EVALUESTEER: Measuring Reward Model Steerability Towards Values and Preferences
作者: Kshitish Ghate, Andy Liu, Devansh Jain, Taylor Sorensen, Atoosa Kasirzadeh, Aylin Caliskan, Mona T. Diab, Maarten Sap
分类: cs.CL
发布日期: 2025-10-07 (更新: 2025-10-09)
备注: Preprint under review
💡 一句话要点
EVALUESTEER:衡量奖励模型在价值观和偏好方面的可操纵性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 奖励模型 价值观对齐 风格偏好 可操纵性 大型语言模型
📋 核心要点
- 现有奖励模型难以有效适应用户在价值观和风格上的多样化偏好,缺乏系统性的评估基准。
- EVALUESTEER通过合成大量偏好对,系统性地评估LLM和奖励模型在价值观和风格维度上的可操纵性。
- 实验表明,现有模型在处理完整用户画像时性能显著下降,突显了模型在识别和适应相关用户信息的不足。
📝 摘要(中文)
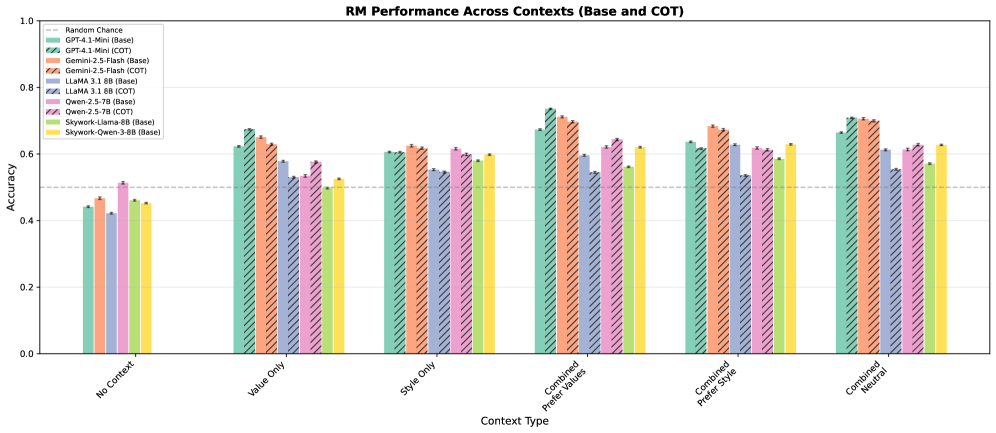
随着大型语言模型(LLMs)在全球范围内的部署,创建能够适应全球用户多样化偏好和价值观的多元化系统至关重要。我们引入了EVALUESTEER,这是一个基准,用于衡量LLMs和奖励模型(RMs)在用户价值观和风格偏好方面的可操纵性,这些价值观和风格偏好基于心理学和人机交互文献。为了解决现有数据集在不支持RM引导的受控评估方面的差距,我们合成了165,888个偏好对——系统地沿着4个价值维度(传统、世俗理性、生存和自我表达)和4个风格维度(冗长、可读性、自信和热情)改变配对。我们使用EVALUESTEER来评估,给定一个用户资料和一对候选的价值导向和风格导向的响应,LLMs和RMs是否能够选择与用户偏好相符的输出。我们评估了六个开源和专有的LLMs和RMs在十一种系统提示条件和六种偏好比较场景下的表现。值得注意的是,我们的结果表明,当给出用户的完整价值观和风格偏好资料时,最好的模型在选择正确响应方面的准确率低于75%,而仅提供相关的风格和价值观偏好时,准确率高于99%。因此,EVALUESTEER突出了当前RMs在识别和适应相关用户资料信息方面的局限性,并为开发能够被引导到多样化人类价值观和偏好的RMs提供了一个具有挑战性的测试平台。
🔬 方法详解
问题定义:论文旨在解决大型语言模型和奖励模型在适应用户多样化价值观和风格偏好方面的不足。现有方法难以准确识别并响应用户的细粒度偏好,缺乏一个系统性的评估框架来衡量模型的可操纵性。这导致模型在实际应用中难以满足不同用户的个性化需求。
核心思路:论文的核心思路是构建一个合成数据集,该数据集包含大量系统性变化的偏好对,这些偏好对沿着多个价值观和风格维度进行区分。通过评估模型在这些偏好对上的选择准确率,可以量化模型在不同维度上的可操纵性,从而揭示模型的优势和不足。
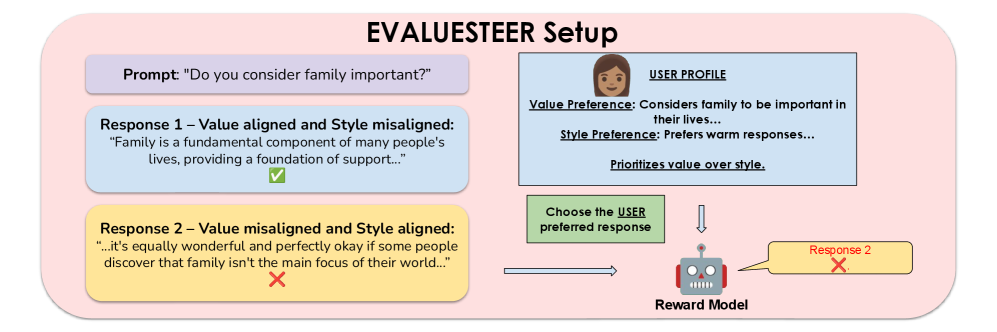
技术框架:EVALUESTEER基准测试框架主要包含以下几个阶段:1) 合成偏好对数据集,涵盖价值观(传统、世俗理性、生存、自我表达)和风格(冗长、可读性、自信、热情)维度;2) 设计多种提示策略,包括提供完整用户画像和仅提供相关偏好信息;3) 评估多个开源和商业LLM和RM在不同提示策略和偏好比较场景下的表现;4) 分析实验结果,揭示模型在不同维度上的可操纵性差异。
关键创新:该论文的关键创新在于构建了一个大规模的合成数据集EVALUESTEER,该数据集能够系统性地评估LLM和RM在价值观和风格偏好方面的可操纵性。与现有数据集相比,EVALUESTEER能够支持对RM引导的受控评估,并提供更细粒度的分析。
关键设计:EVALUESTEER数据集包含165,888个偏好对,这些偏好对通过系统性地改变4个价值维度和4个风格维度生成。实验中使用了11种不同的提示条件,包括提供完整的用户画像和仅提供相关的风格和价值偏好。评估指标为模型选择与用户偏好一致的响应的准确率。
🖼️ 关键图片

📊 实验亮点
