Centering Emotion Hotspots: Multimodal Local-Global Fusion and Cross-Modal Alignment for Emotion Recognition in Conversations
作者: Yu Liu, Hanlei Shi, Haoxun Li, Yuqing Sun, Yuxuan Ding, Linlin Gong, Leyuan Qu, Taihao Li
分类: cs.CL, cs.AI
发布日期: 2025-10-07
备注: Under review for ICASSP 2026
💡 一句话要点
提出基于情感热点的多模态局部-全局融合与跨模态对齐的对话情感识别模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 对话情感识别 多模态融合 情感热点 跨模态对齐 局部-全局融合
📋 核心要点
- 现有对话情感识别方法难以有效捕捉稀疏、局部化和跨模态异步的情感证据。
- 论文提出以情感热点为中心建模,通过热点门控融合和混合对齐器实现多模态信息融合。
- 实验结果表明,该方法在标准ERC数据集上优于现有基线模型,验证了所提出模块的有效性。
📝 摘要(中文)
对话情感识别(ERC)面临的挑战是判别性证据稀疏、局部化以及跨模态异步。本文将ERC聚焦于情感热点,提出了一个统一的模型,该模型检测文本、音频和视频中每个话语的情感热点,通过热点门控融合(Hotspot-Gated Fusion)将它们与全局特征融合,并使用路由的混合对齐器(Mixture-of-Aligners)对齐模态;一个跨模态图编码对话结构。这种设计专注于对显著片段的建模,减轻了错位,并保留了上下文。在标准ERC基准上的实验表明,相对于强大的基线,该模型获得了持续的收益,消融实验证实了HGF和MoA的贡献。我们的结果表明,以热点为中心的视角可以为未来的多模态学习提供信息,为ERC中的模态融合提供了一个新的视角。
🔬 方法详解
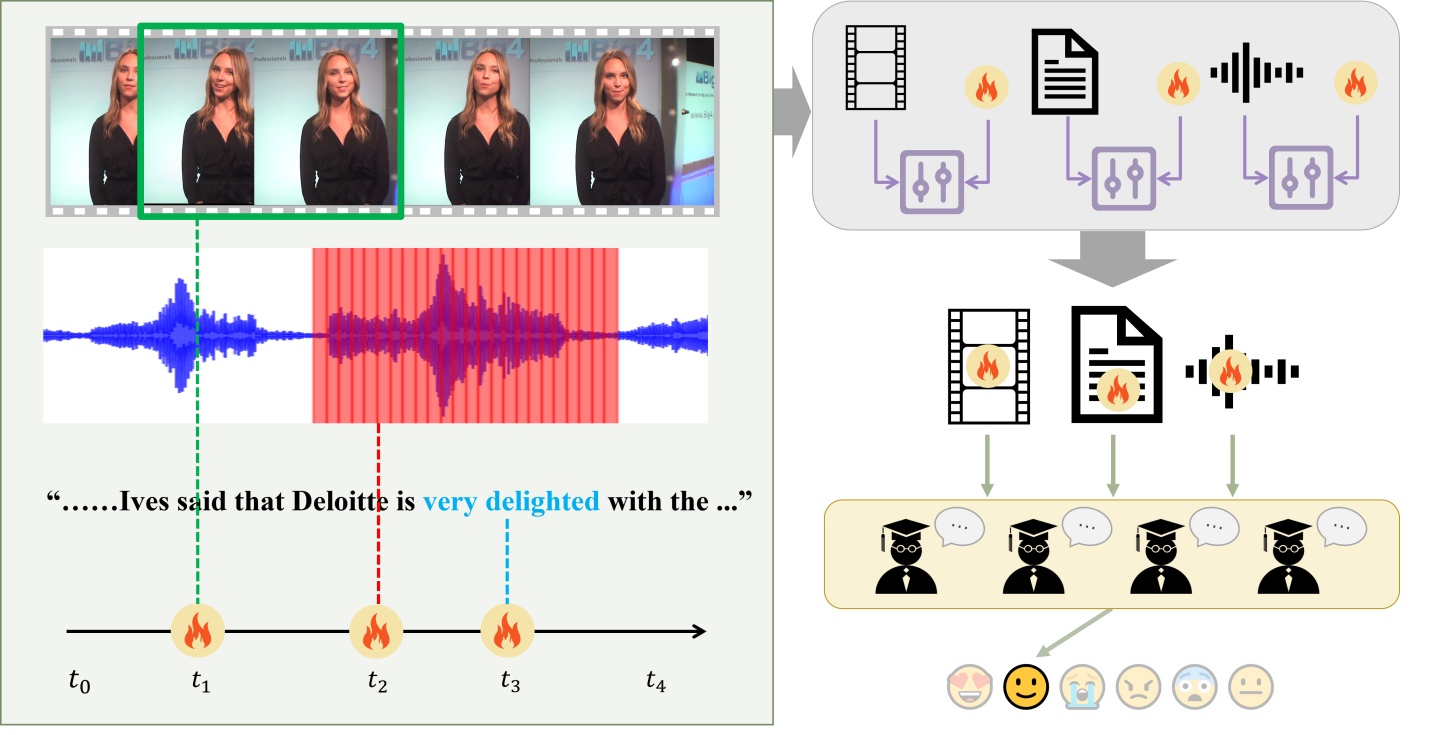
问题定义:对话情感识别(ERC)旨在识别对话中每个话语的情感。现有方法通常难以有效利用对话中稀疏、局部化且跨模态异步的情感证据,导致识别精度不高。尤其是在多模态对话中,不同模态的信息可能存在时间上的错位,进一步增加了建模难度。
核心思路:论文的核心思路是将情感识别聚焦于对话中的“情感热点”,即包含最显著情感信息的局部片段。通过提取每个模态中的情感热点,并将其与全局上下文信息融合,可以更有效地捕捉关键情感线索。同时,采用跨模态对齐机制,解决不同模态信息之间的异步问题。
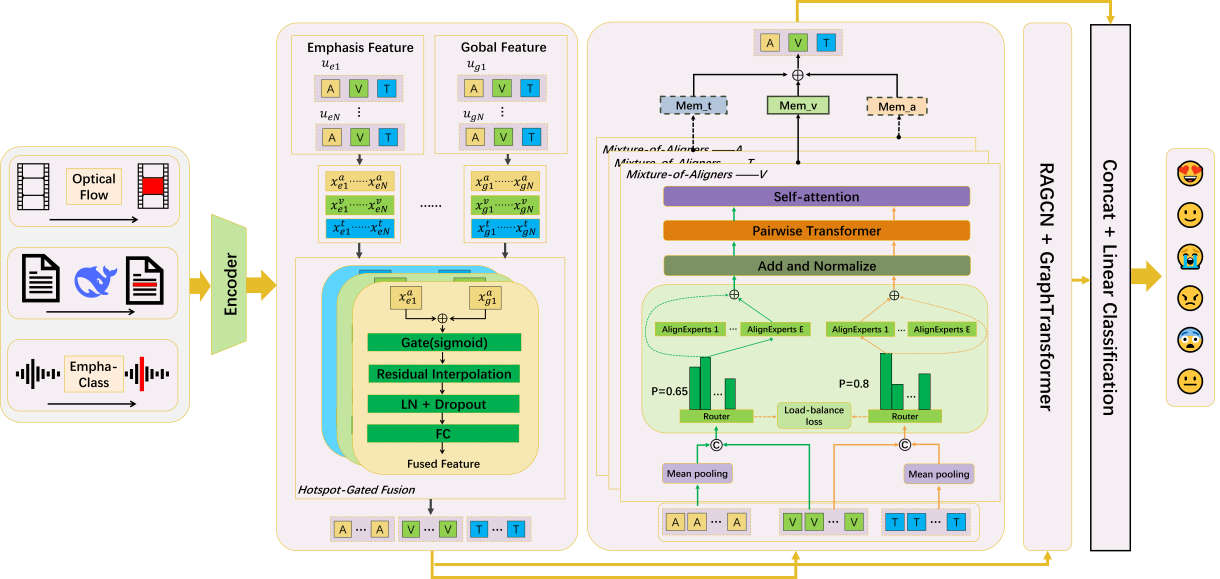
技术框架:该模型包含以下主要模块:1) 情感热点检测:在文本、音频和视频模态中分别检测每个话语的情感热点。2) 热点门控融合(HGF):将情感热点特征与全局特征融合,突出热点信息的重要性。3) 混合对齐器(MoA):使用路由机制实现跨模态对齐,解决模态间的异步问题。4) 跨模态图:编码对话结构,捕捉上下文信息。整体流程是先提取各模态特征,然后进行热点检测和融合,再进行跨模态对齐,最后利用图结构进行上下文建模和情感分类。
