Webscale-RL: Automated Data Pipeline for Scaling RL Data to Pretraining Levels
作者: Zhepeng Cen, Haolin Chen, Shiyu Wang, Zuxin Liu, Zhiwei Liu, Ding Zhao, Silvio Savarese, Caiming Xiong, Huan Wang, Weiran Yao
分类: cs.CL, cs.AI
发布日期: 2025-10-07
💡 一句话要点
Webscale-RL:构建自动化数据流水线,将强化学习数据扩展到预训练级别
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 数据增强 预训练模型 自动化数据生成 大规模数据集
📋 核心要点
- 现有强化学习数据集规模小、多样性不足,限制了其在大型语言模型训练中的应用,无法充分发挥强化学习在弥合训练-生成差距方面的优势。
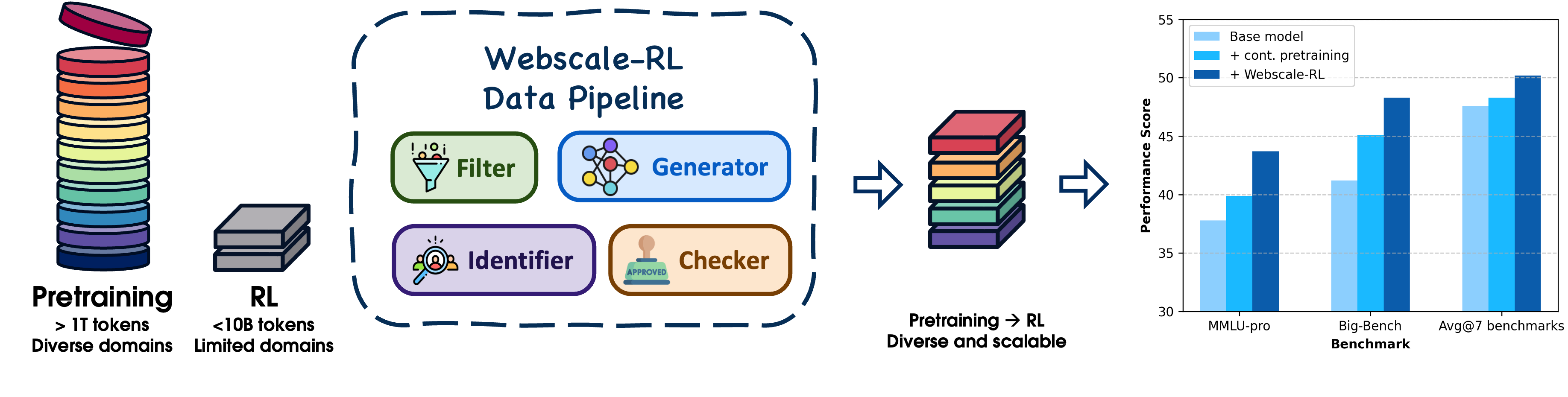
- Webscale-RL流水线通过自动化地将大规模预训练文档转化为多样化的问答对,为强化学习提供海量数据,从而突破数据瓶颈。
- 实验表明,使用Webscale-RL数据集训练的模型在多个基准测试中显著优于现有方法,并能以更少的数据量达到相当的性能。
📝 摘要(中文)
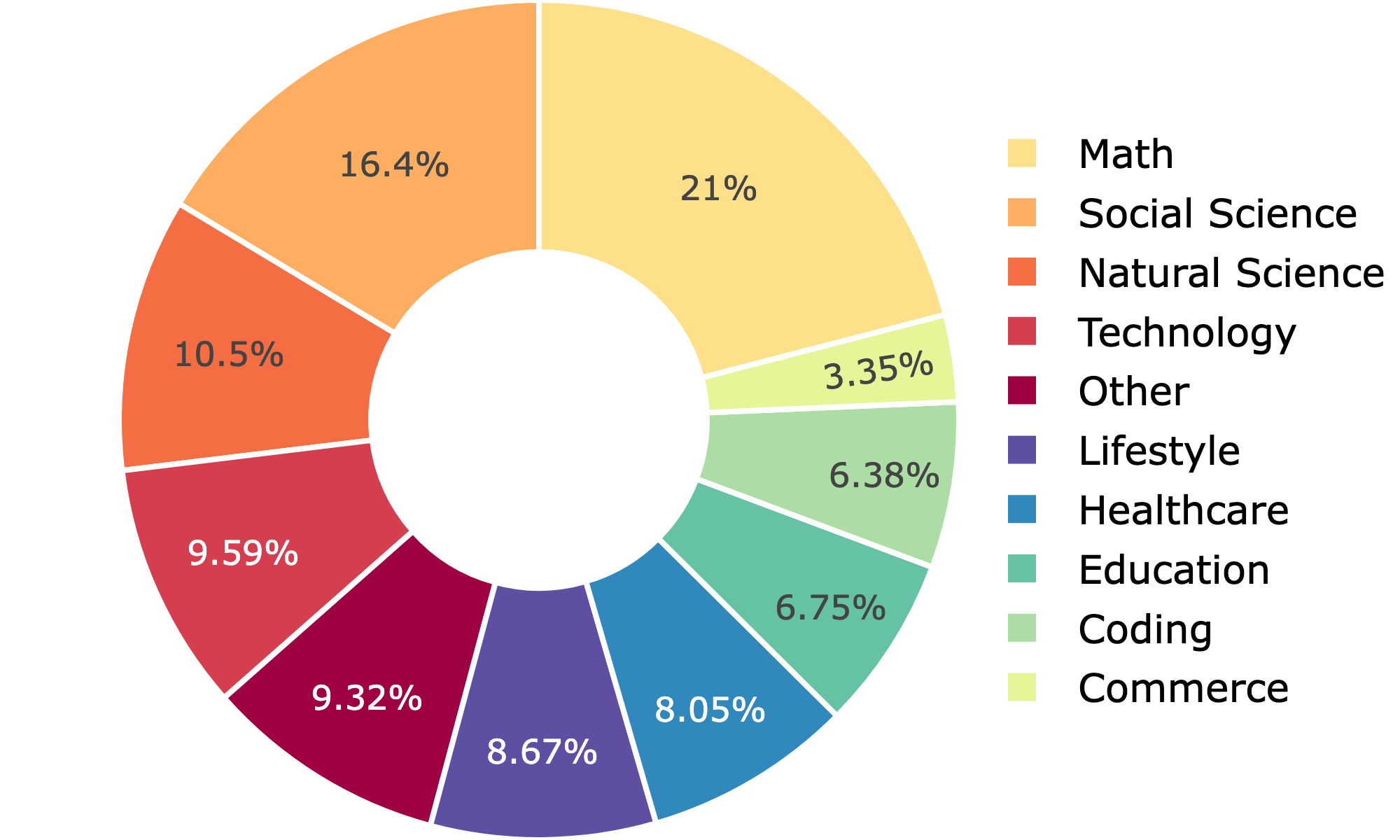
大型语言模型(LLMs)通过在海量文本语料库上进行模仿学习取得了显著成功,但这种模式造成了训练-生成差距,并限制了鲁棒的推理能力。强化学习(RL)提供了一种更具数据效率的解决方案,能够弥合这一差距,但其应用受到关键数据瓶颈的限制:现有的RL数据集比网络规模的预训练语料库小几个数量级,且多样性不足。为了解决这个问题,我们引入了Webscale-RL流水线,这是一个可扩展的数据引擎,它系统地将大规模预训练文档转换为数百万个多样化、可验证的问答对,用于强化学习。使用该流水线,我们构建了Webscale-RL数据集,其中包含跨越9个以上领域的120万个示例。我们的实验表明,在该数据集上训练的模型在多个基准测试中显著优于持续预训练和强大的数据提炼基线。值得注意的是,使用我们的数据集进行RL训练效率更高,以少至100倍的tokens实现了持续预训练的性能。我们的工作为将RL扩展到预训练级别提供了一条可行的途径,从而能够实现更强大、更高效的语言模型。
🔬 方法详解
