ImCoref-CeS: An Improved Lightweight Pipeline for Coreference Resolution with LLM-based Checker-Splitter Refinement
作者: Kangyang Luo, Yuzhuo Bai, Shuzheng Si, Cheng Gao, Zhitong Wang, Yingli Shen, Wenhao Li, Zhu Liu, Yufeng Han, Jiayi Wu, Cunliang Kong, Maosong Sun
分类: cs.CL, cs.IR
发布日期: 2025-10-11
💡 一句话要点
提出ImCoref-CeS框架,结合增强的监督模型与LLM推理,提升共指消解性能。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 共指消解 大型语言模型 监督学习 自然语言处理 文本理解 混合模型 推理 长文本处理
📋 核心要点
- 现有共指消解方法难以兼顾监督模型的高效和LLM的强大推理能力。
- ImCoref-CeS框架结合增强的监督模型ImCoref和LLM推理,实现更准确的共指消解。
- 实验表明,ImCoref-CeS优于现有SOTA方法,验证了框架的有效性。
📝 摘要(中文)
共指消解(CR)是自然语言处理(NLP)中的一项关键任务。当前研究面临一个关键困境:是进一步探索基于小型语言模型的监督神经方法(其detect-then-cluster流程仍然表现出色)的潜力,还是拥抱大型语言模型(LLM)的强大能力。然而,有效结合它们的优势仍未得到充分探索。为此,我们提出了ImCoref-CeS,这是一个新颖的框架,集成了增强的监督模型与基于LLM的推理。首先,我们提出了一种改进的CR方法(ImCoref),通过引入轻量级的桥接模块来增强长文本编码能力,设计一个双仿射评分器来全面捕获位置信息,并调用混合提及正则化来提高训练效率,从而突破了监督神经方法的性能界限。重要的是,我们使用LLM作为多角色Checker-Splitter代理,以验证ImCoref预测的候选提及(过滤掉无效的提及)和共指结果(拆分错误的聚类)。大量的实验表明了ImCoref-CeS的有效性,与现有的最先进(SOTA)方法相比,它实现了卓越的性能。
🔬 方法详解
问题定义:论文旨在解决共指消解任务中,现有方法要么依赖小型语言模型,性能提升有限,要么依赖大型语言模型,计算成本高昂的问题。现有方法难以有效结合两者的优势,导致在效率和准确性上无法达到最优。
核心思路:论文的核心思路是利用小型语言模型的高效性和大型语言模型的推理能力。首先,使用增强的监督模型ImCoref进行快速预测,然后利用LLM作为Checker-Splitter代理,对ImCoref的结果进行验证和修正,从而提高整体的准确性。
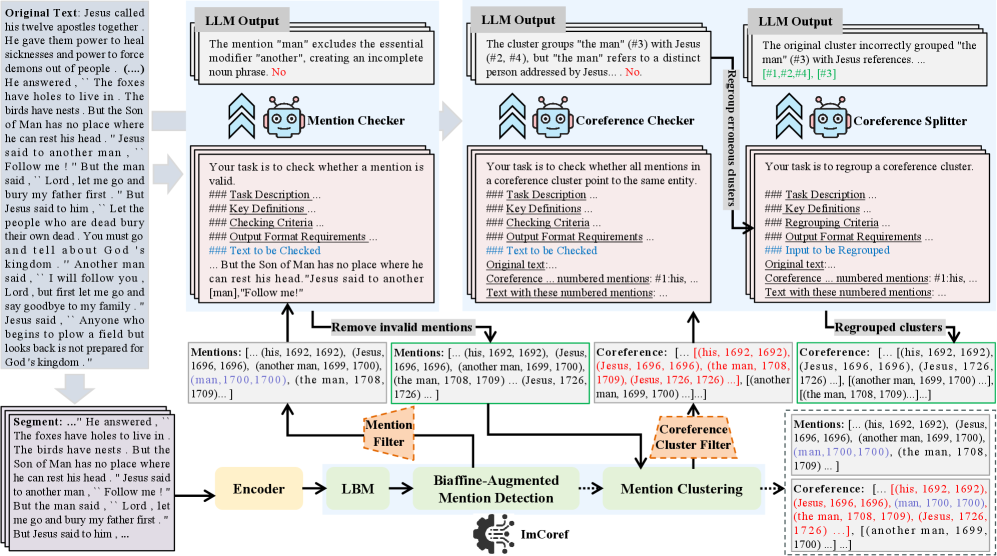
技术框架:ImCoref-CeS框架主要包含两个阶段:1) ImCoref阶段:使用增强的监督模型进行共指预测。2) LLM Checker-Splitter阶段:利用LLM对ImCoref的预测结果进行验证和修正。LLM首先作为Checker,过滤掉无效的提及,然后作为Splitter,拆分错误的共指簇。
关键创新:论文的关键创新在于将LLM引入到传统的监督学习流程中,并将其作为Checker-Splitter代理,用于验证和修正监督模型的预测结果。这种混合方法充分利用了小型语言模型的高效性和大型语言模型的推理能力,从而提高了整体的性能。
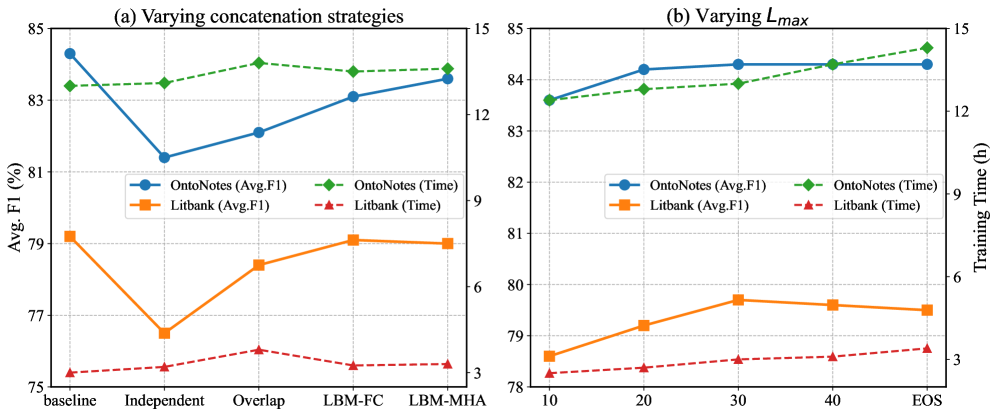
关键设计:ImCoref模型包含以下关键设计:1) 轻量级桥接模块,用于增强长文本编码能力。2) 双仿射评分器,用于全面捕获位置信息。3) 混合提及正则化,用于提高训练效率。LLM Checker-Splitter代理的设计需要仔细的prompt工程,以确保LLM能够有效地执行验证和修正任务。具体的参数设置和损失函数等细节在论文中进行了详细描述。
