Mnemosyne: An Unsupervised, Human-Inspired Long-Term Memory Architecture for Edge-Based LLMs
作者: Aneesh Jonelagadda, Christina Hahn, Haoze Zheng, Salvatore Penachio
分类: cs.CL, cs.AI, cs.LG, cs.MA
发布日期: 2025-10-07
备注: 12 pages, 4 figures
💡 一句话要点
Mnemosyne:面向边缘LLM的、受人类启发的无监督长期记忆架构
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 长期记忆 边缘计算 大型语言模型 无监督学习 图结构 医疗助手 时间推理
📋 核心要点
- 现有LLM记忆系统依赖于暴力上下文扩展或静态检索,难以在边缘设备上有效运行,限制了自然对话。
- Mnemosyne采用图结构存储、模块化过滤、记忆提交/修剪以及概率性召回,模拟人类记忆机制,实现高效长期记忆。
- 实验表明,Mnemosyne在纵向医疗对话中显著提升了真实性和长期记忆能力,并在LoCoMo基准测试中表现出色。
📝 摘要(中文)
本文提出Mnemosyne,一种为边缘设备上的大型语言模型(LLM)设计的、受人类启发的无监督长期记忆架构。该方法采用图结构存储、模块化的内容和冗余过滤器、记忆提交和修剪机制,以及模拟人类记忆的时间衰减和刷新过程的概率性召回。Mnemosyne还引入了一个集中的“核心摘要”,它有效地从记忆图的固定长度子集中提取,以捕捉用户的个性和其他特定领域的长期细节,例如,以医疗保健应用为例,恢复后的雄心和对护理的态度。与现有的检索增强方法不同,Mnemosyne专为纵向医疗保健助手设计,在这种助手中,重复且语义相似但时间上不同的对话受到简单检索的限制。在纵向医疗对话的实验中,Mnemosyne在对真实性和长期记忆能力的盲人人工评估中,获得了65.8%的最高胜率,而基线RAG的胜率为31.1%。Mnemosyne还在时间推理和单跳检索方面取得了当前最高的LoCoMo基准分数,与其他相同骨干的技术相比。此外,54.6%的平均总分在所有方法中排名第二,超过了常用的Mem0和OpenAI基线等。这表明,通过边缘兼容且易于转移的无监督记忆架构,可以实现改进的事实召回、增强的时间推理以及更自然的用户响应。
🔬 方法详解
问题定义:现有大型语言模型的长期记忆系统,要么依赖于庞大的上下文窗口,要么使用静态的检索流程。这两种方法在资源受限的边缘设备上都难以有效部署。尤其是在纵向对话场景中,例如医疗助手,简单的检索方法无法区分语义相似但时间上不同的信息,导致对话质量下降。
核心思路:Mnemosyne的核心思路是模仿人类的记忆机制,构建一个轻量级、可适应的长期记忆系统。通过图结构存储对话信息,并使用模块化的过滤器来管理记忆的内容和冗余。同时,引入时间衰减和刷新机制,模拟人类记忆的遗忘和回忆过程,从而实现更自然和高效的长期记忆。
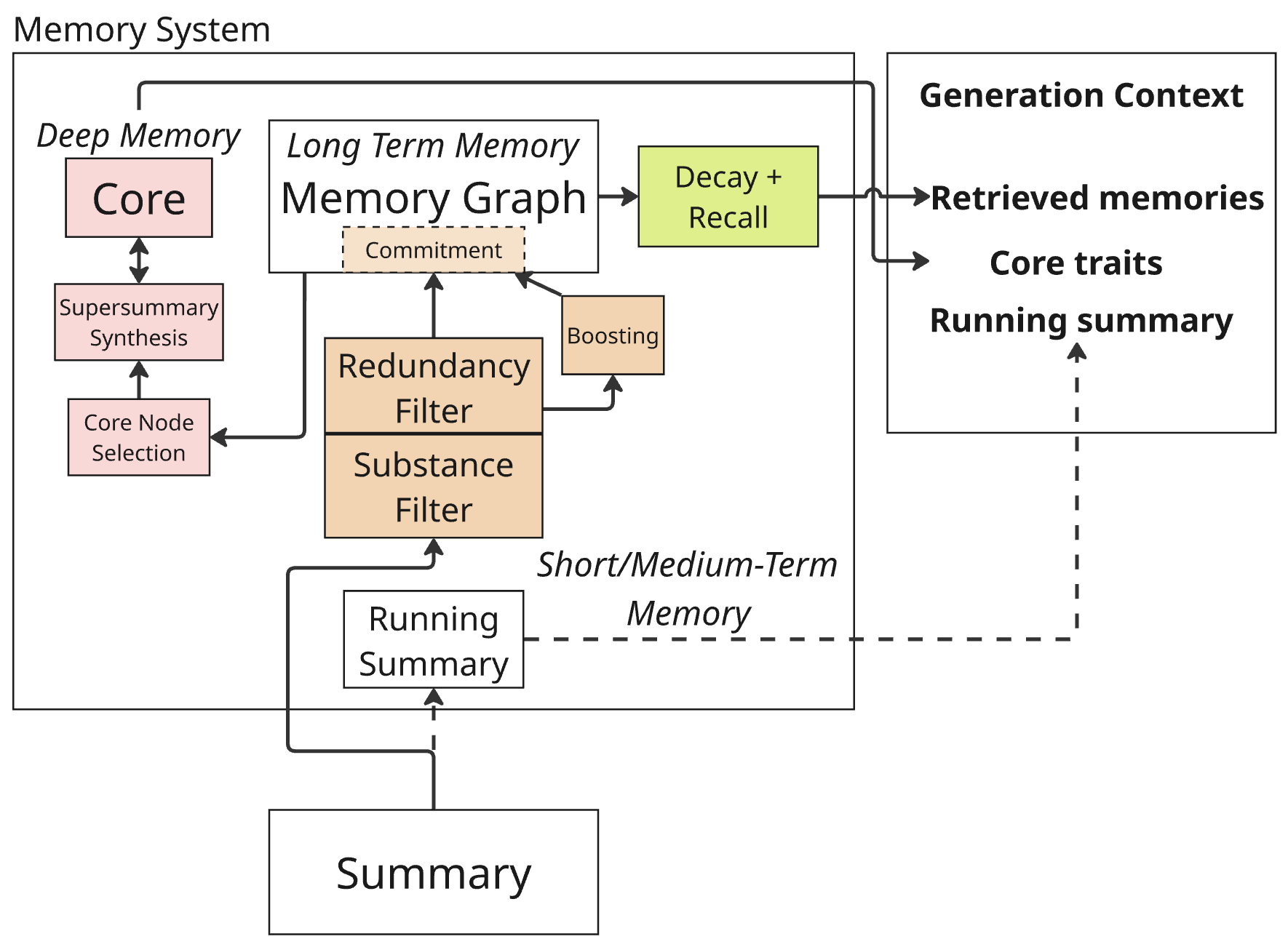