问题定义:论文旨在解决强化学习数据规模不足的问题,现有强化学习数据集的规模远小于预训练数据集,这限制了强化学习在训练大型语言模型方面的应用。现有方法,如持续预训练,虽然可以提高模型性能,但效率较低,需要大量的计算资源和数据。
核心思路:论文的核心思路是构建一个自动化数据流水线,将大规模预训练文档转化为强化学习所需的问答对数据。通过这种方式,可以有效地利用现有的海量预训练数据,为强化学习提供充足的训练样本。
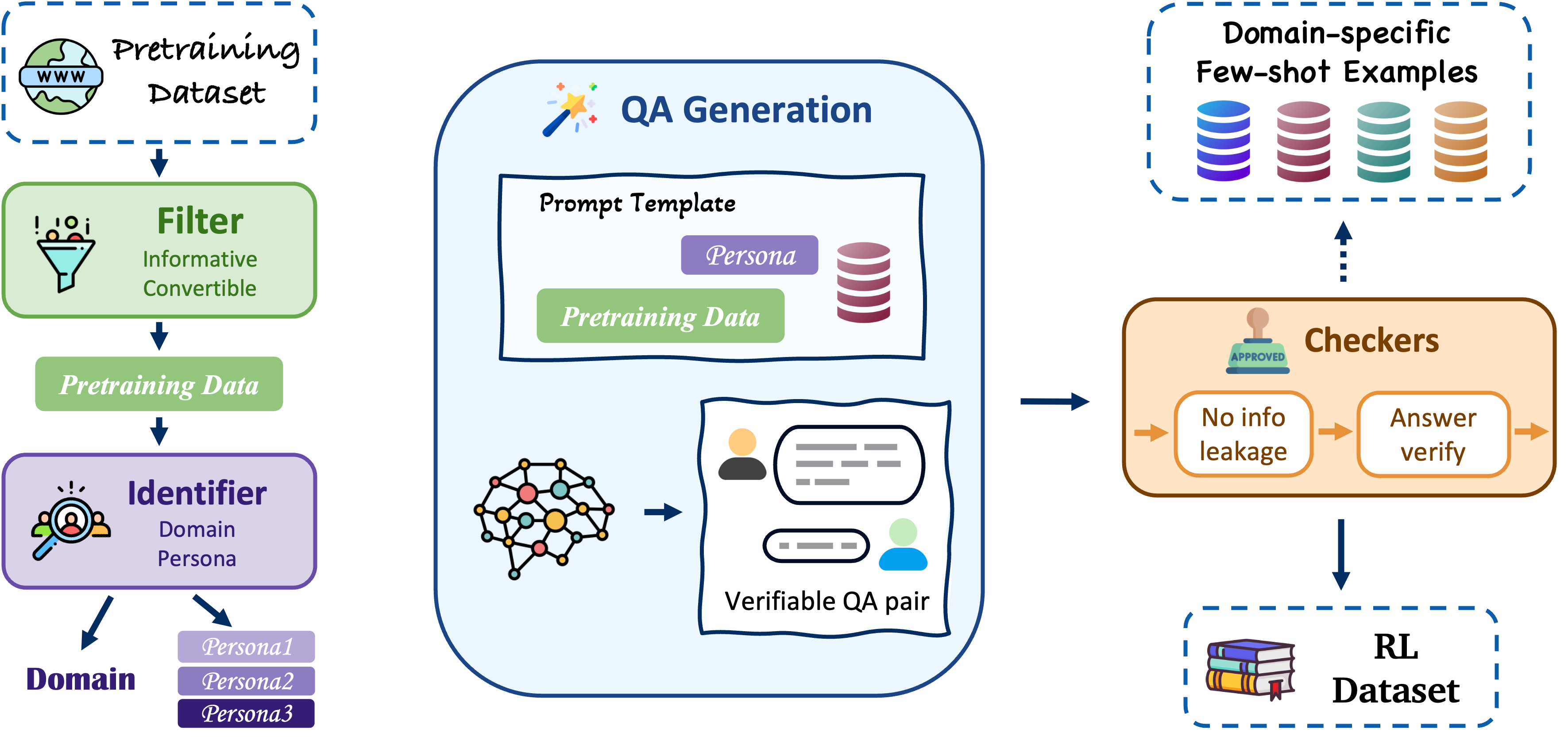
技术框架:Webscale-RL流水线包含以下主要模块:1) 数据收集:从大规模预训练语料库中收集文档。2) 问题生成:根据文档内容自动生成问题。3) 答案生成:根据文档内容和问题生成对应的答案。4) 数据过滤:对生成的问答对进行过滤,去除质量较差的样本。5) 数据存储:将高质量的问答对存储到Webscale-RL数据集中。
关键创新:该方法最重要的创新点在于自动化数据生成流水线,它能够高效地将大规模预训练文档转化为强化学习数据。与手动标注数据相比,该方法大大降低了数据获取的成本,并提高了数据生成的效率。与现有数据增强方法相比,该方法能够生成更多样化的数据,从而提高模型的泛化能力。
关键设计:问题生成模块使用了基于规则和基于模型的两种方法。基于规则的方法根据预定义的规则从文档中提取问题。基于模型的方法使用预训练语言模型生成问题。答案生成模块使用预训练语言模型根据文档和问题生成答案。数据过滤模块使用多个指标,如问题和答案的长度、问题和答案的相关性等,对生成的问答对进行过滤。
🖼️ 关键图片
📊 实验亮点
实验结果表明,在Webscale-RL数据集上训练的模型在多个基准测试中显著优于持续预训练和强大的数据提炼基线。例如,在某个问答任务上,使用Webscale-RL数据集训练的模型比持续预训练模型提高了10%的准确率。更重要的是,使用Webscale-RL数据集进行RL训练的效率更高,以少至100倍的tokens实现了持续预训练的性能。
🎯 应用场景
Webscale-RL流水线和数据集可以广泛应用于各种自然语言处理任务,例如问答系统、对话系统、文本摘要等。通过使用Webscale-RL数据集进行强化学习训练,可以提高模型的性能和泛化能力。该研究为构建更强大、更高效的语言模型提供了一种新的途径,并有望推动人工智能技术的进一步发展。
📄 摘要(原文)
Large Language Models (LLMs) have achieved remarkable success through imitation learning on vast text corpora, but this paradigm creates a training-generation gap and limits robust reasoning. Reinforcement learning (RL) offers a more data-efficient solution capable of bridging this gap, yet its application has been constrained by a critical data bottleneck: existing RL datasets are orders of magnitude smaller and less diverse than web-scale pre-training corpora. To address this, we introduce the Webscale-RL pipeline, a scalable data engine that systematically converts large-scale pre-training documents into millions of diverse, verifiable question-answer pairs for RL. Using this pipeline, we construct the Webscale-RL dataset, containing 1.2 million examples across more than 9 domains. Our experiments show that the model trained on this dataset significantly outperforms continual pretraining and strong data refinement baselines across a suite of benchmarks. Notably, RL training with our dataset proves substantially more efficient, achieving the performance of continual pre-training with up to 100$\times$ fewer tokens. Our work presents a viable path toward scaling RL to pre-training levels, enabling more capable and efficient language models.