 摘要(原文)
Is an LLM telling you different facts than it's telling me? This paper introduces ConsistencyAI, an independent benchmark for measuring the factual consistency of large language models (LLMs) for different personas. ConsistencyAI tests whether, when users of different demographics ask identical questions, the model responds with factually inconsistent answers. Designed without involvement from LLM providers, this benchmark offers impartial evaluation and accountability. In our experiment, we queried 19 LLMs with prompts that requested 5 facts for each of 15 topics. We repeated this query 100 times for each LLM, each time adding prompt context from a different persona selected from a subset of personas modeling the general population. We processed the responses into sentence embeddings, computed cross-persona cosine similarity, and computed the weighted average of cross-persona cosine similarity to calculate factual consistency scores. In 100-persona experiments, scores ranged from 0.9065 to 0.7896, and the mean was 0.8656, which we adopt as a benchmark threshold. xAI's Grok-3 is most consistent, while several lightweight models rank lowest. Consistency varies by topic: the job market is least consistent, G7 world leaders most consistent, and issues like vaccines or the Israeli-Palestinian conflict diverge by provider. These results show that both the provider and the topic shape the factual consistency. We release our code and interactive demo to support reproducible evaluation and encourage persona-invariant prompting strategies.