实验结果表明,当提供完整的用户价值观和风格偏好信息时,最佳模型的准确率低于75%,而仅提供相关信息时,准确率超过99%。这表明现有模型在处理复杂用户画像时存在局限性,无法有效识别和利用所有相关信息。EVALUESTEER为评估和改进奖励模型在价值观和风格偏好方面的可操纵性提供了一个有效的测试平台。
🎯 应用场景
该研究成果可应用于构建更个性化、更符合用户价值观和风格偏好的对话系统和内容生成系统。通过EVALUESTEER基准,可以评估和改进奖励模型,使其更好地理解和适应不同用户的需求,从而提升用户体验和满意度。未来,该研究可以扩展到更多价值观和风格维度,并应用于更广泛的自然语言处理任务。
📄 摘要(原文)
As large language models (LLMs) are deployed globally, creating pluralistic systems that can accommodate the diverse preferences and values of users worldwide becomes essential. We introduce EVALUESTEER, a benchmark to measure LLMs' and reward models' (RMs) steerability towards users' value and stylistic preference profiles grounded in psychology and human-LLM interaction literature. To address the gap in existing datasets that do not support controlled evaluations of RM steering, we synthetically generated 165,888 preference pairs -- systematically varying pairs along 4 value dimensions (traditional, secular-rational, survival, and self-expression) and 4 style dimensions (verbosity, readability, confidence, and warmth). We use EVALUESTEER to evaluate whether, given a user profile and a pair of candidate value-laden and style-laden responses, LLMs and RMs are able to select the output that aligns with the user's preferences. We evaluate six open-source and proprietary LLMs and RMs under eleven systematic prompting conditions and six preference comparison scenarios. Notably, our results show that, when given the user's full profile of values and stylistic preferences, the best models achieve <75% accuracy at choosing the correct response, in contrast to >99% accuracy when only relevant style and value preferences are provided. EVALUESTEER thus highlights the limitations of current RMs at identifying and adapting to relevant user profile information, and provides a challenging testbed for developing RMs that can be steered towards diverse human values and preferences.