A Survey of Inductive Reasoning for Large Language Models
作者: Kedi Chen, Dezhao Ruan, Yuhao Dan, Yaoting Wang, Siyu Yan, Xuecheng Wu, Yinqi Zhang, Qin Chen, Jie Zhou, Liang He, Biqing Qi, Linyang Li, Qipeng Guo, Xiaoming Shi, Wei Zhang
分类: cs.CL, cs.AI
发布日期: 2025-10-11
💡 一句话要点
对大型语言模型中的归纳推理进行综述,并提出统一的评估方法。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 归纳推理 知识泛化 推理能力 评估方法
📋 核心要点
- 现有大型语言模型在归纳推理方面缺乏系统性的研究和总结,阻碍了该领域的发展。
- 本文对大型语言模型的归纳推理进行了全面综述,涵盖了改进方法、基准测试和评估方法。
- 论文提出了一个统一的基于沙箱的评估方法,并使用观察覆盖率指标来评估归纳推理能力。
📝 摘要(中文)
推理是大型语言模型(LLMs)的重要任务。在所有推理范式中,归纳推理是最基本的类型之一,其特点是从特殊到一般的思维过程以及答案的非唯一性。归纳模式对于知识泛化至关重要,并且更符合人类认知,因此是一种基本的学习模式,从而引起了越来越多的兴趣。尽管归纳推理很重要,但目前还没有对其进行系统的总结。因此,本文首次对LLM的归纳推理进行了全面的综述。首先,将改进归纳推理的方法分为三个主要领域:后训练、测试时缩放和数据增强。然后,总结了当前的归纳推理基准,并推导出一种基于沙箱的统一评估方法,以及观察覆盖率指标。最后,我们对归纳能力的来源以及简单的模型架构和数据如何帮助完成归纳任务进行了一些分析,为未来的研究奠定了坚实的基础。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLMs)中归纳推理能力缺乏系统性研究的问题。现有方法在评估和提升LLMs的归纳推理能力方面存在不足,缺乏统一的评估标准和有效的改进策略。
核心思路:论文的核心思路是对现有关于LLMs归纳推理的研究进行系统性的梳理和总结,并提出一个统一的评估框架,以便更好地理解和提升LLMs的归纳推理能力。通过对现有方法的分类、基准测试的总结和评估方法的提出,为未来的研究提供基础。
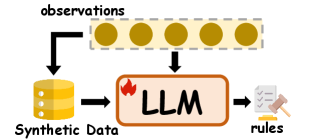
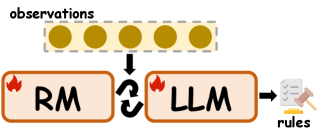
技术框架:论文的整体框架包括三个主要部分:1) 归纳推理改进方法分类,包括后训练、测试时缩放和数据增强;2) 归纳推理基准测试总结;3) 提出基于沙箱的统一评估方法,并使用观察覆盖率指标。
关键创新:论文的关键创新在于提出了一个统一的基于沙箱的评估方法,用于评估LLMs的归纳推理能力。该方法通过观察覆盖率指标来衡量模型在推理过程中的表现,从而更全面地评估模型的归纳能力。此外,对现有方法的分类和基准测试的总结也为研究人员提供了有价值的参考。
关键设计:论文提出的基于沙箱的评估方法,其关键设计在于构建一个可控的实验环境(沙箱),并在该环境中观察LLM的推理过程。观察覆盖率指标用于衡量模型在推理过程中对不同情况的覆盖程度。具体的参数设置和网络结构等技术细节取决于具体的LLM和归纳推理任务,论文主要关注评估框架的设计。
🖼️ 关键图片

📊 实验亮点
论文提出了一个统一的基于沙箱的评估方法,并使用观察覆盖率指标来评估归纳推理能力。通过该方法,可以更全面地评估LLMs在不同归纳推理任务上的表现,并为未来的研究提供一个标准化的评估框架。具体的性能数据和提升幅度需要在具体的实验中进行验证。
🎯 应用场景
该研究成果可应用于提升大型语言模型在知识泛化、常识推理和问题解决等领域的性能。通过更有效地评估和改进LLMs的归纳推理能力,可以使其在实际应用中更好地模拟人类的认知过程,从而在智能客服、自动驾驶、医疗诊断等领域发挥更大的作用。
📄 摘要(原文)
Reasoning is an important task for large language models (LLMs). Among all the reasoning paradigms, inductive reasoning is one of the fundamental types, which is characterized by its particular-to-general thinking process and the non-uniqueness of its answers. The inductive mode is crucial for knowledge generalization and aligns better with human cognition, so it is a fundamental mode of learning, hence attracting increasing interest. Despite the importance of inductive reasoning, there is no systematic summary of it. Therefore, this paper presents the first comprehensive survey of inductive reasoning for LLMs. First, methods for improving inductive reasoning are categorized into three main areas: post-training, test-time scaling, and data augmentation. Then, current benchmarks of inductive reasoning are summarized, and a unified sandbox-based evaluation approach with the observation coverage metric is derived. Finally, we offer some analyses regarding the source of inductive ability and how simple model architectures and data help with inductive tasks, providing a solid foundation for future research.