Do Internal Layers of LLMs Reveal Patterns for Jailbreak Detection?
作者: Sri Durga Sai Sowmya Kadali, Evangelos E. Papalexakis
分类: cs.CL
发布日期: 2025-10-08 (更新: 2025-10-09)
💡 一句话要点
通过分析LLM内部层激活模式实现Jailbreak检测
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 Jailbreak攻击 对抗性提示 内部表示 安全防御
📋 核心要点
- 现有防御模型无法完全抵抗新型Jailbreak攻击,对LLM的安全性构成持续威胁。
- 通过分析LLM内部层对Jailbreak和良性提示的响应差异,寻找检测Jailbreak攻击的线索。
- 初步实验表明,GPT-J和Mamba2的内部层对不同类型的提示表现出可区分的行为模式。
📝 摘要(中文)
随着对话式大型语言模型(LLM)的日益普及和易用,针对LLM的Jailbreak攻击已成为一个紧迫的问题。对抗性用户经常通过精心设计的提示来利用这些模型,以引诱其产生受限或敏感的输出,这种策略被广泛称为Jailbreak。虽然已经提出了许多防御机制,但攻击者不断开发新的提示技术,并且没有现有模型可以被认为是完全抵抗的。在本研究中,我们通过检查LLM的内部表示来研究Jailbreak现象,重点关注隐藏层如何响应Jailbreak提示与良性提示。具体来说,我们分析了开源LLM GPT-J和状态空间模型Mamba2,并提出了初步的研究结果,强调了不同的层级行为。我们的结果为进一步研究利用内部模型动态进行鲁棒的Jailbreak检测和防御提供了有希望的方向。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)的Jailbreak检测问题。现有的防御方法无法完全抵御不断涌现的对抗性提示攻击,因此需要更深入地理解LLM内部对Jailbreak攻击的响应机制,从而开发更有效的防御手段。
核心思路:论文的核心思路是,Jailbreak攻击和良性提示会在LLM的内部层产生不同的激活模式。通过分析这些激活模式的差异,可以区分Jailbreak攻击并采取相应的防御措施。这种方法避免了依赖于外部知识或规则,而是直接从模型内部状态入手。
技术框架:论文的技术框架主要包括以下几个阶段:1) 收集Jailbreak提示和良性提示数据集;2) 使用这些提示输入到目标LLM(GPT-J和Mamba2);3) 提取LLM各隐藏层的激活向量;4) 分析不同提示类型下激活向量的统计特性和分布差异,例如均值、方差、距离等;5) 基于这些差异设计Jailbreak检测器。
关键创新:论文的关键创新在于,它将Jailbreak检测问题转化为对LLM内部表示的分析问题。与传统的基于规则或外部知识的防御方法不同,该方法直接利用了LLM自身的特性来识别Jailbreak攻击。这种方法具有更强的适应性和鲁棒性,可以应对新型的对抗性提示。
关键设计:论文的关键设计包括:1) 选择合适的LLM作为研究对象(GPT-J和Mamba2);2) 设计有效的特征提取方法,从隐藏层激活向量中提取有意义的统计信息;3) 使用合适的分类器或异常检测算法来区分Jailbreak攻击和良性提示。具体的参数设置、损失函数和网络结构等细节在论文中可能没有详细描述,需要进一步查阅相关文献。