🖼️ 关键图片
📊 实验亮点
实验结果表明,ImCoref-CeS框架在共指消解任务上取得了显著的性能提升,超越了现有的SOTA方法。具体的性能数据在论文中进行了详细的展示,包括在多个benchmark数据集上的对比结果。通过与多种基线方法进行比较,验证了ImCoref-CeS框架的有效性和优越性。
🎯 应用场景
该研究成果可应用于信息抽取、文本摘要、问答系统、机器翻译等多个自然语言处理领域。通过提高共指消解的准确性,可以提升下游任务的性能,例如提高信息抽取系统的准确率,改善文本摘要的连贯性,以及提高问答系统的答案准确度。该方法在处理长文本时具有优势,因此在处理文档分析、报告生成等任务中具有潜在的应用价值。
📄 摘要(原文)
Coreference Resolution (CR) is a critical task in Natural Language Processing (NLP). Current research faces a key dilemma: whether to further explore the potential of supervised neural methods based on small language models, whose detect-then-cluster pipeline still delivers top performance, or embrace the powerful capabilities of Large Language Models (LLMs). However, effectively combining their strengths remains underexplored. To this end, we propose \textbf{ImCoref-CeS}, a novel framework that integrates an enhanced supervised model with LLM-based reasoning. First, we present an improved CR method (\textbf{ImCoref}) to push the performance boundaries of the supervised neural method by introducing a lightweight bridging module to enhance long-text encoding capability, devising a biaffine scorer to comprehensively capture positional information, and invoking a hybrid mention regularization to improve training efficiency. Importantly, we employ an LLM acting as a multi-role Checker-Splitter agent to validate candidate mentions (filtering out invalid ones) and coreference results (splitting erroneous clusters) predicted by ImCoref. Extensive experiments demonstrate the effectiveness of ImCoref-CeS, which achieves superior performance compared to existing state-of-the-art (SOTA) methods.