Iterative LLM-Based Generation and Refinement of Distracting Conditions in Math Word Problems
作者: Kaiqi Yang, Hang Li, Yucheng Chu, Zitao Liu, Mi Tian, Hui Liu
分类: cs.CL
发布日期: 2025-10-08 (更新: 2025-10-16)
💡 一句话要点
提出一种基于迭代LLM的数学应用题干扰条件生成与优化框架
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 数学应用题 干扰条件生成 大语言模型 数据增强 迭代优化
📋 核心要点
- 现有数学应用题数据集缺乏包含干扰信息的样本,导致模型在实际场景中表现不佳,泛化能力受限。
- 提出一种迭代框架,利用大语言模型生成并优化数学应用题中的干扰条件,提升数据集质量和多样性。
- 该框架通过引导LLM生成不改变原问题答案的干扰信息,有效降低了人工标注成本,提高了数据生成效率。
📝 摘要(中文)
数学推理是大语言模型(LLMs)智能的关键测试,而数学应用题(MWPs)是一种流行的数学问题。大多数MWP数据集由仅包含必要信息的问题组成,而具有干扰性和过度条件的问题常常被忽视。先前的工作测试了流行的LLM,发现在存在干扰条件的情况下,性能急剧下降。然而,具有干扰条件的MWP数据集是有限的,并且大多数数据集的难度较低且存在上下文无关的表达。这使得干扰条件易于识别和排除,从而降低了对其进行基准测试的可信度。此外,当添加干扰条件时,推理和答案也可能发生变化,需要大量的人工来检查和编写解决方案。为了解决这些问题,我们设计了一个迭代框架,使用LLM生成干扰条件。我们开发了一组提示,从不同的角度和认知水平修改MWP,鼓励生成干扰条件以及进一步修改的建议。另一个优点是原始问题和修改后的问题之间共享解决方案:我们明确地引导LLM生成不改变原始解决方案的干扰条件,从而避免了生成新解决方案的需要。该框架高效且易于部署,降低了生成具有干扰条件的MWP的开销,同时保持了数据质量。
🔬 方法详解
问题定义:论文旨在解决数学应用题(MWP)数据集中缺乏带有干扰信息的样本的问题。现有数据集通常只包含必要信息,这使得训练出的模型在面对真实场景中包含无关信息的应用题时,性能显著下降。此外,现有的人工构建干扰信息的方法成本高昂,且难以保证干扰信息的质量和真实性。
核心思路:论文的核心思路是利用大语言模型(LLM)的生成能力,自动地为数学应用题添加干扰信息。通过迭代的方式,不断优化生成的干扰信息,使其更具迷惑性,同时保证不改变原问题的正确答案。这样既可以降低人工标注成本,又可以提高数据集的质量和多样性。
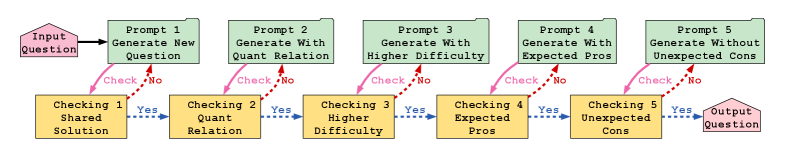
技术框架:该框架主要包含以下几个阶段:1) 原始MWP输入;2) LLM生成干扰条件:利用设计的prompt,引导LLM从不同角度和认知水平生成干扰条件;3) LLM优化与修订:对生成的干扰条件进行优化和修订,确保其不改变原问题的答案,并提高迷惑性;4) 迭代过程:重复步骤2和3,不断优化干扰条件,直到满足预设的质量标准;5) 输出带有干扰条件的MWP。
关键创新:该论文的关键创新在于提出了一种基于迭代LLM的干扰条件生成框架,该框架能够自动地为数学应用题添加高质量的干扰信息,而无需人工标注。此外,该框架还能够保证生成的干扰信息不改变原问题的答案,从而避免了重新标注答案的成本。
关键设计:论文的关键设计包括:1) 精心设计的prompt:通过prompt引导LLM生成不同类型的干扰信息,例如数字干扰、概念干扰等;2) 迭代优化机制:通过迭代的方式,不断优化生成的干扰信息,使其更具迷惑性;3) 答案一致性约束:在生成干扰信息时,强制LLM保证不改变原问题的答案。
🖼️ 关键图片
📊 实验亮点
论文提出了一种高效的基于LLM的干扰条件生成框架,能够自动生成高质量的干扰信息,显著降低了人工标注成本。该框架生成的带有干扰信息的数学应用题可以有效评估和提升大语言模型的数学推理能力。具体性能数据未知。
🎯 应用场景
该研究成果可应用于构建更具挑战性和真实性的数学应用题数据集,用于训练和评估大语言模型的数学推理能力。此外,该方法还可以扩展到其他自然语言处理任务中,例如生成对抗样本、提高模型的鲁棒性等。
📄 摘要(原文)
Mathematical reasoning serves as a crucial testbed for the intelligence of large language models (LLMs), and math word problems (MWPs) are a popular type of math problems. Most MWP datasets consist of problems containing only the necessary information, while problems with distracting and excessive conditions are often overlooked. Prior works have tested popular LLMs and found a dramatic performance drop in the presence of distracting conditions. However, datasets of MWPs with distracting conditions are limited, and most suffer from lower levels of difficulty and out-of-context expressions. This makes distracting conditions easy to identify and exclude, thus reducing the credibility of benchmarking on them. Moreover, when adding distracting conditions, the reasoning and answers may also change, requiring intensive labor to check and write the solutions. To address these issues, we design an iterative framework to generate distracting conditions using LLMs. We develop a set of prompts to revise MWPs from different perspectives and cognitive levels, encouraging the generation of distracting conditions as well as suggestions for further revision. Another advantage is the shared solutions between original and revised problems: we explicitly guide the LLMs to generate distracting conditions that do not alter the original solutions, thus avoiding the need to generate new solutions. This framework is efficient and easy to deploy, reducing the overhead of generating MWPs with distracting conditions while maintaining data quality.