RECODE-H: A Benchmark for Research Code Development with Interactive Human Feedback
作者: Chunyu Miao, Henry Peng Zou, Yangning Li, Yankai Chen, Yibo Wang, Fangxin Wang, Yifan Li, Wooseong Yang, Bowei He, Xinni Zhang, Dianzhi Yu, Hanchen Yang, Hoang H Nguyen, Yue Zhou, Jie Yang, Jizhou Guo, Wenzhe Fan, Chin-Yuan Yeh, Panpan Meng, Liancheng Fang, Jinhu Qi, Wei-Chieh Huang, Zhengyao Gu, Yuwei Han, Langzhou He, Yuyao Yang, Yinghui Li, Hai-Tao Zheng, Xue Liu, Irwin King, Philip S. Yu
分类: cs.CL, cs.AI
发布日期: 2025-10-07 (更新: 2025-10-24)
备注: Code and dataset are available at github.com/ChunyuMiao98/RECODE
💡 一句话要点
RECODE-H:一个通过人机交互反馈改进科研代码生成的基准。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 科研代码生成 人机交互 反馈驱动 大型语言模型 基准测试 迭代开发 代码调试 ReCodeAgent
📋 核心要点
- 现有LLM在科研代码生成中能力有限,缺乏对迭代和反馈驱动的真实工作流程的考虑。
- 提出RECODE-H基准,通过模拟人机交互,利用多轮反馈迭代改进LLM的代码生成能力。
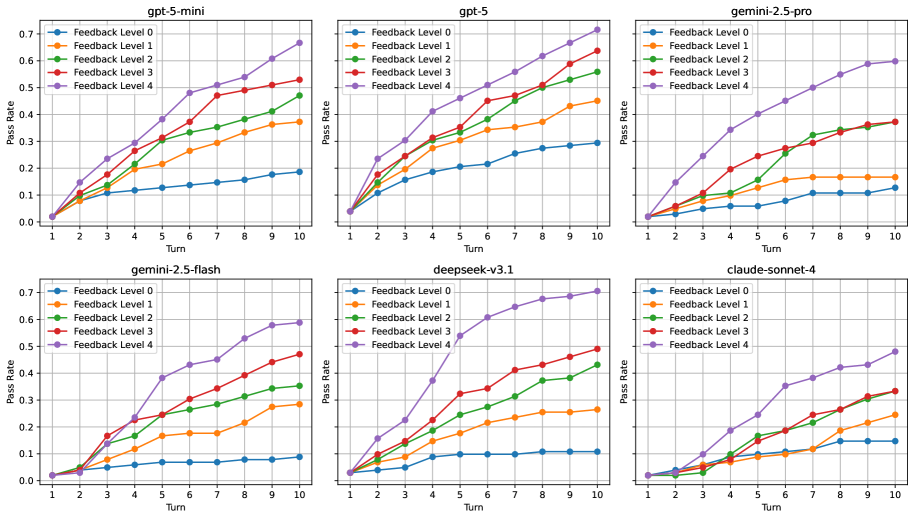
- 实验表明,更丰富的反馈能显著提升LLM在复杂科研代码生成中的性能,但仍存在挑战。
📝 摘要(中文)
大型语言模型(LLMs)在支持科学研究实现方面展现出潜力,但生成正确且可执行代码的能力仍然有限。现有工作主要采用单次设置,忽略了科学研究开发中真实的迭代和反馈驱动的工作流程。为了解决这一差距,我们提出了RECODE-H,这是一个包含来自研究论文和存储库的102个任务的基准,通过与LLM模拟的人类反馈进行多轮交互来评估LLM智能体。它包括结构化指令、单元测试和一个五级反馈层次结构,以反映真实的科研人员-智能体协作。我们进一步提出了ReCodeAgent,一个将反馈集成到迭代代码生成中的框架。使用包括GPT-5、Claude-Sonnet-4、DeepSeek-V3.1和Gemini 2.5在内的领先LLM进行的实验表明,更丰富的反馈可以带来显著的性能提升,同时也突出了生成复杂科研代码方面持续存在的挑战。RECODE-H为开发科学研究实现中自适应的、反馈驱动的LLM智能体奠定了基础。
🔬 方法详解
问题定义:现有的大型语言模型在生成科研代码时,往往难以保证代码的正确性和可执行性。现有的评估方法通常采用单次生成的方式,忽略了科研代码开发过程中迭代和反馈的重要性。这导致LLM难以适应真实科研场景中不断调整和完善代码的需求。
核心思路:RECODE-H的核心思路是通过构建一个模拟真实科研人员反馈的交互环境,让LLM智能体在多轮迭代中不断学习和改进代码。这种反馈驱动的迭代过程能够帮助LLM更好地理解科研任务的需求,并生成更可靠的代码。
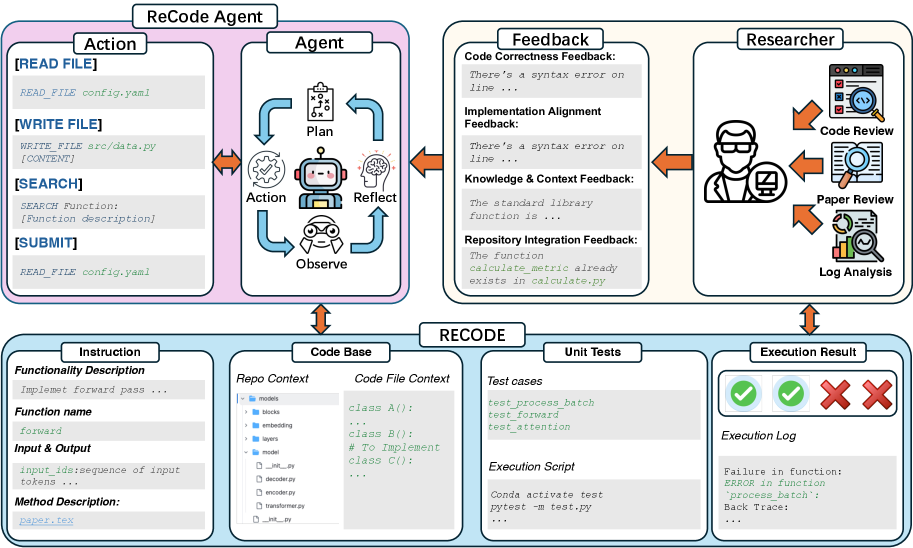
技术框架:RECODE-H包含以下几个主要组成部分:1) 来自研究论文和代码仓库的102个科研任务;2) 结构化的任务指令和单元测试;3) 一个五级反馈层次结构,模拟不同程度的人工反馈;4) ReCodeAgent框架,用于集成反馈信息并进行迭代代码生成。LLM智能体首先根据任务指令生成代码,然后接收模拟人类的反馈,根据反馈调整代码,并重复这个过程直到满足要求。
