On-device System of Compositional Multi-tasking in Large Language Models
作者: Ondrej Bohdal, Konstantinos Theodosiadis, Asterios Mpatziakas, Dimitris Filippidis, Iro Spyrou, Christos Zonios, Anastasios Drosou, Dimosthenis Ioannidis, Kyeng-Hun Lee, Jijoong Moon, Hyeonmok Ko, Mete Ozay, Umberto Michieli
分类: cs.CL, cs.AI, cs.LG
发布日期: 2025-10-11
备注: Accepted at EMNLP 2025 (industry track)
💡 一句话要点
针对LLM在端侧的组合多任务处理,提出一种高效的适配器融合方法。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 端侧部署 组合多任务 参数高效微调 LoRA适配器
📋 核心要点
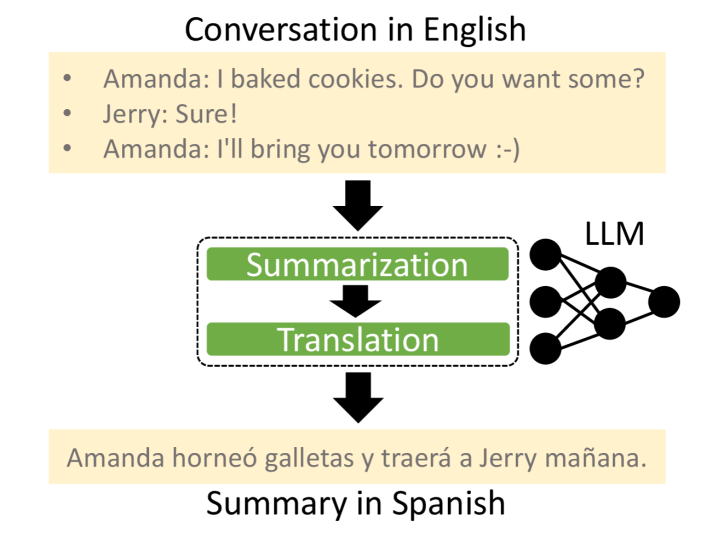
- 现有方法难以让LLM同时执行复杂的组合任务,如翻译长对话摘要。
- 通过在组合适配器上添加可学习的投影层,实现高效的任务集成。
- 在Android设备上实现了该方法,实验表明其在云端和端侧均表现良好。
📝 摘要(中文)
大型语言模型(LLM)通常通过参数高效的微调技术(如LoRA)来适应各种下游任务。虽然适配器可以组合以分别处理多个任务,但标准方法在同时执行复杂任务(例如从长对话生成翻译摘要)时会遇到困难。为了解决这个问题,我们提出了一种专门为涉及摘要和翻译的组合多任务场景量身定制的新方法。我们的技术包括在组合的摘要和翻译适配器之上添加一个可学习的投影层。这种设计能够实现有效的集成,同时通过减少计算开销来保持效率,而其他策略需要大量的重新训练或顺序处理。我们通过开发一个能够无缝执行组合任务的Android应用程序,证明了我们的方法在设备上的实际可行性。实验结果表明,我们的解决方案在基于云和设备上的实现中都表现良好且速度快,突出了在需要高速运行和资源约束的实际应用中采用我们的框架的潜在好处。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在端侧设备上进行组合多任务处理时效率低下的问题。具体来说,当需要同时执行多个任务,例如翻译一段对话的摘要时,传统的适配器组合方法要么需要大量的重新训练,要么需要顺序处理,导致计算开销大,速度慢,难以满足端侧设备对资源和速度的限制。
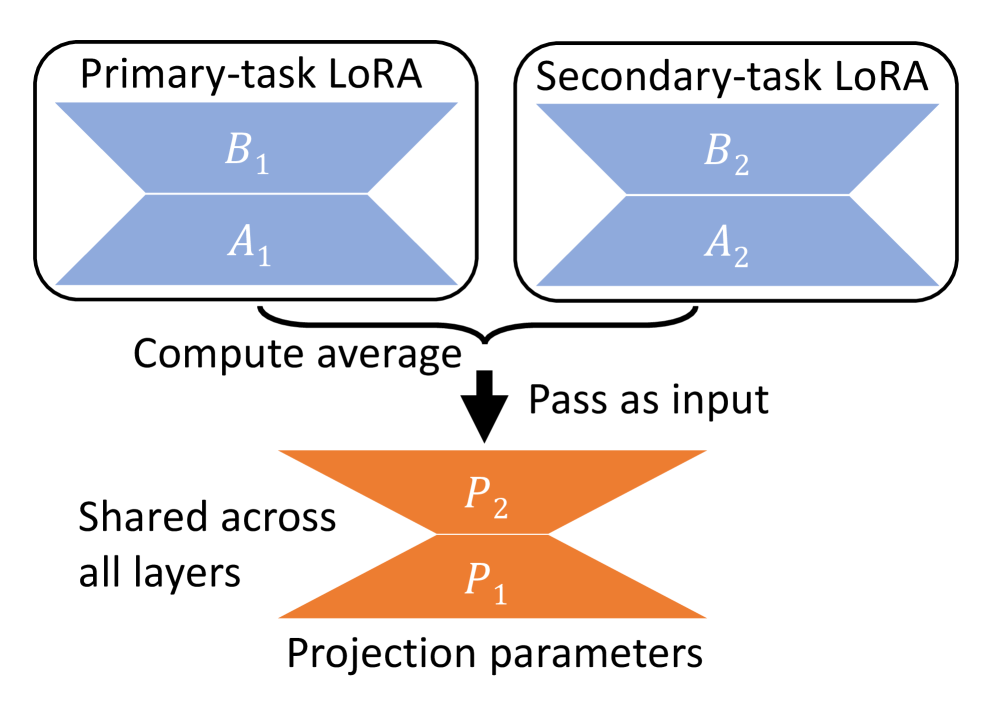
核心思路:论文的核心思路是在已有的摘要和翻译适配器的基础上,添加一个可学习的投影层。这个投影层的作用是将两个适配器的输出进行融合,从而使模型能够同时处理两个任务。这种方法避免了对整个模型进行重新训练,也避免了顺序处理带来的延迟,从而提高了效率。
技术框架:整体框架包括一个预训练的LLM,以及针对摘要和翻译任务的LoRA适配器。在两个适配器的输出之上,添加一个可学习的投影层,用于融合两个任务的信息。整个流程如下:输入文本首先经过LLM和两个适配器,然后适配器的输出被投影层融合,最后生成翻译后的摘要。
关键创新:最重要的技术创新点是引入了可学习的投影层,用于融合不同任务的适配器输出。与传统的适配器组合方法相比,该方法不需要重新训练整个模型,也不需要进行顺序处理,从而大大提高了效率。此外,该方法还能够更好地利用不同任务之间的相关性,从而提高模型的性能。
