Revisiting the UID Hypothesis in LLM Reasoning Traces
作者: Minju Gwak, Guijin Son, Jaehyung Kim
分类: cs.CL, cs.AI
发布日期: 2025-10-11
期刊: The 5th Workshop on Mathematical Reasoning and AI, NeurIPS 2025
💡 一句话要点
揭示LLM推理轨迹中信息密度非均匀性,挑战UID假设
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 思维链推理 信息密度 均匀信息密度假设 可解释性 熵 数学推理
📋 核心要点
- LLM的CoT推理过程缺乏透明度,中间步骤难以理解且可能不准确。
- 借鉴心理语言学UID假设,提出基于熵的指标来分析LLM推理过程中的信息流。
- 实验表明,LLM成功推理的信息密度波动大,与人类均匀信息流模式相反。
📝 摘要(中文)
大型语言模型(LLMs)通常采用逐步的思维链(CoT)推理来解决问题,但这些中间步骤常常不忠实或难以解释。受到心理语言学中均匀信息密度(UID)假设的启发——该假设认为人类通过维持稳定的信息流来进行交流——我们引入了基于熵的指标来分析推理轨迹中的信息流。令人惊讶的是,在三个具有挑战性的数学基准测试中,我们发现LLMs中成功的推理在全局上是非均匀的:正确的解决方案的特征是信息密度不均匀的波动,这与人类的交流模式形成鲜明对比。这一结果挑战了关于机器推理的假设,并为设计可解释和自适应的推理模型提出了新的方向。
🔬 方法详解
问题定义:论文旨在研究大型语言模型(LLMs)在进行思维链(CoT)推理时,其推理轨迹中的信息密度分布是否符合心理语言学中的均匀信息密度(UID)假设。现有的CoT推理方法虽然能够提升LLM的解题能力,但中间步骤缺乏可解释性,且可能包含不准确的信息,这使得我们难以理解LLM是如何得出最终答案的。因此,理解LLM推理过程中的信息流动模式至关重要。
核心思路:论文的核心思路是利用信息论中的熵来量化LLM推理轨迹中每个步骤的信息密度,并分析信息密度随推理步骤的变化情况。通过比较成功推理和失败推理的信息密度分布,以及与人类交流模式的对比,来验证或推翻UID假设在LLM推理中的适用性。如果LLM推理过程符合UID假设,则信息密度应该保持相对稳定;反之,则信息密度会出现显著波动。
技术框架:论文的技术框架主要包括以下几个步骤:1)选择具有挑战性的数学基准测试数据集;2)利用LLM生成CoT推理轨迹;3)使用基于熵的指标(如token entropy)来计算每个推理步骤的信息密度;4)分析信息密度随推理步骤的变化情况,并比较成功推理和失败推理的分布差异;5)将LLM的推理模式与人类的交流模式进行对比,以验证UID假设。
关键创新:论文最重要的技术创新点在于将心理语言学中的UID假设引入到LLM推理过程的分析中,并提出了一种基于熵的指标来量化推理轨迹中的信息密度。通过这种方法,论文能够更深入地理解LLM的推理过程,并揭示其与人类推理模式的差异。此外,论文还发现LLM成功推理的信息密度波动较大,这与UID假设相悖,为设计更可解释和自适应的推理模型提供了新的思路。
