Enhancing Faithfulness in Abstractive Summarization via Span-Level Fine-Tuning
作者: Sicong Huang, Qianqi Yan, Shengze Wang, Ian Lane
分类: cs.CL
发布日期: 2025-10-10
💡 一句话要点
提出基于Span级别微调的抽象摘要方法,提升生成摘要的忠实度
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 抽象摘要 忠实度 幻觉检测 Span级别标注 微调 非似然训练 GPT-4o 自然语言生成
📋 核心要点
- 现有抽象摘要模型易产生幻觉,导致生成内容不忠实于原文,后处理和对比学习等方法难以有效解决。
- 论文提出基于Span级别标注的微调策略,利用GPT-4o检测并标注摘要中的幻觉Span,从而提升模型忠实度。
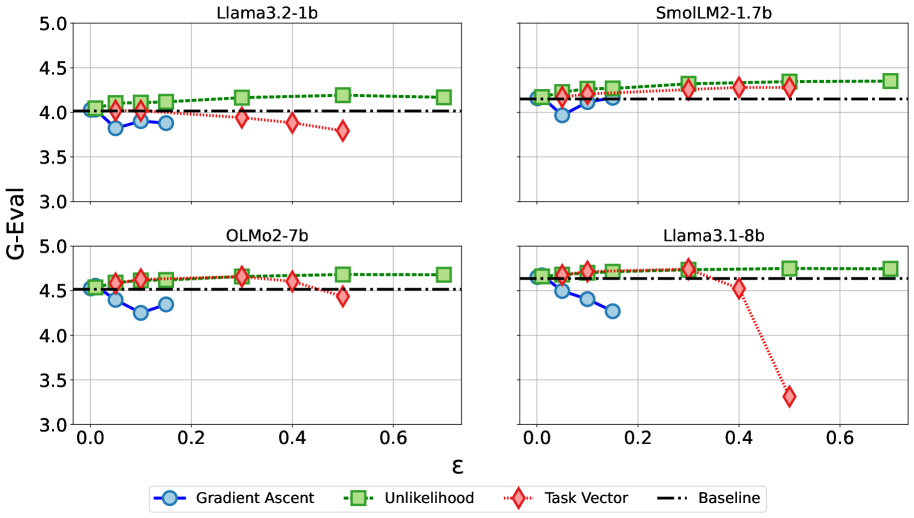
- 实验结果表明,梯度上升、非似然训练和任务向量否定均能有效利用Span级别标注,提升摘要忠实度,其中非似然训练效果最佳。
📝 摘要(中文)
使用大型语言模型(LLM)的抽象摘要已成为信息浓缩的重要工具。然而,尽管这些模型能够生成流畅的摘要,但有时会产生不忠实的摘要,在单词、短语或概念层面引入幻觉。现有的缓解策略,如后处理校正或使用合成生成的负样本进行对比学习,未能完全解决LLM生成的摘要中可能发生的各种错误。本文研究了微调策略,以减少生成的摘要中不忠实Span的出现。首先,我们使用各种LLM自动为训练集中的源文档集生成摘要,然后使用GPT-4o注释其检测到的Span级别的任何幻觉。利用这些注释,我们使用无幻觉摘要和带注释的不忠实Span来微调LLM,以提高模型忠实度。在本文中,我们引入了一个新的数据集,其中包含带有Span级别标签的忠实和不忠实摘要,并且我们评估了三种微调LLM的技术,以提高生成的摘要的忠实度:梯度上升、非似然训练和任务向量否定。实验结果表明,所有三种方法都成功地利用Span级别注释来提高忠实度,其中非似然训练最有效。
🔬 方法详解
问题定义:论文旨在解决抽象摘要生成中,大型语言模型(LLM)容易产生幻觉,导致生成摘要不忠实于原文的问题。现有方法,如后处理校正和对比学习,无法有效应对各种类型的幻觉错误,缺乏细粒度的指导。
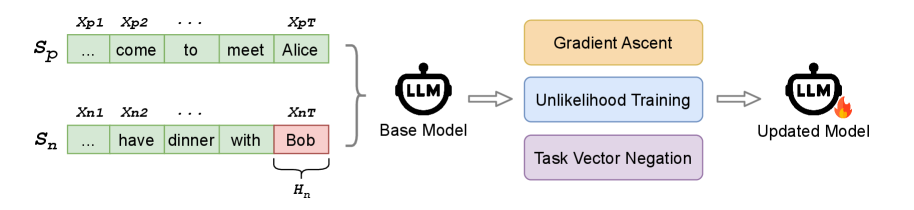
核心思路:核心思路是利用Span级别的标注信息,对LLM进行微调,从而让模型学习区分忠实和不忠实的Span。通过显式地标注摘要中的幻觉Span,模型可以更有效地学习如何避免生成不忠实的内容。
技术框架:整体框架包含以下几个步骤:1) 使用不同的LLM为训练集生成摘要;2) 使用GPT-4o自动检测并标注生成的摘要中存在的Span级别的幻觉;3) 使用标注好的数据,采用不同的微调策略(梯度上升、非似然训练、任务向量否定)对LLM进行微调;4) 评估微调后的模型在摘要忠实度上的表现。
关键创新:关键创新在于引入了Span级别的幻觉标注,并将其用于指导LLM的微调。这种细粒度的标注信息能够更有效地帮助模型学习避免生成不忠实的内容。此外,论文还探索了多种不同的微调策略,并比较了它们的效果。
关键设计:论文的关键设计包括:1) 使用GPT-4o进行Span级别的幻觉标注;2) 探索了三种不同的微调策略:梯度上升(gradient ascent)、非似然训练(unlikelihood training)和任务向量否定(task vector negation)。非似然训练通过降低模型生成不忠实Span的概率来提升忠实度。具体的技术细节,例如损失函数的设计,在论文中应该有更详细的描述(未知)。
🖼️ 关键图片

📊 实验亮点