关键创新:RECODE-H的关键创新在于构建了一个更贴近真实科研场景的评估环境,强调了反馈在代码生成过程中的重要性。通过多轮交互和分层反馈,RECODE-H能够更全面地评估LLM在科研代码生成方面的能力,并促进相关技术的发展。ReCodeAgent框架则提供了一种将反馈信息有效集成到代码生成过程中的方法。
关键设计:RECODE-H的五级反馈层次结构包括:1) 无反馈;2) 通过/失败的单元测试结果;3) 错误类型信息;4) 错误位置信息;5) 详细的错误描述和修改建议。ReCodeAgent框架使用这些反馈信息来调整LLM的代码生成策略,例如,通过强化学习或微调来提高代码的正确性和可执行性。具体的参数设置和网络结构取决于所使用的LLM和反馈集成方法。
🖼️ 关键图片

📊 实验亮点
实验结果表明,使用更丰富的反馈信息能够显著提升LLM在RECODE-H基准上的性能。例如,GPT-5、Claude-Sonnet-4、DeepSeek-V3.1和Gemini 2.5等领先LLM在接收到详细的错误描述和修改建议后,代码生成成功率得到了显著提升。这验证了反馈驱动的迭代方法在科研代码生成中的有效性。
🎯 应用场景
RECODE-H的研究成果可以应用于自动化科研代码生成、智能编程助手、以及科研人员与AI协同开发等领域。通过提供更智能的代码生成和调试工具,可以显著提高科研效率,加速科学发现的进程。未来,该研究有望推动AI在科学研究领域的更广泛应用。
📄 摘要(原文)
Large language models (LLMs) show the promise in supporting scientific research implementation, yet their ability to generate correct and executable code remains limited. Existing works largely adopt one-shot settings, ignoring the iterative and feedback-driven nature of realistic workflows of scientific research development. To address this gap, we present RECODE-H, a benchmark of 102 tasks from research papers and repositories that evaluates LLM agents through multi-turn interactions with LLM-simulated human feedback. It includes structured instructions,unit tests, and a five-level feedback hierarchy to reflect realistic researcher-agent collaboration. We further present ReCodeAgent, a framework that integrates feedback into iterative code generation. Experiments with leading LLMs, including GPT-5, Claude-Sonnet-4, DeepSeek-V3.1, and Gemini 2.5, show substantial performance gains with richer feedback, while also highlighting ongoing challenges in the generation of complex research code. RECODE-H establishes a foundation for developing adaptive, feedback-driven LLM agents in scientific research implementation