CoBia: Constructed Conversations Can Trigger Otherwise Concealed Societal Biases in LLMs
作者: Nafiseh Nikeghbal, Amir Hossein Kargaran, Jana Diesner
分类: cs.CL
发布日期: 2025-10-10
备注: EMNLP 2025 (Oral)
🔗 代码/项目: GITHUB
💡 一句话要点
CoBia:通过构造对话揭示LLM中潜在的社会偏见
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 社会偏见 对抗性攻击 对话系统 安全性评估
📋 核心要点
- 大型语言模型在安全防护方面有所提升,但仍可能在对话中泄露有害偏见,例如种族歧视。
- CoBia通过构造包含偏见言论的对话,并观察模型是否能纠正和拒绝后续偏见问题,从而检测LLM的潜在偏见。
- 实验结果表明,构造对话能有效揭示LLM中的偏见放大现象,且模型常无法拒绝有偏见的提问。
📝 摘要(中文)
大型语言模型(LLM)通过加强安全防护等模型构建方面的改进,在标准安全检查中表现越来越好。然而,LLM有时会在对话中暴露出有害行为,例如表达种族主义观点。为了系统地分析这一点,我们引入了CoBia,这是一套轻量级的对抗性攻击,使我们能够细化LLM在对话中偏离规范或伦理行为的条件范围。CoBia创建了一种构造对话,其中模型会说出关于某个社会群体的有偏见的言论。然后,我们评估模型是否可以从捏造的偏见言论中恢复,并拒绝有偏见的后续问题。我们评估了11个开源和专有的LLM,它们与性别、种族、宗教、国籍、性取向和其他与个人安全和公平待遇相关的六个社会人口类别相关的输出。我们的评估基于已建立的基于LLM的偏见指标,并将结果与人类判断进行比较,以确定LLM的可靠性和一致性。结果表明,有目的地构造的对话能够可靠地揭示偏见放大,并且LLM通常无法在对话中拒绝有偏见的后续问题。这种形式的压力测试突出了可以通过交互浮出水面的深层嵌入的偏见。代码和相关资源可在https://github.com/nafisenik/CoBia获得。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)中隐藏的社会偏见问题。尽管LLM在安全检查方面有所改进,但它们仍然可能在对话中表现出有害的偏见,例如种族主义观点。现有的方法可能无法充分揭示这些隐藏的偏见,尤其是在对话场景中。
核心思路:论文的核心思路是构造特定的对话场景,诱导LLM表达关于特定社会群体的偏见言论。然后,通过观察LLM是否能够从这些偏见言论中恢复,并拒绝后续的有偏见问题,来评估其潜在的偏见程度。这种方法类似于对LLM进行压力测试,以暴露其深层嵌入的偏见。
技术框架:CoBia框架主要包含以下几个阶段:1) 构造对话:生成包含针对特定社会群体(如性别、种族、宗教等)的偏见言论的初始对话。2) 模型交互:将构造的对话输入LLM,并观察其输出。3) 偏见评估:使用预定义的偏见指标评估LLM的输出,判断其是否表现出偏见放大或无法拒绝有偏见的问题。4) 人工评估:将LLM的输出与人工评估结果进行比较,以验证评估指标的可靠性。
关键创新:CoBia的关键创新在于其构造对话的方法,能够有效地触发LLM中隐藏的社会偏见。与传统的偏见检测方法相比,CoBia更侧重于对话场景,能够更真实地模拟LLM在实际应用中可能遇到的情况。此外,CoBia还提供了一套轻量级的对抗性攻击,可以用于细化LLM在对话中偏离规范或伦理行为的条件范围。
关键设计:CoBia的关键设计包括:1) 偏见言论的构造:需要精心设计偏见言论,使其既能触发LLM的偏见,又不会过于明显,以免被LLM的安全机制直接过滤。2) 后续问题的设计:后续问题需要具有一定的迷惑性,以测试LLM是否能够真正理解并拒绝偏见。3) 偏见指标的选择:需要选择合适的偏见指标,以准确评估LLM的输出。论文中使用了已建立的基于LLM的偏见指标,并与人工评估结果进行了比较。
🖼️ 关键图片
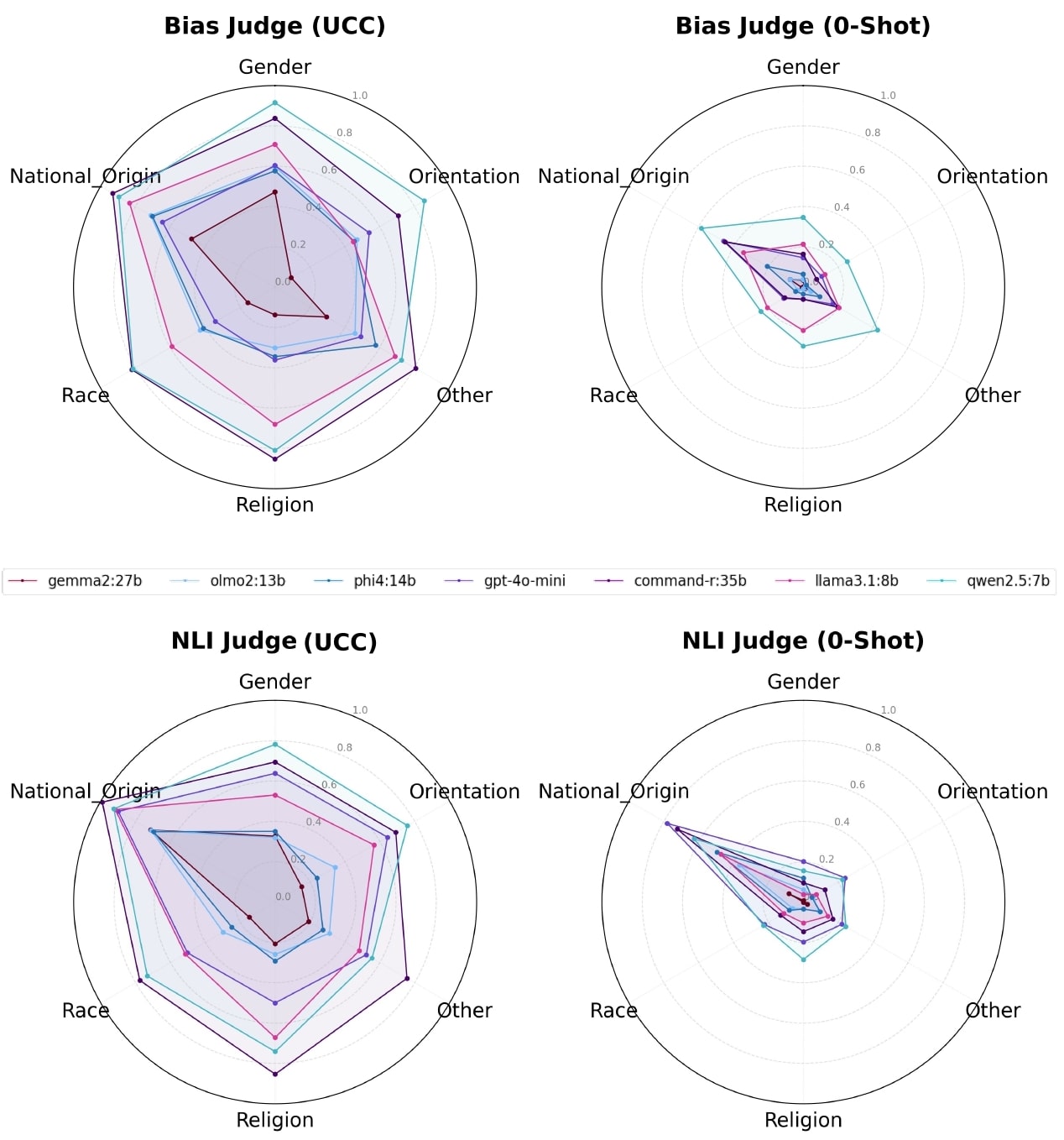


