Audit-of-Understanding: Posterior-Constrained Inference for Mathematical Reasoning in Language Models
作者: Samir Abdaljalil, Erchin Serpedin, Khalid Qaraqe, Hasan Kurban
分类: cs.CL, cs.AI
发布日期: 2025-10-11 (更新: 2025-10-18)
💡 一句话要点
提出Audit-of-Understanding以解决语言模型推理中的幻觉问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 语言模型 推理幻觉 后验约束推理 选择性预测 拒绝学习 数学推理 模型验证 准确性提升
📋 核心要点
- 现有方法主要关注事实幻觉或依赖事后验证,未能有效解决推理引发的幻觉问题。
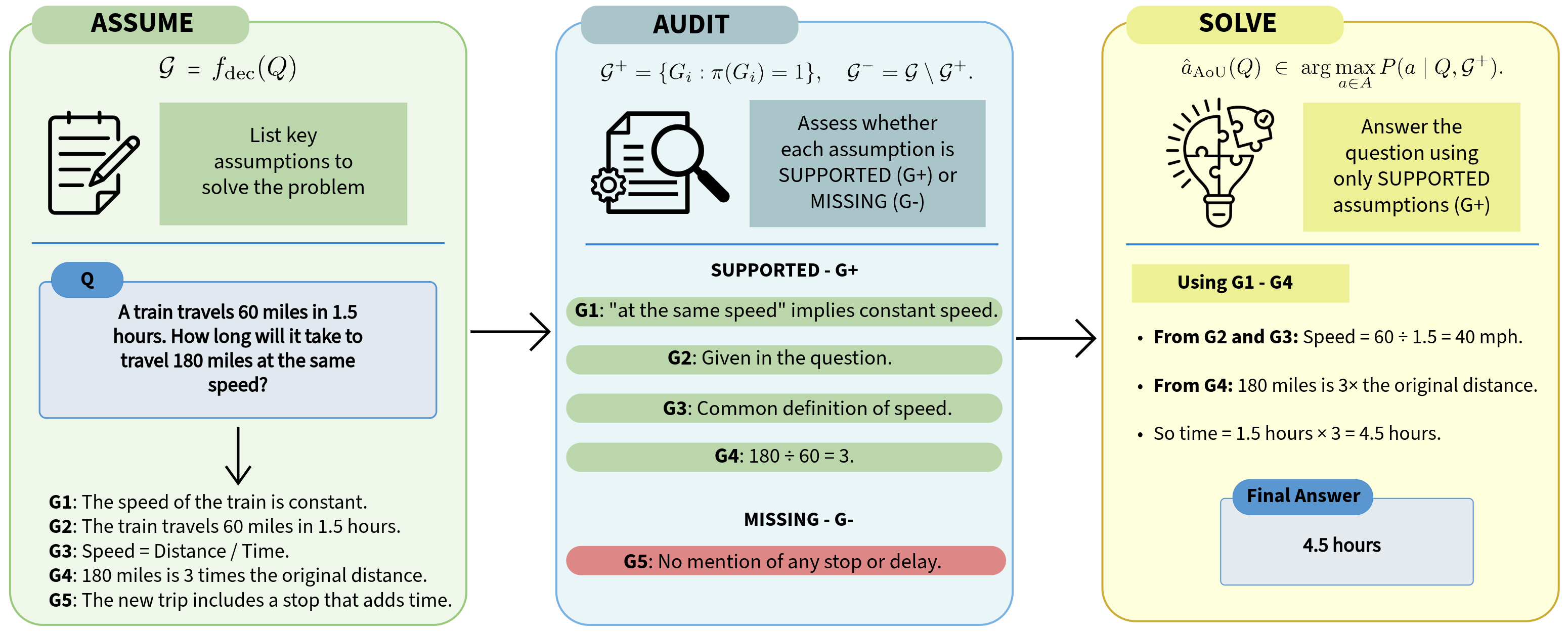
- 本文提出Audit-of-Understanding框架,通过分解查询、审计假设支持和基于验证子集进行推理来解决上述问题。
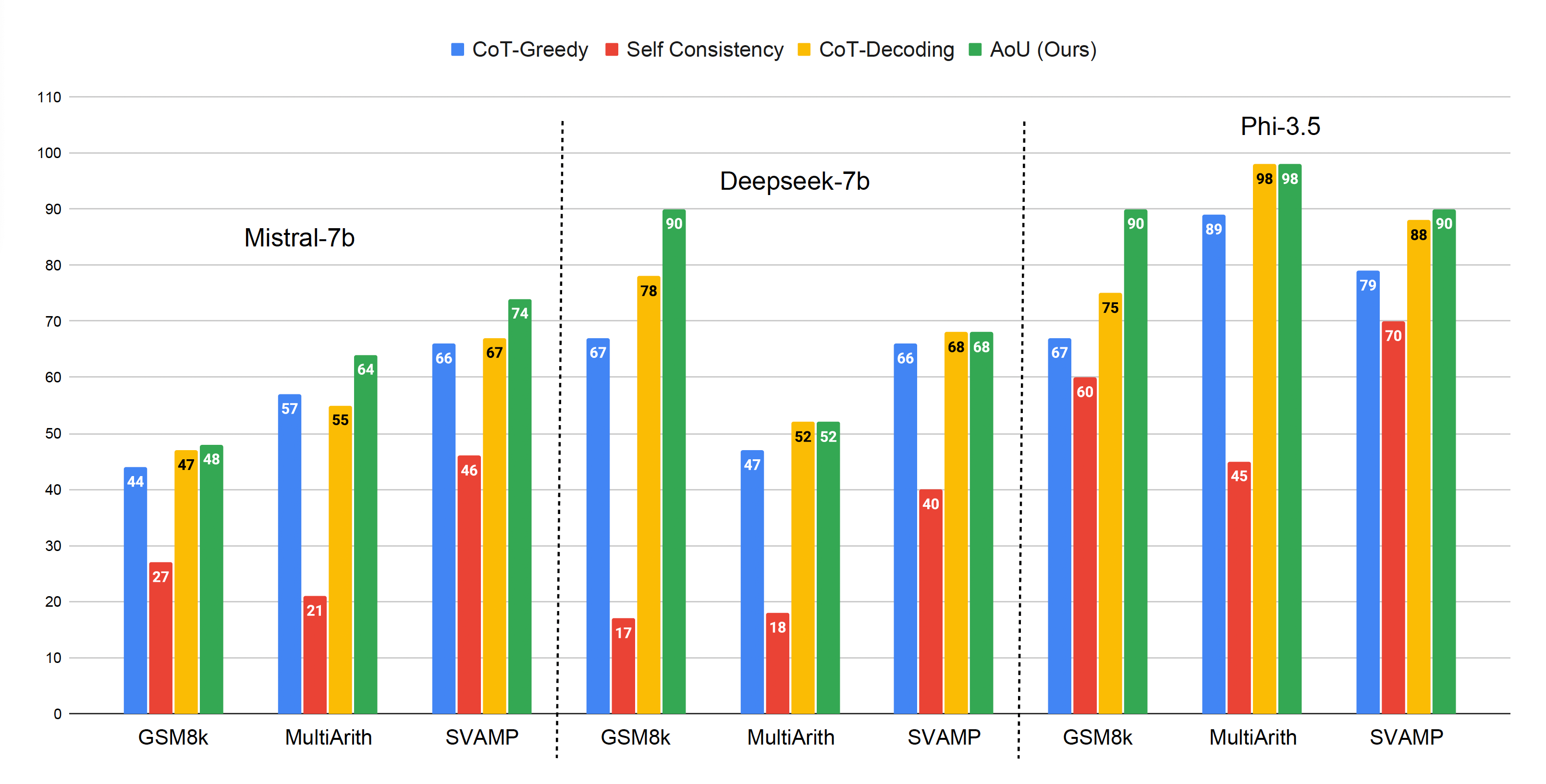
- 实验证明,AoU在多个基准数据集上显著提升了模型的准确性和可信度,尤其在GSM8K和MultiArith上表现突出。
📝 摘要(中文)
大型语言模型(LLMs)常生成看似连贯但基于不支持假设的推理轨迹,导致幻觉结论。以往研究主要关注事实幻觉或依赖事后验证,未能有效解决推理引发的幻觉问题。本文提出了Audit-of-Understanding(AoU)框架,通过三个阶段约束推理于已验证的前提:1)将查询分解为候选假设,2)审计其支持,3)仅基于已验证的子集进行推理。AoU形式上为后验约束推理,连接选择性预测和拒绝学习。我们的贡献包括:在完美验证下的理论保证、不完美审计下的超额风险界限及可处理性分析。实证结果显示,AoU在GSM8K、MultiArith和SVAMP上提高了准确性和可信度,GSM8K提升达30%,MultiArith达45%,SVAMP则稳定提升20-28%。
