GraphGhost: Tracing Structures Behind Large Language Models
作者: Xinnan Dai, Xianxuan Long, Chung-Hsiang Lo, Kai Guo, Shenglai Zeng, Dongsheng Luo, Jiliang Tang
分类: cs.CL
发布日期: 2025-10-07 (更新: 2026-01-29)
💡 一句话要点
GraphGhost:通过图结构追踪大语言模型内部推理机制
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 可解释性 图神经网络 推理机制 结构分析
📋 核心要点
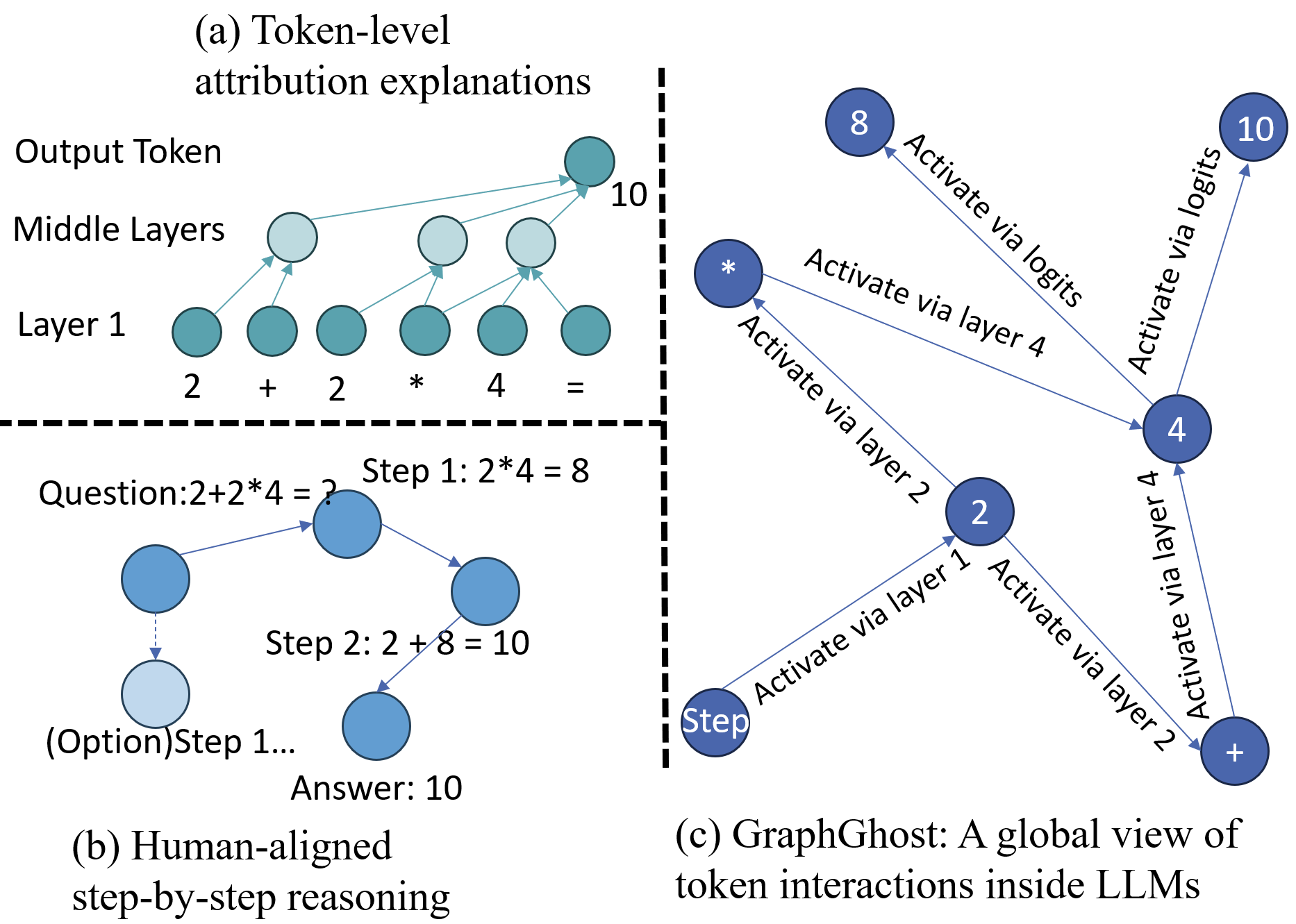
- 现有token级别归因方法难以洞察LLM内部多步推理机制,限制了对模型行为的理解。
- GraphGhost将LLM内部token交互和神经元激活建模为图,捕获全局信息流和结构模式。
- 实验表明图结构属性与关键token和神经元相关,扰动关键节点会显著改变推理行为。
📝 摘要(中文)
大型语言模型(LLMs)在结构化任务上表现出强大的推理能力,但这种行为背后的内部机制仍然知之甚少。现有的解释方法主要集中在token级别的归因,对于模型内部的多步推理提供的洞察有限。我们提出了GraphGhost,一个基于图的框架,将LLMs中的内部token交互和神经元激活建模为图。通过聚合跨层追踪的token依赖关系,GraphGhost捕获模型预测背后的全局信息流。我们从两个互补的角度形式化GraphGhost:一个样本视图,追踪单个预测的token依赖关系;一个数据集视图,聚合训练期间学习到的重复结构模式。通过图分析和定量实验,我们表明图结构属性与有影响力的token和神经元节点密切相关,并且对结构上关键节点的扰动会导致推理行为的可测量变化。这些结果表明,GraphGhost捕获的结构模式反映了LLM推理的有意义的内部组织。
🔬 方法详解
问题定义:现有方法主要关注token级别的归因,无法有效揭示LLM内部复杂的多步推理过程。因此,理解LLM如何利用其内部结构进行推理,以及哪些结构对推理过程至关重要,仍然是一个挑战。现有方法难以捕捉token之间的长距离依赖关系和全局信息流动,导致对模型推理机制的理解不够深入。
核心思路:GraphGhost的核心思路是将LLM内部的token交互和神经元激活表示为图结构,从而捕捉模型内部的全局信息流动和结构模式。通过分析这些图结构,可以识别对推理过程至关重要的token和神经元,并理解它们之间的关系。这种方法能够超越token级别的归因,提供对LLM推理机制更深层次的理解。