关键设计:投影层是一个简单的线性层,其输入维度等于两个适配器输出维度的总和,输出维度等于LLM的隐藏层维度。投影层的参数通过反向传播进行学习,目标是最小化翻译摘要的损失函数。论文中没有明确说明损失函数的具体形式,但可以推测是标准的交叉熵损失函数。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该方法在云端和端侧设备上均表现良好,速度快,性能优异。具体数据未知,但摘要中提到该方法在速度和资源利用率方面优于需要大量重新训练或顺序处理的替代方案。该方法在Android应用上的成功部署也证明了其在实际应用中的可行性。
🎯 应用场景
该研究成果可应用于各种需要端侧设备进行复杂多任务处理的场景,例如智能客服、实时翻译、智能家居等。通过在移动设备上部署该模型,用户可以随时随地进行翻译摘要等操作,无需依赖云端服务器,从而提高了隐私性和响应速度。该技术还有助于推动LLM在资源受限环境下的应用。
📄 摘要(原文)
Large language models (LLMs) are commonly adapted for diverse downstream tasks via parameter-efficient fine-tuning techniques such as Low-Rank Adapters (LoRA). While adapters can be combined to handle multiple tasks separately, standard approaches struggle when targeting the simultaneous execution of complex tasks, such as generating a translated summary from a long conversation. To address this challenge, we propose a novel approach tailored specifically for compositional multi-tasking scenarios involving summarization and translation. Our technique involves adding a learnable projection layer on top of the combined summarization and translation adapters. This design enables effective integration while maintaining efficiency through reduced computational overhead compared to alternative strategies requiring extensive retraining or sequential processing. We demonstrate the practical viability of our method within an on-device environment by developing an Android app capable of executing compositional tasks seamlessly. Experimental results indicate our solution performs well and is fast in both cloud-based and on-device implementations, highlighting the potential benefits of adopting our framework in real-world applications demanding high-speed operation alongside resource constraints.