🖼️ 关键图片
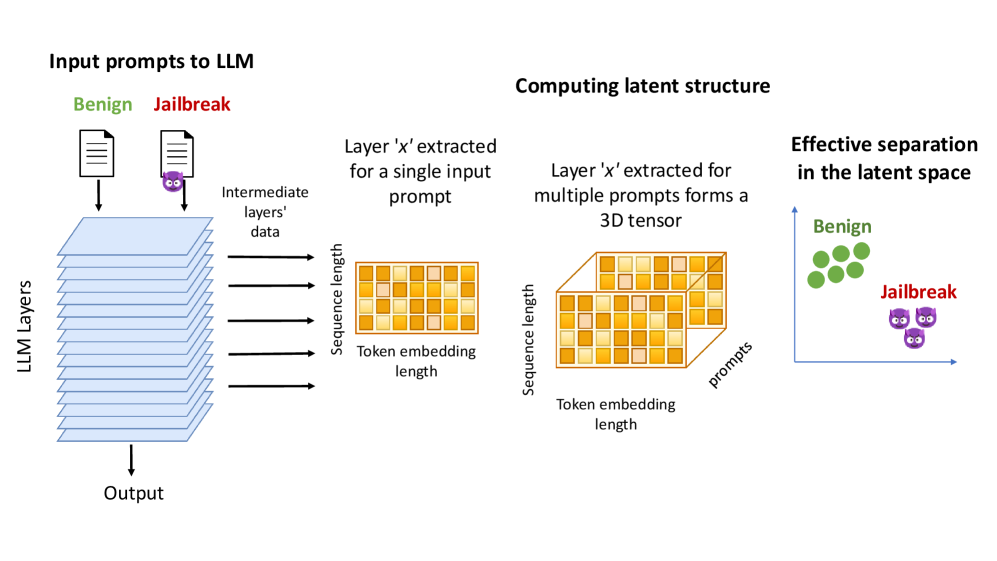

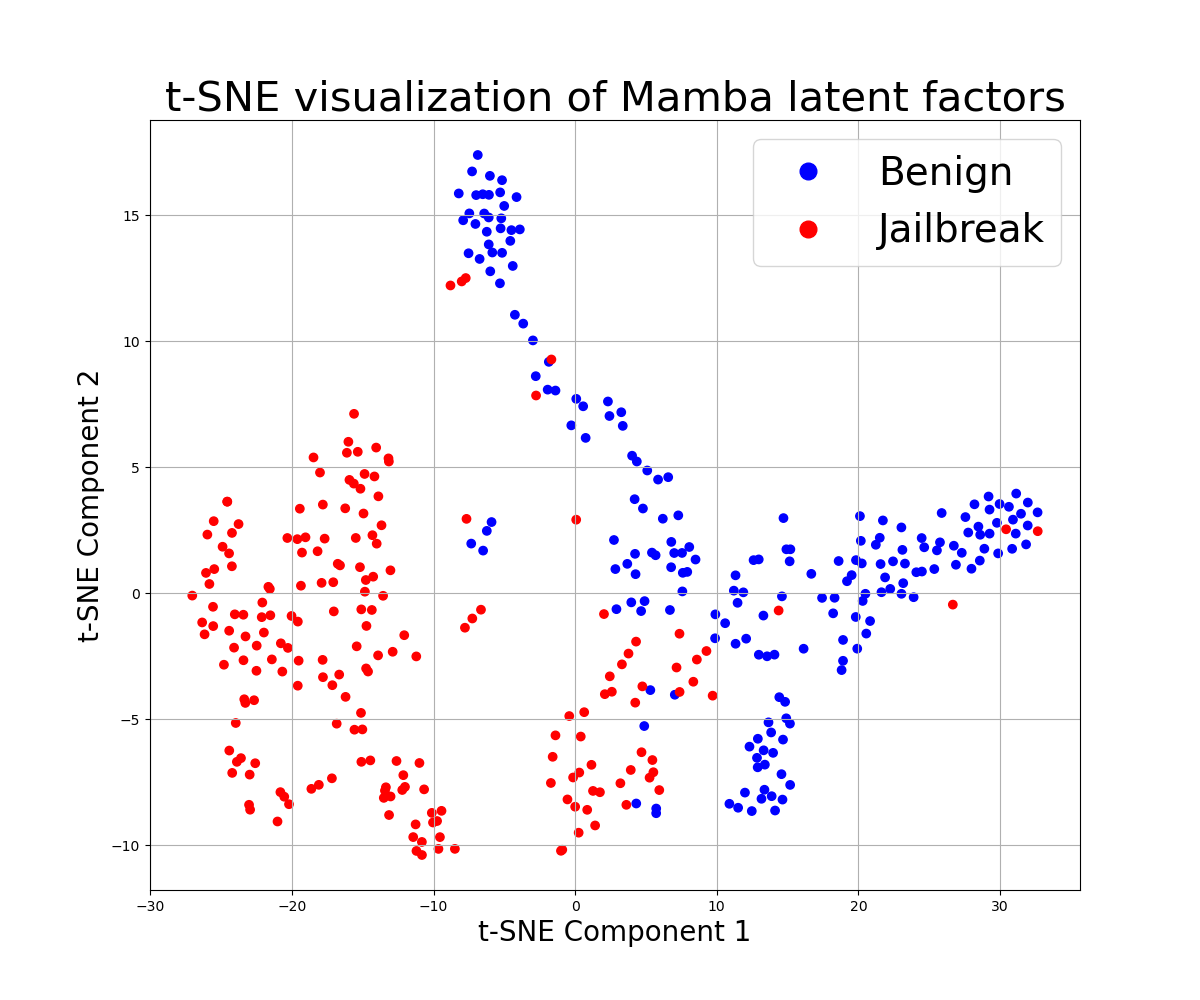
📊 实验亮点
论文初步实验表明,GPT-J和Mamba2的内部层对Jailbreak提示和良性提示表现出不同的激活模式。虽然论文中没有给出具体的性能数据和提升幅度,但这些发现为基于内部表示的Jailbreak检测方法提供了有力的支持,并指出了未来研究的方向。
🎯 应用场景
该研究成果可应用于提升各类LLM的安全性和可靠性,例如聊天机器人、智能助手等。通过集成Jailbreak检测模块,可以有效防止LLM被恶意利用,输出有害或不当内容。此外,该研究也有助于理解LLM的内部工作机制,为开发更安全、更可控的LLM提供理论指导。
📄 摘要(原文)
Jailbreaking large language models (LLMs) has emerged as a pressing concern with the increasing prevalence and accessibility of conversational LLMs. Adversarial users often exploit these models through carefully engineered prompts to elicit restricted or sensitive outputs, a strategy widely referred to as jailbreaking. While numerous defense mechanisms have been proposed, attackers continuously develop novel prompting techniques, and no existing model can be considered fully resistant. In this study, we investigate the jailbreak phenomenon by examining the internal representations of LLMs, with a focus on how hidden layers respond to jailbreak versus benign prompts. Specifically, we analyze the open-source LLM GPT-J and the state-space model Mamba2, presenting preliminary findings that highlight distinct layer-wise behaviors. Our results suggest promising directions for further research on leveraging internal model dynamics for robust jailbreak detection and defense.