Debiasing LLMs by Masking Unfairness-Driving Attention Heads
作者: Tingxu Han, Wei Song, Ziqi Ding, Ziming Li, Chunrong Fang, Yuekang Li, Dongfang Liu, Zhenyu Chen, Zhenting Wang
分类: cs.CL, cs.AI
发布日期: 2025-10-11 (更新: 2025-11-02)
💡 一句话要点
DiffHeads:通过屏蔽不公平驱动的注意力头来消除LLM的偏见
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 偏见消除 注意力机制 提示工程 公平性
📋 核心要点
- 现有方法缺乏对LLM偏见产生机制的深入理解,导致去偏措施脆弱且缺乏针对性。
- DiffHeads通过分析不同提示策略下注意力头的激活差异,识别并屏蔽导致偏见的特定注意力头。
- 实验表明,DiffHeads在降低LLM偏见的同时,保持了模型的实用性,实现了显著的去偏效果。
📝 摘要(中文)
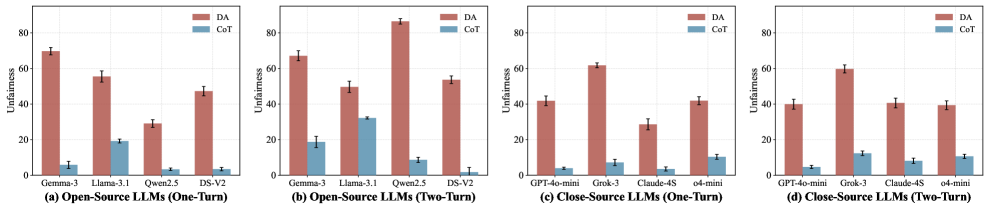
大型语言模型(LLM)越来越多地参与到一些决策领域,而在这些领域中,对不同人口群体的不公平待遇是不可接受的。现有的工作主要集中在探究何时会出现有偏见的输出,但很少深入了解产生这些偏见的机制,使得现有的缓解措施大多比较脆弱。本文对LLM的不公平性进行了系统的研究,并提出了DiffHeads,一个轻量级的LLM去偏框架。首先,我们比较了直接回答(DA)提示和思维链(CoT)提示在八个具有代表性的开源和闭源LLM上的表现。DA会触发LLM的自然偏见部分,并在单轮和双轮对话中将测量到的不公平性提高534.5%-391.9%。其次,我们定义了一个token-to-head贡献分数,将每个token的影响追溯到单个注意力头。这揭示了一小部分偏见头,这些偏见头在DA下激活,但在CoT下基本处于休眠状态,从而提供了提示策略和偏见产生之间的第一个因果关系。最后,基于这一洞察,我们提出了DiffHeads,它通过DA和CoT之间的差异激活分析来识别偏见头,并有选择地屏蔽这些头。DiffHeads在DA和CoT下分别减少了49.4%和40.3%的不公平性,而不会损害模型的效用。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)中存在的偏见问题,特别是当LLM被用于决策领域时,对不同人口群体的不公平待遇是不可接受的。现有方法主要集中在检测何时出现有偏见的输出,但缺乏对偏见产生机制的深入理解,导致去偏措施效果有限且缺乏鲁棒性。现有方法难以确定哪些模型组件(例如注意力头)是导致偏见的关键因素。
核心思路:论文的核心思路是通过比较不同提示策略(Direct-Answer和Chain-of-Thought)下LLM内部注意力头的激活情况,来识别并定位导致偏见的特定注意力头。作者认为,某些注意力头在直接回答提示下会表现出更高的激活水平,从而导致偏见产生。通过选择性地屏蔽这些注意力头,可以有效地降低LLM的偏见。
技术框架:DiffHeads框架主要包含以下几个阶段:1) 使用Direct-Answer (DA) 和 Chain-of-Thought (CoT) 两种提示策略来提示LLM;2) 定义token-to-head贡献分数,用于衡量每个token对每个注意力头的影响;3) 通过比较DA和CoT两种提示策略下注意力头的激活差异,识别出偏见头;4) 选择性地屏蔽识别出的偏见头。
关键创新:该论文最重要的技术创新点在于提出了通过差异激活分析来识别LLM中导致偏见的特定注意力头的方法。与以往的去偏方法不同,DiffHeads不是简单地对整个模型进行调整,而是有针对性地屏蔽那些与偏见产生直接相关的注意力头。这种方法更加高效,并且能够在降低偏见的同时,保持模型的实用性。
关键设计:关键设计包括:1) token-to-head贡献分数的计算方法,用于衡量每个token对每个注意力头的影响;2) 差异激活分析的具体实现,包括如何定义和计算注意力头在不同提示策略下的激活差异;3) 偏见头的选择策略,例如设置一个阈值来确定哪些注意力头应该被屏蔽;4) 屏蔽操作的具体实现,例如将偏见头的输出设置为零。
🖼️ 关键图片


📊 实验亮点
DiffHeads在八个代表性的LLM上进行了评估,实验结果表明,DiffHeads在DA和CoT提示下分别减少了49.4%和40.3%的不公平性,同时没有显著降低模型的效用。这表明DiffHeads是一种有效的LLM去偏方法,能够在降低偏见的同时,保持模型的性能。
🎯 应用场景
DiffHeads具有广泛的应用前景,可以应用于各种需要使用LLM进行决策的领域,例如招聘、信贷评估、法律咨询等。通过降低LLM的偏见,DiffHeads可以帮助确保决策的公平性和公正性,避免对特定人群造成歧视。此外,DiffHeads还可以用于提高LLM的可解释性,帮助人们理解LLM做出决策的原因。
📄 摘要(原文)
Large language models (LLMs) increasingly mediate decisions in domains where unfair treatment of demographic groups is unacceptable. Existing work probes when biased outputs appear, but gives little insight into the mechanisms that generate them, leaving existing mitigations largely fragile. In this paper, we conduct a systematic investigation LLM unfairness and propose DiffHeads, a lightweight debiasing framework for LLMs. We first compare Direct-Answer (DA) prompting to Chain-of-Thought (CoT) prompting across eight representative open- and closed-source LLMs. DA will trigger the nature bias part of LLM and improve measured unfairness by 534.5%-391.9% in both one-turn and two-turn dialogues. Next, we define a token-to-head contribution score that traces each token's influence back to individual attention heads. This reveals a small cluster of bias heads that activate under DA but stay largely dormant with CoT, providing the first causal link between prompting strategy and bias emergence. Finally, building on this insight, we propose DiffHeads that identifies bias heads through differential activation analysis between DA and CoT, and selectively masks only those heads. DiffHeads reduces unfairness by 49.4%, and 40.3% under DA and CoT, respectively, without harming model utility.