MMA-ASIA: A Multilingual and Multimodal Alignment Framework for Culturally-Grounded Evaluation
作者: Weihua Zheng, Zhengyuan Liu, Tanmoy Chakraborty, Weiwen Xu, Xiaoxue Gao, Bryan Chen Zhengyu Tan, Bowei Zou, Chang Liu, Yujia Hu, Xing Xie, Xiaoyuan Yi, Jing Yao, Chaojun Wang, Long Li, Rui Liu, Huiyao Liu, Koji Inoue, Ryuichi Sumida, Tatsuya Kawahara, Fan Xu, Lingyu Ye, Wei Tian, Dongjun Kim, Jimin Jung, Jaehyung Seo, Nadya Yuki Wangsajaya, Pham Minh Duc, Ojasva Saxena, Palash Nandi, Xiyan Tao, Wiwik Karlina, Tuan Luong, Keertana Arun Vasan, Roy Ka-Wei Lee, Nancy F. Chen
分类: cs.CL, cs.AI
发布日期: 2025-10-07
💡 一句话要点
提出MMA-ASIA框架,用于多语言多模态文化背景下的大语言模型评测
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多语言多模态 文化意识 大语言模型评测 亚洲文化 跨模态一致性
📋 核心要点
- 现有LLM在非西方文化背景下的多模态理解能力不足,缺乏针对亚洲文化背景的评测基准。
- MMA-ASIA框架通过构建多语言、多模态对齐的基准数据集,并提出五维评估协议来解决该问题。
- 实验结果通过模型分析、注意力追踪和VPR方法,揭示了模型在不同语言和模态上的差异原因。
📝 摘要(中文)
大型语言模型(LLMs)现已在全球范围内使用,但它们的多模态理解和推理能力在西方高资源环境之外通常会下降。我们提出了MMA-ASIA,这是一个全面的框架,用于评估LLMs的文化意识,重点关注亚洲背景。MMA-ASIA的核心是一个人工策划的、多语言的、多模态对齐的选择题基准,涵盖8个亚洲国家和10种语言,包含27,000个问题;超过79%的问题需要基于文化背景的多步骤推理,超越了简单的记忆。据我们所知,这是第一个在输入层面跨三种模态(文本、图像(视觉问答)和语音)对齐的数据集。这使得能够直接测试跨模态迁移。在此基准的基础上,我们提出了一个五维评估协议,用于衡量:(i)各国之间的文化意识差异,(ii)跨语言一致性,(iii)跨模态一致性,(iv)文化知识泛化,以及(v)基础有效性。为了确保严格的评估,文化意识基础验证模块通过检查所需的文化知识是否支持正确的答案来检测“捷径学习”。最后,通过比较模型分析、注意力追踪和创新的视觉消融前缀重放(VPR)方法,我们探究了模型在不同语言和模态之间出现差异的原因,为构建文化上可靠的多模态LLM提供了可操作的见解。
🔬 方法详解
问题定义:现有的大型语言模型在处理亚洲文化背景下的多模态任务时,表现出明显的性能下降。这主要是因为训练数据偏向于西方文化,导致模型缺乏对亚洲文化知识的理解和推理能力。此外,现有的多模态评测基准也较少关注亚洲文化,难以全面评估模型在这些场景下的表现。因此,需要构建一个专门针对亚洲文化的多模态评测框架,以促进相关研究的进展。
核心思路:MMA-ASIA的核心思路是构建一个多语言、多模态对齐的基准数据集,并设计一套全面的评估协议,以评估LLM在亚洲文化背景下的理解和推理能力。通过多语言数据,可以考察模型的跨语言一致性;通过多模态数据(文本、图像、语音),可以考察模型的跨模态一致性。此外,还引入了文化意识基础验证模块,以检测模型是否通过“捷径学习”获得正确答案,从而保证评估的可靠性。
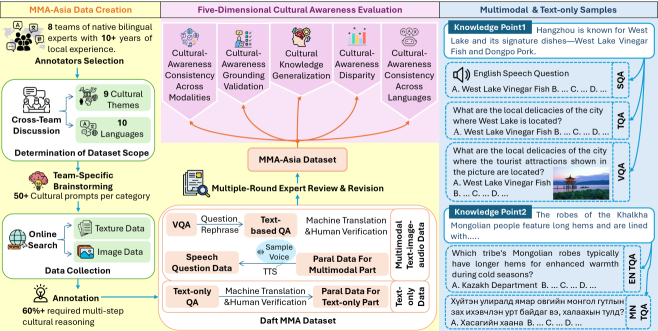
技术框架:MMA-ASIA框架主要包含以下几个模块:1) 多语言多模态基准数据集构建:收集并标注涵盖8个亚洲国家和10种语言的文本、图像和语音数据,构建包含27,000个问题的选择题数据集。2) 五维评估协议:从文化意识差异、跨语言一致性、跨模态一致性、文化知识泛化和基础有效性五个维度评估LLM的性能。3) 文化意识基础验证模块:检测模型是否通过“捷径学习”获得正确答案。4) 模型分析与调试:通过比较模型分析、注意力追踪和VPR方法,探究模型在不同语言和模态之间出现差异的原因。
