Text2Token: Unsupervised Text Representation Learning with Token Target Prediction
作者: Ruize An, Richong Zhang, Zhijie Nie, Zhanyu Wu, Yanzhao Zhang, Dingkun Long
分类: cs.CL, cs.IR
发布日期: 2025-10-11
💡 一句话要点
提出Text2Token框架,通过预测目标token实现无监督文本表示学习
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 无监督学习 文本表示学习 Token预测 自然语言处理 对比学习
📋 核心要点
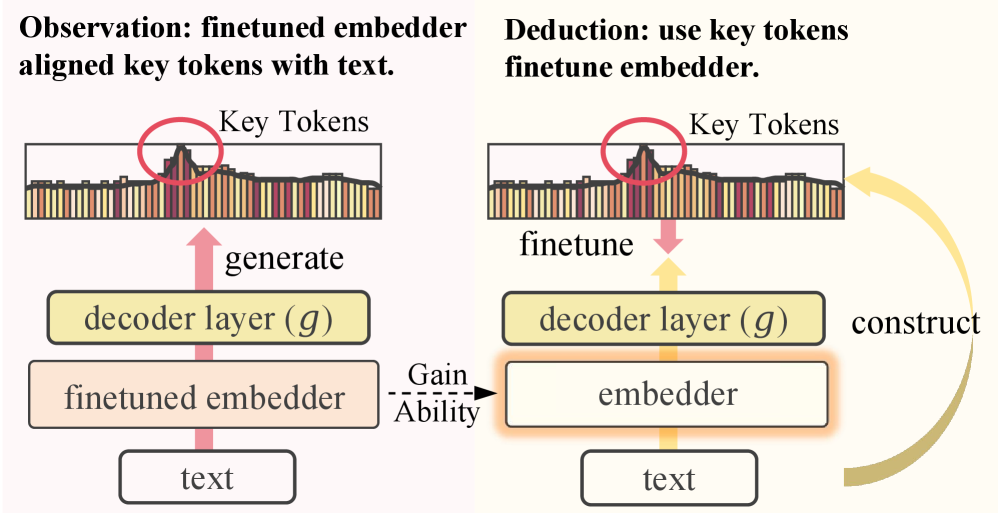
- 现有无监督文本表示学习方法难以有效对齐表示空间和词汇空间,导致表示质量受限。
- Text2Token框架通过预测目标token,利用精心构建的目标token分布作为监督信号,优化文本表示。
- 实验表明,Text2Token在MTEB v2基准上取得了与SOTA方法相当的性能,验证了其有效性。
📝 摘要(中文)
无监督文本表示学习(TRL)是自然语言处理中的一项基础任务,有利于利用网络上未标记的文本改进搜索和推荐。最近的一项实证研究发现,高质量的表示与输入文本的关键token对齐,揭示了表示空间和词汇空间之间的潜在联系。受此发现的启发,我们重新审视了生成任务,并为TRL开发了一个无监督生成框架Text2Token。该框架基于token目标预测任务,利用精心构建的目标token分布作为监督信号。为了构建高质量的目标token分布,我们分析了token与高级嵌入器的对齐属性,并确定了两个关键token类别:(1)文本中有意义的token和(2)文本之外语义衍生的token。基于这些见解,我们提出了两种方法——数据驱动和模型驱动——从数据或LLM骨干构建合成token目标。在MTEB v2基准上的实验表明,Text2Token实现了与最先进的无监督对比学习嵌入器LLM2Vec具有竞争力的性能。我们的分析进一步表明,词汇和表示空间在训练期间共同优化并朝着最优解发展,为未来的工作提供了新的思路和见解。
🔬 方法详解
问题定义:论文旨在解决无监督文本表示学习的问题。现有方法,如对比学习,虽然在无监督学习中取得了进展,但缺乏对表示空间和词汇空间之间关系的明确建模,可能导致学习到的表示与文本的关键语义信息不对齐。因此,如何有效地利用未标注文本学习高质量的文本表示是一个挑战。
核心思路:论文的核心思路是利用token目标预测任务,将文本表示学习转化为一个生成任务。通过预测与输入文本相关的目标token,迫使模型学习能够捕捉文本关键语义信息的表示。这种方法借鉴了生成模型的思想,但避免了直接生成文本的复杂性,而是专注于生成更易于控制和分析的token目标。
技术框架:Text2Token框架主要包含以下几个阶段:1) 输入文本经过编码器得到文本表示;2) 基于文本表示,预测目标token的分布;3) 使用预先构建的目标token分布作为监督信号,通过损失函数优化模型。目标token分布的构建有两种方式:数据驱动和模型驱动。数据驱动方法基于统计信息从数据中提取关键token,模型驱动方法则利用大型语言模型(LLM)生成语义相关的token。
关键创新:该论文的关键创新在于将文本表示学习问题转化为token目标预测问题,并提出了两种构建高质量目标token分布的方法。与传统的对比学习方法不同,Text2Token显式地建模了表示空间和词汇空间之间的关系,从而能够学习到更具语义信息的文本表示。此外,利用LLM生成目标token的方式,可以有效地扩展词汇空间,捕捉文本中隐含的语义信息。
关键设计:在目标token分布的构建方面,数据驱动方法主要依赖于统计信息,例如TF-IDF等,来选择文本中重要的token。模型驱动方法则利用LLM,例如GPT系列模型,基于输入文本生成语义相关的token。损失函数通常采用交叉熵损失,用于衡量预测的token分布与目标token分布之间的差异。编码器可以使用各种预训练语言模型,例如BERT、RoBERTa等。
🖼️ 关键图片


📊 实验亮点
Text2Token在MTEB v2基准测试中取得了与最先进的无监督对比学习方法LLM2Vec相当的性能。实验结果表明,通过token目标预测任务学习到的文本表示能够有效地捕捉文本的语义信息。此外,论文还分析了词汇空间和表示空间在训练过程中的优化情况,发现两者共同优化并朝着最优解发展。
🎯 应用场景
Text2Token框架可应用于各种自然语言处理任务,例如文本检索、文本分类、情感分析和推荐系统。通过学习高质量的文本表示,可以提高这些任务的性能。此外,该方法还可以用于构建更好的搜索引擎和推荐系统,从而改善用户体验。该研究为无监督文本表示学习提供了一种新的思路,具有重要的实际应用价值和未来研究潜力。
📄 摘要(原文)
Unsupervised text representation learning (TRL) is a fundamental task in natural language processing, which is beneficial for improving search and recommendations with the web's unlabeled texts. A recent empirical study finds that the high-quality representation aligns with the key token of the input text, uncovering the potential connection between representation space and vocabulary space. Inspired by the findings, we revisit the generative tasks and develop an unsupervised generative framework for TRL, Text2Token. The framework is based on the token target prediction task, utilizing carefully constructed target token distribution as supervisory signals. To construct the high-quality target token distribution, we analyze the token-alignment properties with advanced embedders and identify two essential categories of key tokens: (1) the meaningful tokens in the text and (2) semantically derived tokens beyond the text. Based on these insights, we propose two methods -- data-driven and model-derived -- to construct synthetic token targets from data or the LLM backbone. Experiments on the MTEB v2 benchmark demonstrate that Text2Token achieves performance competitive with the state-of-the-art embedder with unsupervised contrastive learning, LLM2Vec. Our analysis further shows that vocabulary and representation spaces optimize together and toward the optimum solution during training, providing new ideas and insights for future work.