Hybrid OCR-LLM Framework for Enterprise-Scale Document Information Extraction Under Copy-heavy Task
作者: Zilong Wang, Xiaoyu Shen
分类: cs.CL, cs.AI
发布日期: 2025-10-11
💡 一句话要点
提出混合OCR-LLM框架,解决企业级海量重复文档的信息抽取难题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: OCR 大型语言模型 信息抽取 文档处理 自适应框架
📋 核心要点
- 现有方法在处理企业级海量重复文档的信息抽取任务时,缺乏针对性的优化策略,难以兼顾精度和效率。
- 该框架的核心思想是结合OCR引擎和LLM,并根据文档特征智能选择抽取策略,从而优化精度和效率的平衡。
- 实验结果表明,该框架在身份文档抽取任务中表现出色,F1值接近1.0,处理速度达到亚秒级,性能提升显著。
📝 摘要(中文)
本文提出了一种系统性的框架,该框架巧妙地结合了OCR引擎与大型语言模型(LLM),旨在优化企业文档处理中大量结构相似文档的信息抽取任务的精度-效率权衡。与追求通用解决方案的现有方法不同,我们的方法通过智能策略选择来利用文档的特定特征。我们在四种格式(PNG、DOCX、XLSX、PDF)的身份文档上,通过三种抽取范式(直接抽取、替换抽取和基于表格的抽取)实现了25种配置。通过基于表格的抽取方法,我们的自适应框架提供了出色的结果:对于结构化文档,F1值为1.0,延迟为0.97秒;对于具有挑战性的图像输入,与PaddleOCR集成时,F1值为0.997,延迟为0.6秒,同时保持亚秒级的处理速度。与多模态方法相比,性能提高了54倍,加上格式感知路由,能够以生产规模处理异构文档流。除了身份抽取这一特定应用,这项工作还确立了一个普遍原则:通过结构感知的方法选择,可以将重复性任务从计算负担转变为优化机会。
🔬 方法详解
问题定义:企业级文档处理面临海量重复文档的信息抽取难题,这些文档结构相似但数量巨大。现有方法通常采用通用解决方案,忽略了文档的特定特征,导致在精度和效率上难以达到最优。痛点在于无法有效利用文档的重复性结构来加速抽取过程,并且难以处理各种文档格式带来的挑战。
核心思路:核心思路是利用文档的重复性结构,通过智能策略选择,将OCR引擎和LLM结合起来,针对不同文档格式和抽取任务选择最优的配置。这种方法旨在将重复性任务从计算负担转变为优化机会,从而在精度和效率之间取得更好的平衡。
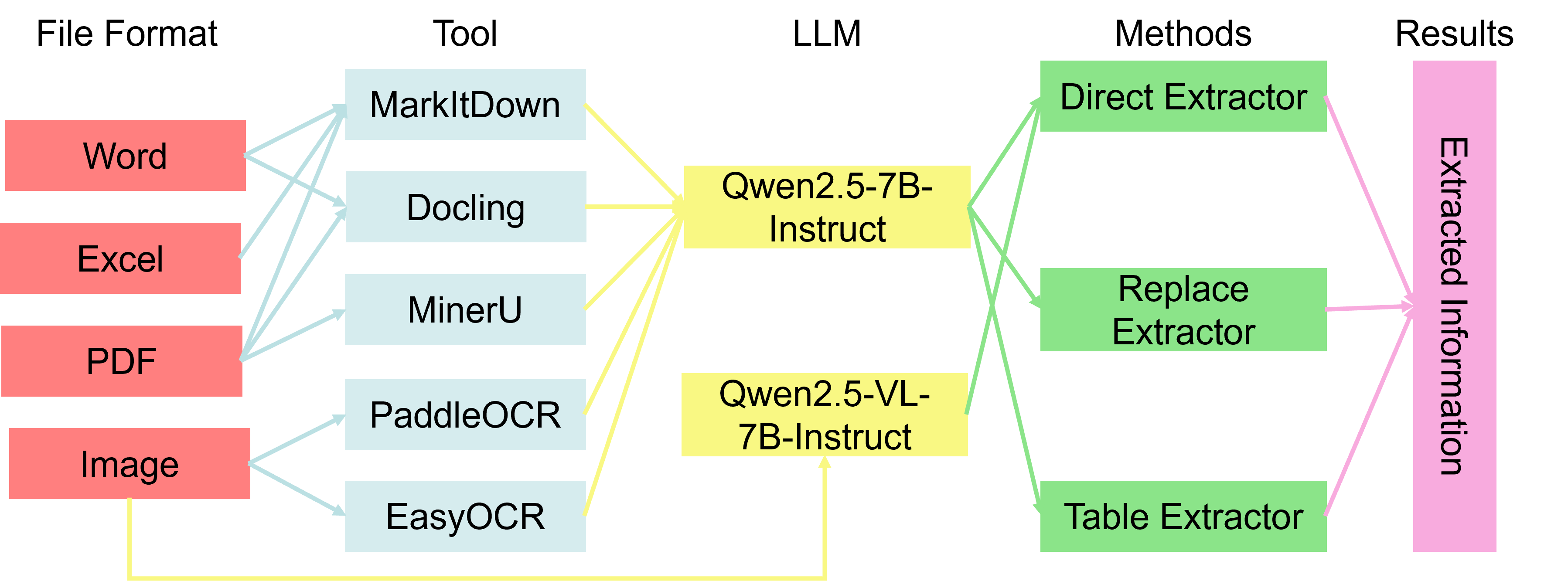
技术框架:整体框架包含以下几个主要模块:1) 文档格式识别模块,用于识别输入文档的格式(如PNG、DOCX、XLSX、PDF);2) 抽取策略选择模块,根据文档格式和抽取任务选择合适的抽取范式(直接抽取、替换抽取、基于表格的抽取)和OCR引擎/LLM配置;3) 信息抽取模块,根据选定的策略和配置,利用OCR引擎和LLM进行信息抽取;4) 结果整合模块,将抽取结果进行整合和后处理,输出最终结果。
关键创新:最重要的技术创新点在于提出了一个自适应的混合OCR-LLM框架,该框架能够根据文档的特定特征(如格式、结构)智能选择最优的抽取策略和配置。与现有方法相比,该框架能够更好地利用文档的重复性结构,从而在精度和效率上取得更好的平衡。此外,该框架还支持多种抽取范式和OCR引擎/LLM配置,具有很强的灵活性和可扩展性。
关键设计:框架的关键设计包括:1) 抽取策略选择模块的设计,需要考虑多种因素,如文档格式、抽取任务、OCR引擎/LLM的性能等;2) OCR引擎和LLM的集成方式,需要选择合适的集成策略,以充分发挥两者的优势;3) 实验中使用了PaddleOCR作为OCR引擎,并针对不同的文档格式和抽取任务进行了参数调优;4) 评估指标包括F1值和延迟,用于衡量框架的精度和效率。
🖼️ 关键图片


📊 实验亮点