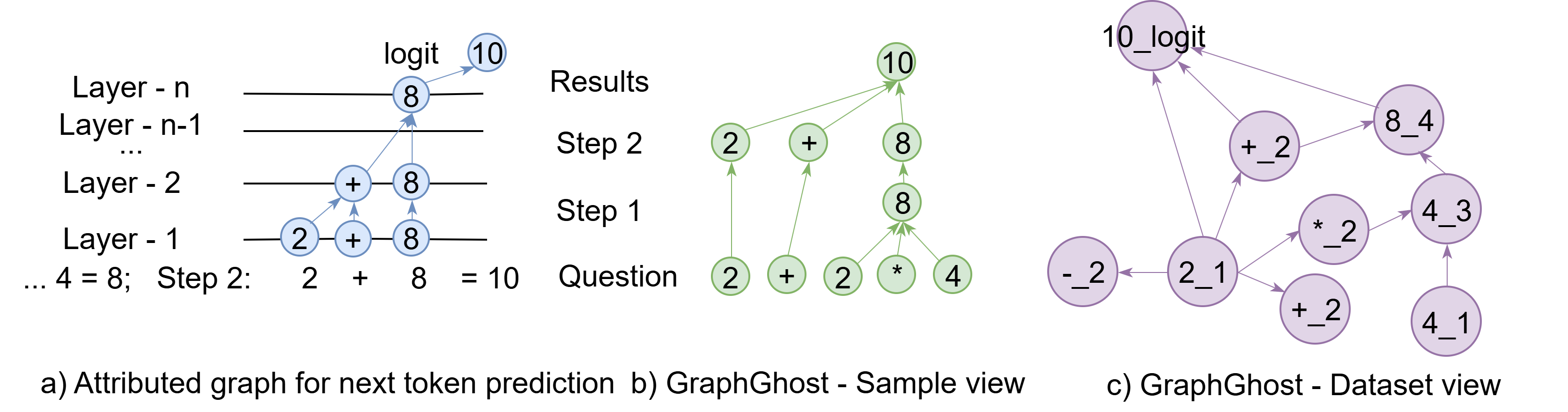
技术框架:GraphGhost框架包含两个主要视图:样本视图和数据集视图。样本视图针对单个输入样本,追踪token之间的依赖关系,构建token依赖图。数据集视图则聚合训练数据中重复出现的结构模式,构建全局结构图。框架主要包含以下步骤:1) 构建token依赖图:通过注意力机制或其他方法追踪token之间的依赖关系。2) 构建神经元激活图:将神经元的激活状态表示为图节点,并根据连接权重构建边。3) 图分析:利用图分析技术,如中心性分析、社区检测等,识别关键token和神经元。4) 扰动分析:通过扰动关键节点,观察模型推理行为的变化。
关键创新:GraphGhost的关键创新在于将图结构引入到LLM的解释性研究中,从而能够捕捉模型内部的全局信息流动和结构模式。与传统的token级别归因方法相比,GraphGhost能够提供对模型推理机制更深层次的理解。此外,GraphGhost还提出了样本视图和数据集视图两种互补的分析方法,分别从个体和整体的角度揭示模型内部的结构。
关键设计:在构建token依赖图时,可以使用注意力权重作为边的权重,也可以使用其他方法来衡量token之间的依赖关系。在构建神经元激活图时,可以使用神经元之间的连接权重作为边的权重,也可以使用其他方法来衡量神经元之间的关系。在图分析阶段,可以使用多种图分析技术,如PageRank、Betweenness Centrality等,来识别关键节点。扰动分析可以通过屏蔽或修改关键节点的激活状态来实现。
🖼️ 关键图片
📊 实验亮点
实验结果表明,GraphGhost能够有效识别对推理过程至关重要的token和神经元。对结构上关键节点的扰动会导致推理行为的可测量变化,验证了GraphGhost捕获的结构模式反映了LLM推理的有意义的内部组织。定量实验表明,基于GraphGhost识别的关键节点进行模型压缩,可以在保持性能的同时显著减少模型规模。
🎯 应用场景
GraphGhost可应用于提升LLM的可解释性和可靠性。通过理解模型内部的推理机制,可以更好地诊断和修复模型中的错误,提高模型在安全敏感领域的应用能力。此外,该方法还可以用于模型压缩和知识蒸馏,通过识别和保留关键结构,减少模型规模,同时保持性能。
📄 摘要(原文)
Large Language Models (LLMs) exhibit strong reasoning capabilities on structured tasks, yet the internal mechanisms underlying such behaviors remain poorly understood. Existing interpretation methods mainly focus on token-level attributions, which provide limited insight into multi-step reasoning inside the model. We propose GraphGhost, a graph-based framework that models internal token interactions and neuron activations in LLMs as graphs. By aggregating token dependencies traced across layers, GraphGhost captures global information flow underlying model predictions. We formalize GraphGhost from two complementary perspectives: a sample view, which traces token dependencies for individual predictions, and a dataset view, which aggregates recurring structural patterns learned during training. Through graph analytics and quantitative experiments, we show that graph structural properties are closely associated with influential tokens and neuron nodes, and that perturbations to structurally critical nodes lead to measurable changes in reasoning behavior. These results indicate that the structural patterns captured by GraphGhost reflect meaningful internal organization of LLM reasoning. The codes are available at software part. Artifacts will be made available for research use only.