Meronymic Ontology Extraction via Large Language Models
作者: Dekai Zhang, Simone Conia, Antonio Rago
分类: cs.CL, cs.AI
发布日期: 2025-10-11 (更新: 2025-11-09)
备注: Accepted to AACL 2025
💡 一句话要点
利用大型语言模型自动提取产品部件关系的本体,提升产品知识组织效率。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 本体提取 部件关系 产品评论 知识图谱
📋 核心要点
- 手动构建本体耗时费力,难以应对海量非结构化文本中知识的快速增长。
- 利用大型语言模型自动提取产品部件关系,构建产品本体,降低人工成本。
- 实验表明,该方法在本体提取任务中优于基于BERT的基线方法,提升了性能。
📝 摘要(中文)
本体在当今数字化时代已成为组织海量非结构化文本的关键。通过为信息提供正式结构,本体在各个领域都具有巨大的价值和应用,例如电子商务,其中无数的产品列表需要适当的产品组织。然而,手动构建这些本体是一个耗时、昂贵且费力的过程。本文利用大型语言模型(LLM)的最新进展,开发了一种全自动的方法,用于从原始评论文本中提取产品本体,形式为部件关系(meronymies)。我们证明,当使用LLM作为评判者进行评估时,我们的方法生成的本体优于现有的基于BERT的基线。我们的研究为LLM更广泛地应用于(产品或其他)本体提取奠定了基础。
🔬 方法详解
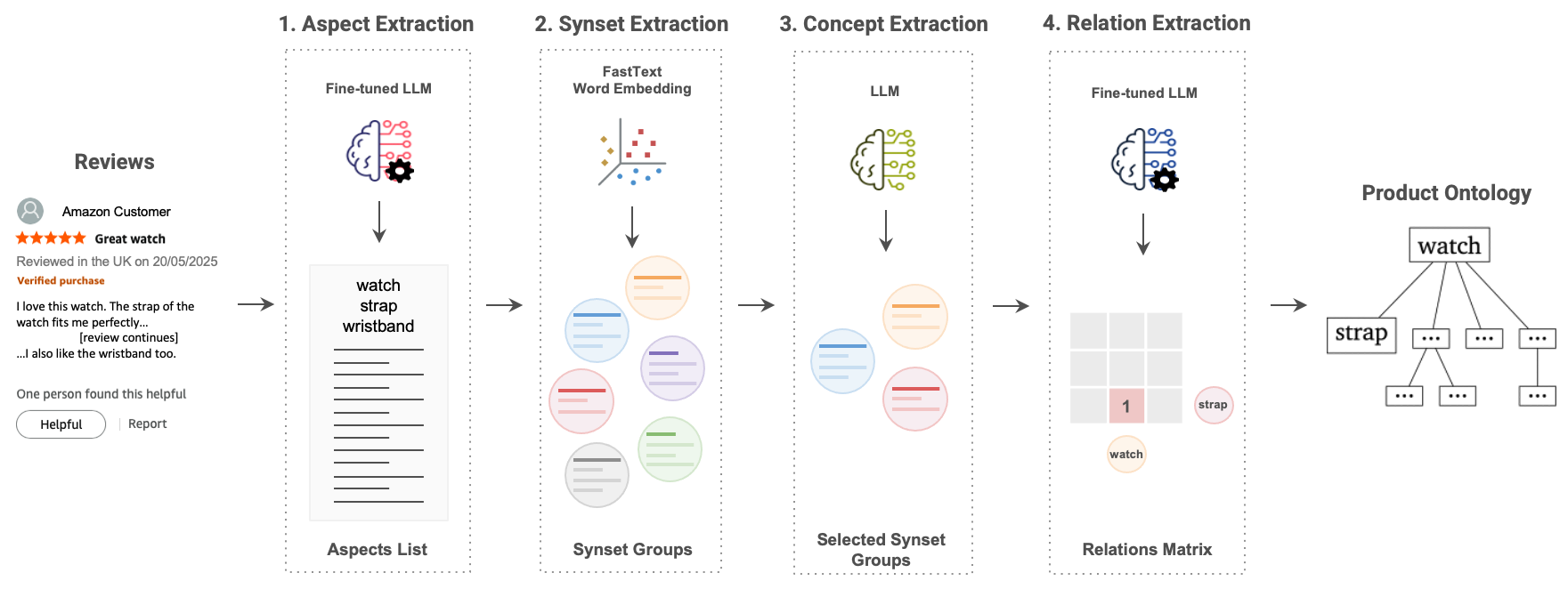
问题定义:论文旨在解决从非结构化文本(特别是产品评论)中自动提取产品部件关系(meronymies)的问题,并以此构建产品本体。现有方法,如基于BERT的方法,在准确性和效率方面存在不足,且需要大量人工干预。
核心思路:论文的核心思路是利用大型语言模型(LLM)强大的语言理解和生成能力,直接从产品评论文本中提取部件关系。通过精心设计的prompt,引导LLM识别并生成产品及其部件之间的关系,从而实现全自动的本体构建。
技术框架:该方法主要包含以下几个阶段:1) 数据准备:收集产品评论文本作为输入。2) Prompt设计:设计合适的prompt,引导LLM识别部件关系。3) LLM推理:使用LLM对输入文本进行推理,生成候选的部件关系。4) 关系过滤与评估:使用LLM作为评判者,对生成的部件关系进行过滤和评估,选择高质量的部件关系。
关键创新:该方法最重要的创新点在于利用LLM作为本体提取器和评估器,实现了全自动的本体构建流程。与传统方法相比,该方法无需人工标注数据,降低了成本,并提高了效率。此外,使用LLM作为评判者,可以更准确地评估本体的质量。
关键设计:论文的关键设计包括:1) Prompt的设计,需要充分利用LLM的上下文学习能力,引导其识别部件关系。2) 使用LLM作为评判者,需要设计合适的评估指标和prompt,以确保评估的准确性。3) 论文可能还涉及一些后处理步骤,例如去重、合并等,以提高本体的质量。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该方法在产品本体提取任务中优于基于BERT的基线方法。具体而言,使用LLM作为评判者进行评估时,该方法生成的本体在准确性和完整性方面均有显著提升。该研究为LLM在本体构建领域的应用提供了有力的证据。
🎯 应用场景
该研究成果可广泛应用于电子商务、知识图谱构建、产品信息管理等领域。通过自动构建产品本体,可以提升产品搜索、推荐和分类的效率,改善用户体验。未来,该方法还可以扩展到其他领域,例如医疗、金融等,构建更广泛的知识图谱。
📄 摘要(原文)
Ontologies have become essential in today's digital age as a way of organising the vast amount of readily available unstructured text. In providing formal structure to this information, ontologies have immense value and application across various domains, e.g., e-commerce, where countless product listings necessitate proper product organisation. However, the manual construction of these ontologies is a time-consuming, expensive and laborious process. In this paper, we harness the recent advancements in large language models (LLMs) to develop a fully-automated method of extracting product ontologies, in the form of meronymies, from raw review texts. We demonstrate that the ontologies produced by our method surpass an existing, BERT-based baseline when evaluating using an LLM-as-a-judge. Our investigation provides the groundwork for LLMs to be used more generally in (product or otherwise) ontology extraction.