Controllable Stylistic Text Generation with Train-Time Attribute-Regularized Diffusion
作者: Fan Zhou, Chang Tian, Tim Van de Cruys
分类: cs.CL
发布日期: 2025-10-07
备注: Preprint under review
💡 一句话要点
提出RegDiff:一种训练时属性正则化的扩散模型,用于可控风格文本生成。
🎯 匹配领域: 支柱四:生成式动作 (Generative Motion)
关键词: 可控文本生成 风格迁移 扩散模型 属性正则化 VAE 文本生成
📋 核心要点
- 现有可控文本生成方法,如CFG和CG,在属性控制和计算效率之间存在权衡,难以兼顾。
- RegDiff提出一种训练时属性正则化的扩散框架,仅在训练阶段注入属性信息,无需采样时的分类器。
- 实验结果表明,RegDiff在多个风格属性数据集上优于现有基线,验证了其有效性和高效性。
📝 摘要(中文)
本文提出了一种名为RegDiff的正则化扩散框架,用于实现具有特定属性的可控风格文本生成。现有的方法主要分为无分类器引导(CFG)和分类器引导(CG)两类。CFG能有效保持语义内容,但在属性控制方面表现不佳。CG通过分类器梯度修改去噪轨迹,虽然能更好地对齐属性,但采样时计算成本高昂,且存在分类器泛化问题。RegDiff仅在训练时注入属性信息,利用基于VAE的编码器-解码器架构确保重建保真度,并使用属性监督训练潜在扩散模型以实现可控文本生成,从而在采样时无需预训练的分类器,降低了计算成本。在五个数据集上的实验表明,RegDiff在生成风格文本方面优于强大的基线模型,验证了其作为属性可控文本扩散高效解决方案的有效性。代码、数据集和资源将在发布后公开。
🔬 方法详解
问题定义:论文旨在解决可控风格文本生成问题,即生成具有特定属性的文本。现有方法,如无分类器引导(CFG)和分类器引导(CG),存在局限性。CFG虽然能保持语义,但属性控制能力弱;CG虽然属性控制好,但采样计算成本高,且依赖分类器的泛化能力。
核心思路:RegDiff的核心思路是在训练阶段将属性信息融入扩散模型,而在推理阶段无需依赖外部分类器。通过在训练时对扩散模型进行属性正则化,使得模型能够学习到属性与文本之间的映射关系,从而在生成时能够根据指定的属性生成相应的文本。
技术框架:RegDiff采用VAE-based的编码器-解码器架构,以及一个潜在扩散模型。编码器将输入文本编码到潜在空间,解码器用于从潜在空间重建文本。潜在扩散模型在潜在空间中进行扩散和逆扩散过程,并使用属性信息进行条件控制。整体流程包括:1) 使用VAE进行文本重建训练;2) 使用属性监督训练潜在扩散模型;3) 在推理阶段,通过控制扩散模型的属性条件,生成具有特定属性的文本。
关键创新:RegDiff的关键创新在于提出了一种训练时属性正则化的扩散框架,避免了采样时对分类器的依赖,从而降低了计算成本,并解决了分类器泛化问题。与传统的CFG和CG方法相比,RegDiff在属性控制和计算效率之间取得了更好的平衡。
关键设计:RegDiff的关键设计包括:1) 使用VAE进行文本重建,保证生成文本的质量;2) 在扩散模型中使用属性信息作为条件,实现属性控制;3) 设计合适的损失函数,包括重建损失和属性分类损失,以优化模型。
🖼️ 关键图片

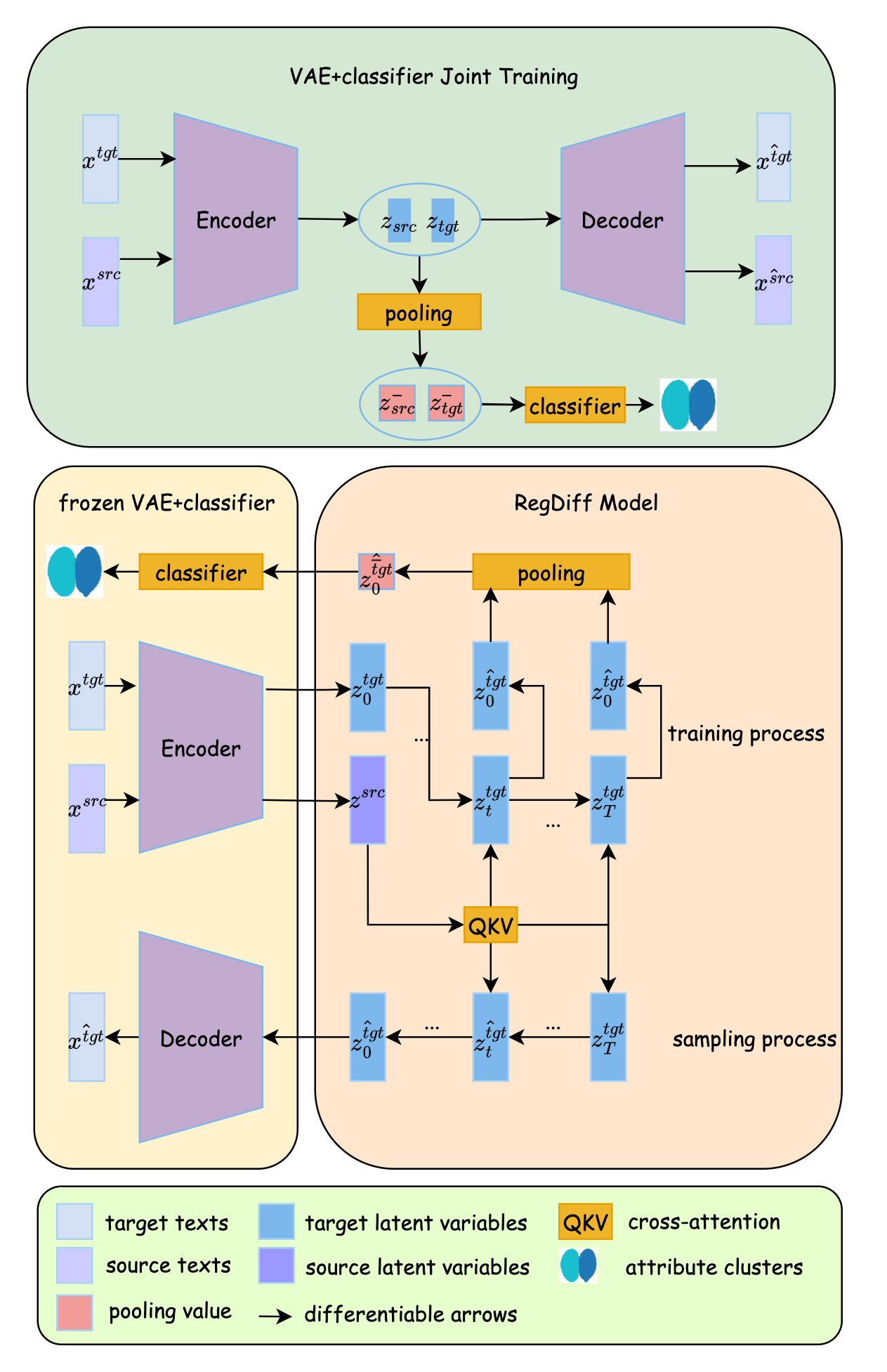
📊 实验亮点
RegDiff在五个数据集上进行了实验,涵盖了多个风格属性。实验结果表明,RegDiff在生成风格文本方面优于现有的强基线模型。具体性能数据和提升幅度将在论文发布后公开。该结果验证了RegDiff作为属性可控文本扩散高效解决方案的有效性。
🎯 应用场景