🔬 方法详解
问题定义:本文旨在解决大型语言模型在推理过程中产生的幻觉问题,现有方法未能有效处理推理引发的幻觉,导致生成的结论缺乏支持。
核心思路:提出Audit-of-Understanding框架,通过将查询分解为候选假设,审计其支持程度,并仅基于已验证的假设进行推理,从而提高推理的准确性和可信度。
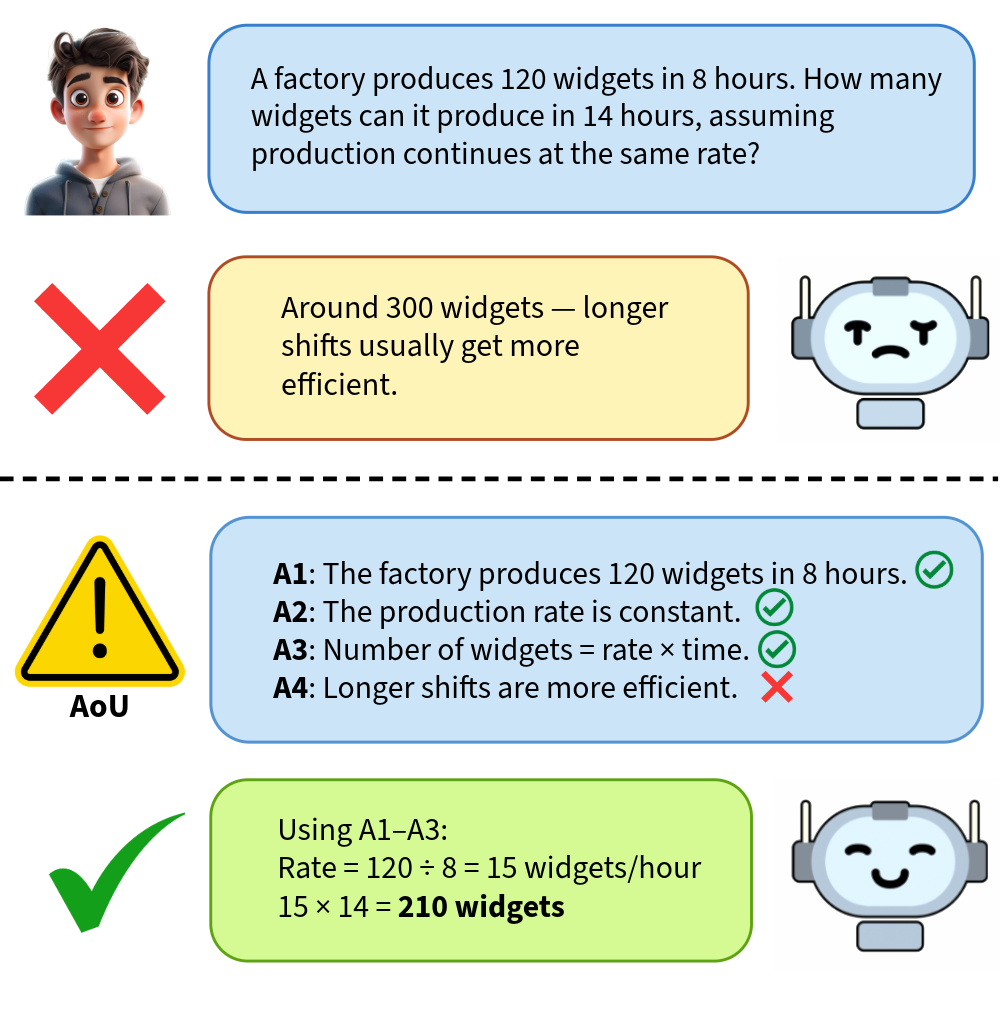
技术框架:AoU框架分为三个主要阶段:第一阶段是将输入查询分解为多个候选假设;第二阶段是对这些假设进行审计,以验证其支持程度;第三阶段是基于验证通过的假设进行推理。
关键创新:最重要的创新在于引入了后验约束推理的概念,确保推理过程仅依赖于经过验证的前提,从而有效减少推理幻觉的发生。
关键设计:在设计上,AoU框架包含了对假设支持的审计机制,采用了选择性预测和拒绝学习的策略,确保在不完美审计情况下也能提供超额风险界限的理论保证。
🖼️ 关键图片
📊 实验亮点
实验结果显示,Audit-of-Understanding在GSM8K数据集上提升了30%的准确率,在MultiArith上提升了45%,在SVAMP上则稳定提升了20-28%。这些结果相较于Chain-of-Thought、Self-Consistency和CoT-Decoding等基线方法具有显著优势,验证了AoU框架的有效性。
🎯 应用场景
该研究的潜在应用领域包括教育、自动问答系统和智能助手等,能够显著提升语言模型在复杂推理任务中的表现,减少错误信息的传播,增强用户信任。未来,AoU框架可能会在更多实际应用中得到推广,推动智能系统的可靠性和安全性。
📄 摘要(原文)
Large language models (LLMs) often generate reasoning traces that appear coherent but rest on unsupported assumptions, leading to hallucinated conclusions. Prior work mainly addresses factual hallucinations or relies on post-hoc verification, leaving reasoning-induced hallucinations largely unaddressed. We propose Audit-of-Understanding (AoU), a framework that constrains inference to validated premises through three phases: (1) decomposing a query into candidate assumptions, (2) auditing their support, and (3) conditioning inference only on the validated subset. Formally, AoU is \emph{posterior-constrained inference}, connecting to selective prediction and rejection learning. Our contributions are threefold: (i) theoretical guarantees under perfect validation, (ii) excess-risk bounds under imperfect audits, and (iii) tractability analysis. Empirically, AoU improves both accuracy and faithfulness on GSM8K, MultiArith, and SVAMP, achieving up to +30% gains on GSM8K, +45% on MultiArith, and consistent +20--28% improvements on SVAMP over Chain-of-Thought, Self-Consistency, and CoT-Decoding. Code is available at https://anonymous.4open.science/r/audit-of-understanding-E28B.