实验结果表明,该框架在身份文档抽取任务中表现出色。对于结构化文档,F1值为1.0,延迟为0.97秒;对于具有挑战性的图像输入,与PaddleOCR集成时,F1值为0.997,延迟为0.6秒,同时保持亚秒级的处理速度。与多模态方法相比,性能提高了54倍,显著提升了文档处理效率。
🎯 应用场景
该研究成果可广泛应用于企业级文档处理领域,例如身份信息抽取、财务报表分析、合同管理等。通过该框架,企业可以高效地从海量重复文档中提取关键信息,提高工作效率,降低运营成本。未来,该框架还可以扩展到其他类型的文档和抽取任务,具有广阔的应用前景。
📄 摘要(原文)
Information extraction from copy-heavy documents, characterized by massive volumes of structurally similar content, represents a critical yet understudied challenge in enterprise document processing. We present a systematic framework that strategically combines OCR engines with Large Language Models (LLMs) to optimize the accuracy-efficiency trade-off inherent in repetitive document extraction tasks. Unlike existing approaches that pursue universal solutions, our method exploits document-specific characteristics through intelligent strategy selection. We implement and evaluate 25 configurations across three extraction paradigms (direct, replacement, and table-based) on identity documents spanning four formats (PNG, DOCX, XLSX, PDF). Through table-based extraction methods, our adaptive framework delivers outstanding results: F1=1.0 accuracy with 0.97s latency for structured documents, and F1=0.997 accuracy with 0.6 s for challenging image inputs when integrated with PaddleOCR, all while maintaining sub-second processing speeds. The 54 times performance improvement compared with multimodal methods over naive approaches, coupled with format-aware routing, enables processing of heterogeneous document streams at production scale. Beyond the specific application to identity extraction, this work establishes a general principle: the repetitive nature of copy-heavy tasks can be transformed from a computational burden into an optimization opportunity through structure-aware method selection.