RegDiff可应用于多种场景,例如:文本风格迁移(将文本从一种风格转换为另一种风格)、情感控制(生成具有特定情感色彩的文本)、以及个性化文本生成(根据用户指定的属性生成文本)。该研究成果有助于提升人机交互的自然性和可控性,并可应用于内容创作、智能客服等领域。
📄 摘要(原文)
Generating stylistic text with specific attributes is a key problem in controllable text generation. Recently, diffusion models have emerged as a powerful paradigm for both visual and textual generation. Existing approaches can be broadly categorized into classifier-free guidance (CFG) and classifier guidance (CG) methods. While CFG effectively preserves semantic content, it often fails to provide effective attribute control. In contrast, CG modifies the denoising trajectory using classifier gradients, enabling better attribute alignment but incurring high computational costs during sampling and suffering from classifier generalization issues. In this work, we propose RegDiff, a regularized diffusion framework that leverages attribute features without requiring a pretrained classifier during sampling, thereby achieving controllable generation with reduced computational costs. Specifically, RegDiff employs a VAE-based encoder--decoder architecture to ensure reconstruction fidelity and a latent diffusion model trained with attribute supervision to enable controllable text generation. Attribute information is injected only during training. Experiments on five datasets spanning multiple stylistic attributes demonstrate that RegDiff outperforms strong baselines in generating stylistic texts. These results validate the effectiveness of RegDiff as an efficient solution for attribute-controllable text diffusion. Our code, datasets, and resources will be released upon publication at https://github.com/xxxx.