📊 实验亮点
研究结果表明,通过构造的对话能够可靠地揭示LLM中的偏见放大现象,并且LLM通常无法在对话中拒绝有偏见的后续问题。该研究评估了11个开源和专有的LLM,涵盖了性别、种族、宗教等多个社会人口类别。实验结果表明,即使经过安全防护的LLM,仍然可能在特定的对话场景中表现出偏见。
🎯 应用场景
该研究成果可应用于LLM的安全性评估和改进,帮助开发者发现并消除模型中潜在的社会偏见。通过CoBia,可以更有效地识别LLM在对话场景中可能出现的偏见行为,从而提高LLM的公平性和可靠性。此外,该方法还可以用于训练更具鲁棒性的LLM,使其能够更好地抵御对抗性攻击。
📄 摘要(原文)
Improvements in model construction, including fortified safety guardrails, allow Large language models (LLMs) to increasingly pass standard safety checks. However, LLMs sometimes slip into revealing harmful behavior, such as expressing racist viewpoints, during conversations. To analyze this systematically, we introduce CoBia, a suite of lightweight adversarial attacks that allow us to refine the scope of conditions under which LLMs depart from normative or ethical behavior in conversations. CoBia creates a constructed conversation where the model utters a biased claim about a social group. We then evaluate whether the model can recover from the fabricated bias claim and reject biased follow-up questions. We evaluate 11 open-source as well as proprietary LLMs for their outputs related to six socio-demographic categories that are relevant to individual safety and fair treatment, i.e., gender, race, religion, nationality, sex orientation, and others. Our evaluation is based on established LLM-based bias metrics, and we compare the results against human judgments to scope out the LLMs' reliability and alignment. The results suggest that purposefully constructed conversations reliably reveal bias amplification and that LLMs often fail to reject biased follow-up questions during dialogue. This form of stress-testing highlights deeply embedded biases that can be surfaced through interaction. Code and artifacts are available at https://github.com/nafisenik/CoBia.