实验结果表明,所有三种微调方法(梯度上升、非似然训练、任务向量否定)都能够有效利用Span级别的标注信息,提升摘要的忠实度。其中,非似然训练表现最佳。具体的性能提升数据和对比基线需要在论文中查找(未知)。该研究证明了Span级别标注在提升摘要忠实度方面的有效性。
🎯 应用场景
该研究成果可应用于各种需要高质量摘要的场景,例如新闻摘要、文档摘要、会议记录摘要等。提升摘要的忠实度可以减少信息失真,提高用户对摘要内容的信任度,具有重要的实际应用价值。未来,该方法可以进一步推广到其他自然语言生成任务中,例如机器翻译、对话生成等。
📄 摘要(原文)
Abstractive summarization using large language models (LLMs) has become an essential tool for condensing information. However, despite their ability to generate fluent summaries, these models sometimes produce unfaithful summaries, introducing hallucinations at the word, phrase, or concept level. Existing mitigation strategies, such as post-processing corrections or contrastive learning with synthetically generated negative samples, fail to fully address the diverse errors that can occur in LLM-generated summaries. In this paper, we investigate fine-tuning strategies to reduce the occurrence of unfaithful spans in generated summaries. First, we automatically generate summaries for the set of source documents in the training set with a variety of LLMs and then use GPT-4o to annotate any hallucinations it detects at the span-level. Leveraging these annotations, we fine-tune LLMs with both hallucination-free summaries and annotated unfaithful spans to enhance model faithfulness. In this paper, we introduce a new dataset that contains both faithful and unfaithful summaries with span-level labels and we evaluate three techniques to fine-tuning a LLM to improve the faithfulness of the resulting summarization: gradient ascent, unlikelihood training, and task vector negation. Experimental results show that all three approaches successfully leverage span-level annotations to improve faithfulness, with unlikelihood training being the most effective.