关键设计:论文的关键设计包括:1)选择合适的数学基准测试数据集,以确保推理过程的复杂性和挑战性;2)使用token entropy作为信息密度的度量指标,该指标能够反映每个token所包含的信息量;3)设计实验来比较成功推理和失败推理的信息密度分布,以及与人类交流模式的对比;4)对实验结果进行统计分析,以验证UID假设的有效性。
🖼️ 关键图片
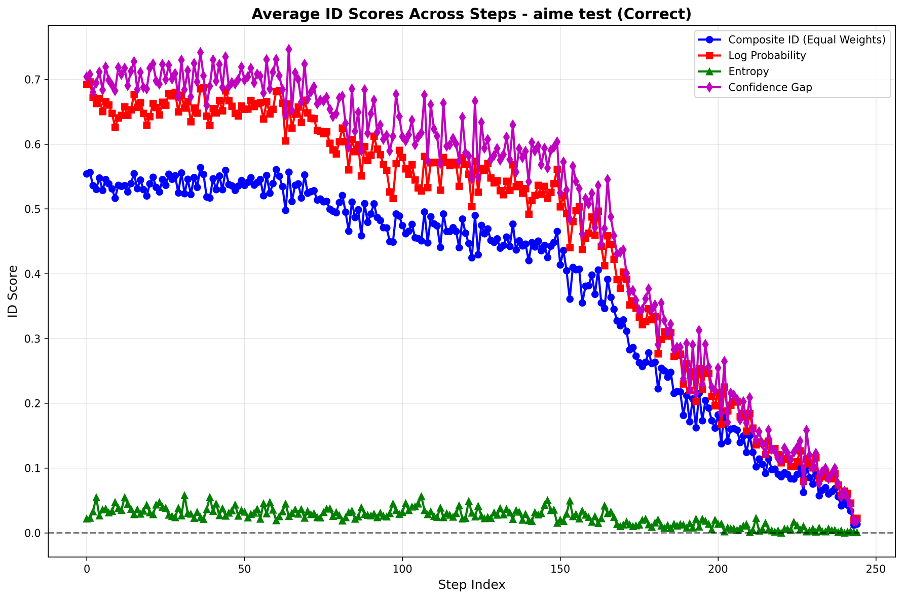
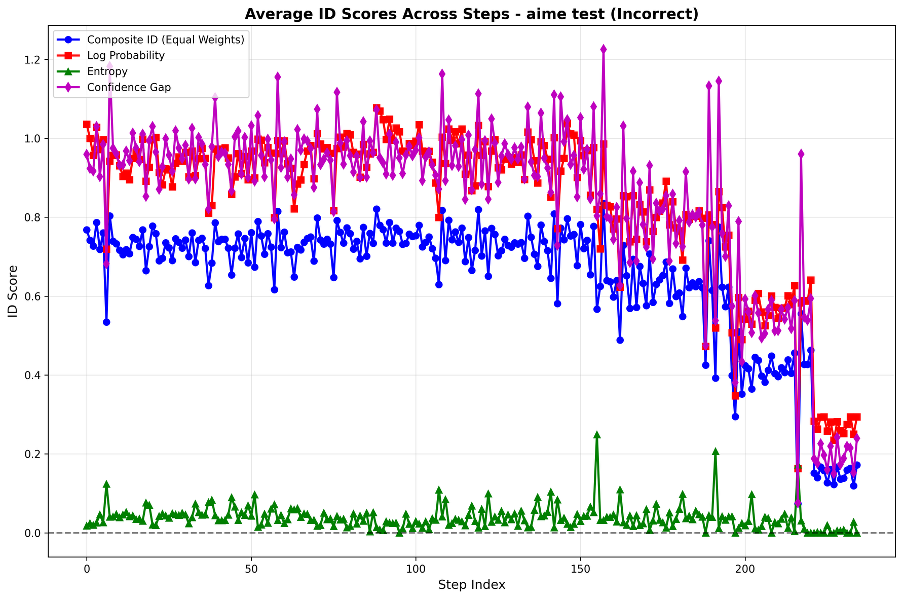
📊 实验亮点
实验结果表明,在三个数学基准测试中,LLM成功推理的轨迹表现出非均匀的信息密度分布,与人类交流模式显著不同。具体来说,成功推理的轨迹中信息密度波动更大,这表明LLM可能通过不稳定的信息流来解决复杂问题。这一发现挑战了UID假设在LLM推理中的适用性。
🎯 应用场景
该研究成果可应用于提升LLM推理过程的可解释性,帮助开发者设计更可靠、更透明的AI系统。通过理解LLM的信息流动模式,可以开发自适应推理模型,根据任务难度动态调整推理策略。此外,该研究也为评估LLM的推理能力提供了一种新的视角。
📄 摘要(原文)
Large language models (LLMs) often solve problems using step-by-step Chain-of-Thought (CoT) reasoning, yet these intermediate steps are frequently unfaithful or hard to interpret. Inspired by the Uniform Information Density (UID) hypothesis in psycholinguistics -- which posits that humans communicate by maintaining a stable flow of information -- we introduce entropy-based metrics to analyze the information flow within reasoning traces. Surprisingly, across three challenging mathematical benchmarks, we find that successful reasoning in LLMs is globally non-uniform: correct solutions are characterized by uneven swings in information density, in stark contrast to human communication patterns. This result challenges assumptions about machine reasoning and suggests new directions for designing interpretable and adaptive reasoning models.