关键创新:MMA-ASIA的创新点在于:1) 首次构建了多语言、多模态对齐的亚洲文化背景下的基准数据集。2) 提出了一个五维评估协议,可以全面评估LLM的文化意识。3) 引入了文化意识基础验证模块,可以检测模型是否通过“捷径学习”获得正确答案。4) 采用了VPR方法,可以探究模型在不同语言和模态之间出现差异的原因。
关键设计:在数据集构建方面,确保每个问题都需要基于文化背景的多步骤推理,避免简单记忆。在评估协议方面,五维评估协议的设计旨在全面评估LLM的文化意识,包括跨语言和跨模态的一致性。VPR方法通过消融视觉信息,并使用前缀重放技术,来分析视觉信息对模型性能的影响。
🖼️ 关键图片


📊 实验亮点
该论文构建了一个包含27,000个问题的多语言多模态数据集,覆盖8个亚洲国家和10种语言。实验结果表明,现有LLM在跨语言和跨模态方面存在显著差异,且容易受到“捷径学习”的影响。通过VPR方法,发现视觉信息对模型性能的影响因语言和模态而异。
🎯 应用场景
MMA-ASIA框架可应用于评估和提升LLM在亚洲文化背景下的多模态理解能力,促进开发更具文化敏感性和适应性的AI系统。该框架可用于教育、旅游、跨文化交流等领域,帮助LLM更好地理解和处理涉及亚洲文化的内容,从而提供更准确、更可靠的服务。
📄 摘要(原文)
Large language models (LLMs) are now used worldwide, yet their multimodal understanding and reasoning often degrade outside Western, high-resource settings. We propose MMA-ASIA, a comprehensive framework to evaluate LLMs' cultural awareness with a focus on Asian contexts. MMA-ASIA centers on a human-curated, multilingual, and multimodally aligned multiple-choice benchmark covering 8 Asian countries and 10 languages, comprising 27,000 questions; over 79 percent require multi-step reasoning grounded in cultural context, moving beyond simple memorization. To our knowledge, this is the first dataset aligned at the input level across three modalities: text, image (visual question answering), and speech. This enables direct tests of cross-modal transfer. Building on this benchmark, we propose a five-dimensional evaluation protocol that measures: (i) cultural-awareness disparities across countries, (ii) cross-lingual consistency, (iii) cross-modal consistency, (iv) cultural knowledge generalization, and (v) grounding validity. To ensure rigorous assessment, a Cultural Awareness Grounding Validation Module detects "shortcut learning" by checking whether the requisite cultural knowledge supports correct answers. Finally, through comparative model analysis, attention tracing, and an innovative Vision-ablated Prefix Replay (VPR) method, we probe why models diverge across languages and modalities, offering actionable insights for building culturally reliable multimodal LLMs.