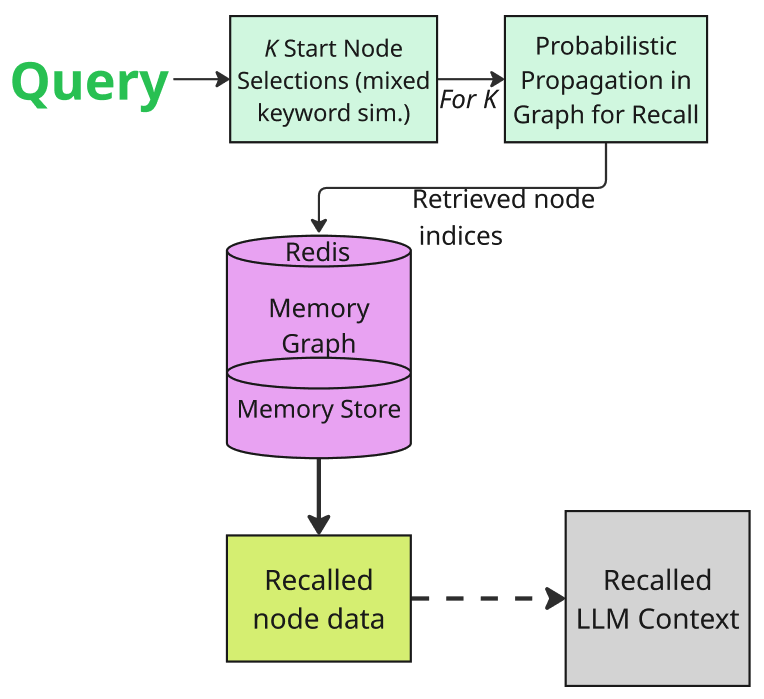
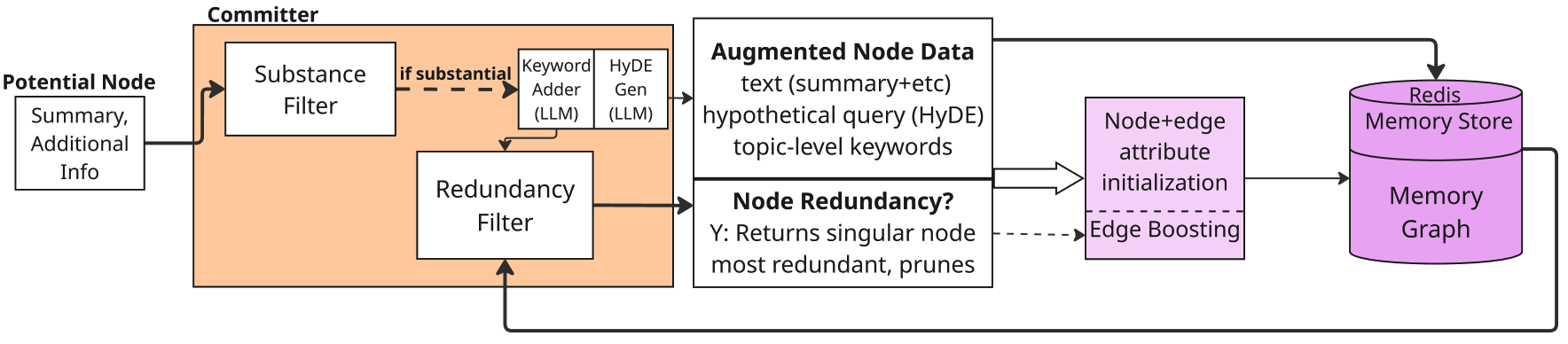
技术框架:Mnemosyne的整体架构包含以下几个主要模块:1) 图结构存储:使用图结构来存储对话历史,节点表示对话内容,边表示对话之间的关系。2) 模块化过滤器:包括内容过滤器和冗余过滤器,用于过滤掉不相关或重复的信息。3) 记忆提交和修剪:定期将新的对话信息提交到长期记忆中,并修剪掉过时或不重要的信息。4) 概率性召回:根据时间衰减和刷新机制,以概率的方式从长期记忆中召回相关信息。5) 核心摘要:从记忆图中提取固定长度的子集,用于捕捉用户的个性和其他特定领域的长期细节。
关键创新:Mnemosyne的关键创新在于其无监督的学习方式和受人类启发的记忆机制。与需要大量标注数据的检索增强方法不同,Mnemosyne可以在无监督的情况下学习对话的结构和语义关系。此外,通过模拟人类记忆的时间衰减和刷新过程,Mnemosyne能够更有效地管理和利用长期记忆。
关键设计:Mnemosyne的关键设计包括:1) 时间衰减函数:用于模拟记忆随时间的衰减程度。2) 刷新机制:用于根据对话的频率和重要性,刷新记忆的强度。3) 概率性召回策略:根据记忆的强度和相关性,以概率的方式召回信息。4) 核心摘要的提取算法:用于从记忆图中提取最具代表性的信息,形成核心摘要。
🖼️ 关键图片
📊 实验亮点
Mnemosyne在纵向医疗对话的实验中,相对于基线RAG方法,在真实性和长期记忆能力方面取得了显著提升,胜率从31.1%提高到65.8%。此外,Mnemosyne在LoCoMo基准测试中,在时间推理和单跳检索方面取得了当前最高的成绩,平均总分也超过了常用的Mem0和OpenAI基线。
🎯 应用场景
Mnemosyne适用于需要长期对话记忆的边缘设备应用,例如:个性化医疗助手、智能客服、教育辅导机器人等。它可以帮助这些应用更好地理解用户的需求和偏好,提供更自然、更个性化的服务。该研究有望推动边缘设备上LLM的应用,并提升人机交互的体验。
📄 摘要(原文)
Long-term memory is essential for natural, realistic dialogue. However, current large language model (LLM) memory systems rely on either brute-force context expansion or static retrieval pipelines that fail on edge-constrained devices. We introduce Mnemosyne, an unsupervised, human-inspired long-term memory architecture designed for edge-based LLMs. Our approach uses graph-structured storage, modular substance and redundancy filters, memory committing and pruning mechanisms, and probabilistic recall with temporal decay and refresh processes modeled after human memory. Mnemosyne also introduces a concentrated "core summary" efficiently derived from a fixed-length subset of the memory graph to capture the user's personality and other domain-specific long-term details such as, using healthcare application as an example, post-recovery ambitions and attitude towards care. Unlike existing retrieval-augmented methods, Mnemosyne is designed for use in longitudinal healthcare assistants, where repetitive and semantically similar but temporally distinct conversations are limited by naive retrieval. In experiments with longitudinal healthcare dialogues, Mnemosyne demonstrates the highest win rate of 65.8% in blind human evaluations of realism and long-term memory capability compared to a baseline RAG win rate of 31.1%. Mnemosyne also achieves current highest LoCoMo benchmark scores in temporal reasoning and single-hop retrieval compared to other same-backboned techniques. Further, the average overall score of 54.6% was second highest across all methods, beating commonly used Mem0 and OpenAI baselines among others. This demonstrates that improved factual recall, enhanced temporal reasoning, and much more natural user-facing responses can be feasible with an edge-compatible and easily transferable unsupervised memory architecture.