Stop When Enough: Adaptive Early-Stopping for Chain-of-Thought Reasoning
作者: Renliang Sun, Wei Cheng, Dawei Li, Haifeng Chen, Wei Wang
分类: cs.CL
发布日期: 2025-10-11
💡 一句话要点
提出REFRAIN框架以解决链式思维推理中的过度思考问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 链式思维推理 自适应推理 多臂老虎机 推理效率 自然语言处理
📋 核心要点
- 现有的链式思维推理方法容易导致过度思考,增加推理成本并可能得出错误结论。
- REFRAIN框架通过自适应判断停止推理,结合两阶段停止判别器和SW-UCB控制器,有效减轻冗余推理。
- 在多个基准测试中,REFRAIN显著减少了标记使用,同时保持或提升了模型的推理准确性。
📝 摘要(中文)
链式思维推理(CoT)通过外部化中间步骤,推动了大型语言模型(LLMs)在推理密集型任务上的进展。然而,过度或冗余的推理会增加推理成本并导致错误结论。本文提出REFRAIN(反思冗余的自适应推理),这是一个无训练的框架,能够自适应地判断何时停止推理,以减轻过度思考。REFRAIN集成了两阶段停止判别器,以识别反思性但冗余的推理,并使用滑动窗口上置信界(SW-UCB)多臂老虎机控制器,根据问题难度动态调整停止阈值。实验结果表明,REFRAIN在四个基准测试和两个模型家族中,减少了20-55%的标记使用,同时保持或提高了准确性。
🔬 方法详解
问题定义:本文旨在解决链式思维推理中的过度思考问题,现有方法在推理过程中可能产生冗余步骤,导致推理成本增加和错误结论。
核心思路:REFRAIN框架通过自适应地判断何时停止推理,避免冗余推理。设计上结合了反思性和动态调整的机制,以提高推理效率。
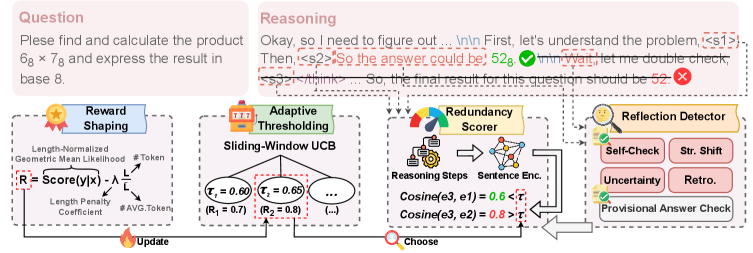
技术框架:REFRAIN的整体架构包括两个主要模块:一是两阶段停止判别器,用于识别冗余推理;二是SW-UCB多臂老虎机控制器,根据问题难度动态调整停止阈值。
关键创新:REFRAIN的核心创新在于其无训练的自适应停止机制,能够在推理过程中实时判断停止时机,与传统方法相比,显著提高了推理效率。
关键设计:REFRAIN采用滑动窗口策略来实现多臂老虎机控制,关键参数设置包括停止阈值的动态调整机制,确保在不同问题难度下的适应性。
🖼️ 关键图片

📊 实验亮点
实验结果显示,REFRAIN在四个基准测试中减少了20-55%的标记使用,同时在准确性上保持或提升了性能。这一结果表明REFRAIN在推理效率和准确性之间取得了良好的平衡。
🎯 应用场景
该研究的潜在应用领域包括自然语言处理、智能问答系统和自动推理等。通过提高推理效率,REFRAIN能够在实际应用中降低计算资源消耗,提升用户体验,具有重要的实际价值和未来影响。
📄 摘要(原文)
Chain-of-Thought (CoT) reasoning has driven recent gains of large language models (LLMs) on reasoning-intensive tasks by externalizing intermediate steps. However, excessive or redundant reasoning -- so-called overthinking -- can increase inference costs and lead LLMs toward incorrect conclusions. In this paper, we present REFRAIN ($\underline{REF}$lective-$\underline{R}$edundancy for $\underline{A}$daptive $\underline{IN}$ference), a training-free framework that adaptively determines when to stop reasoning to mitigate overthinking. REFRAIN integrates a two-stage stop discriminator to identify reflective yet redundant reasoning and a sliding-window Upper Confidence Bound (SW-UCB) multi-armed bandit controller to dynamically adjust stopping thresholds according to problem difficulty without supervision or fine-tuning. Across four representative benchmarks and two model families, REFRAIN reduces token usage by 20-55% while maintaining or improving accuracy compared to standard CoT prompting. Extensive ablation and robustness analyses demonstrate its stability across models, scorers, and prompt variations. In summary, our findings highlight when-to-stop as a new and practical axis of test-time scaling -- enabling models to reason not just more, but just enough.