关键创新:该论文的关键创新在于:1) 提出了以情感热点为中心的建模方法,更有效地捕捉关键情感信息。2) 设计了热点门控融合机制,自适应地融合局部热点和全局上下文信息。3) 引入了混合对齐器,通过路由机制实现更灵活的跨模态对齐。与现有方法相比,该方法更关注对话中情感最显著的部分,并能更好地处理多模态信息之间的异步问题。
关键设计:在情感热点检测方面,可以使用注意力机制或池化操作来选择每个话语中最具情感表达力的片段。热点门控融合模块可以使用门控机制来控制热点特征和全局特征的融合比例。混合对齐器可以使用多个对齐模块,每个模块学习不同的对齐策略,并通过路由机制选择最合适的对齐模块。损失函数可以使用交叉熵损失函数,并可以加入正则化项以防止过拟合。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该模型在标准ERC基准数据集上取得了显著的性能提升。例如,在IEMOCAP数据集上,该模型相对于基线模型取得了超过2%的绝对提升。消融实验验证了热点门控融合(HGF)和混合对齐器(MoA)的有效性,证明了以情感热点为中心建模的优势。
🎯 应用场景
该研究成果可应用于智能客服、心理咨询、人机交互等领域。通过准确识别对话中的情感,可以提升人机交互的自然性和智能化水平,例如,智能客服可以根据用户的情绪状态提供个性化的服务,心理咨询系统可以辅助咨询师进行情感分析和诊断。未来,该技术还可以应用于社交媒体分析、舆情监控等领域。
📄 摘要(原文)
Emotion Recognition in Conversations (ERC) is hard because discriminative evidence is sparse, localized, and often asynchronous across modalities. We center ERC on emotion hotspots and present a unified model that detects per-utterance hotspots in text, audio, and video, fuses them with global features via Hotspot-Gated Fusion, and aligns modalities using a routed Mixture-of-Aligners; a cross-modal graph encodes conversational structure. This design focuses modeling on salient spans, mitigates misalignment, and preserves context. Experiments on standard ERC benchmarks show consistent gains over strong baselines, with ablations confirming the contributions of HGF and MoA. Our results point to a hotspot-centric view that can inform future multimodal learning, offering a new perspective on modality fusion in ERC.