VecInfer: Efficient LLM Inference with Low-Bit KV Cache via Outlier-Suppressed Vector Quantization
作者: Dingyu Yao, Chenxu Yang, Zhengyang Tong, Zheng Lin, Wei Liu, Jian Luan, Weiping Wang
分类: cs.CL
发布日期: 2025-10-07
💡 一句话要点
VecInfer:通过抑制异常值的向量量化实现低比特KV缓存的高效LLM推理
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 KV缓存 向量量化 低比特量化 异常值抑制
📋 核心要点
- 现有LLM推理中KV缓存占用大量内存,低比特量化虽能压缩KV缓存,但异常值导致性能显著下降。
- VecInfer通过平滑和Hadamard变换抑制KV缓存中的异常值,使码本更好地覆盖数据分布,降低量化难度。
- VecInfer设计了优化的CUDA内核,融合计算与反量化,减少内存访问,显著提升了推理速度和效率。
📝 摘要(中文)
大型语言模型(LLM)推理过程中,Key-Value(KV)缓存会带来巨大的内存开销。现有的向量量化(VQ)方法虽然可以降低KV缓存的使用量,并在不同比特宽度上提供灵活的表示能力,但由于关键缓存中的异常值阻碍了有效的码本利用,导致在超低比特宽度下性能严重下降。为了解决这一挑战,我们提出了一种新的VQ方法VecInfer,用于积极地压缩KV缓存,同时实现高效推理。通过应用平滑和Hadamard变换,VecInfer抑制了关键缓存中的异常值,使码本能够全面覆盖原始数据分布,从而降低了量化难度。为了方便高效部署,我们设计了一个优化的CUDA内核,将计算与反量化融合,以最大限度地减少内存访问开销。广泛的评估表明,VecInfer在长上下文理解和数学推理任务中始终优于现有的量化基线。在仅使用2比特量化的情况下,VecInfer实现了与全精度相当的性能,同时在Llama-3.1-8B上,序列长度为196k时,大批量自注意力计算速度提高了高达$\mathbf{2.7\times}$,单批量端到端延迟降低了$\mathbf{8.3\times}$。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)推理过程中,KV缓存带来的巨大内存开销问题。现有的向量量化(VQ)方法在超低比特宽度下,由于KV缓存中存在的异常值,导致码本无法有效覆盖原始数据分布,从而引起严重的性能下降。因此,如何在超低比特量化下,有效抑制异常值,提升LLM推理性能,是本文要解决的核心问题。
核心思路:VecInfer的核心思路是通过预处理来抑制KV缓存中的异常值,从而降低量化的难度。具体来说,VecInfer采用了平滑变换和Hadamard变换,对KV缓存进行预处理,使得原始数据分布更加平滑,异常值得到有效抑制。这样,码本就能更好地覆盖原始数据分布,从而在低比特量化下也能保持较高的精度。
技术框架:VecInfer的技术框架主要包括三个阶段:1) 预处理阶段:使用平滑变换和Hadamard变换抑制KV缓存中的异常值;2) 量化阶段:使用向量量化方法对预处理后的KV缓存进行量化;3) 推理阶段:使用优化的CUDA内核,融合计算与反量化,加速推理过程。整个框架旨在通过抑制异常值和优化计算流程,实现低比特KV缓存的高效LLM推理。
关键创新:VecInfer的关键创新在于提出了异常值抑制的向量量化方法。与现有的VQ方法不同,VecInfer首先对KV缓存进行预处理,抑制异常值,然后再进行量化。这种方法能够有效解决现有VQ方法在超低比特宽度下性能下降的问题。此外,VecInfer还设计了优化的CUDA内核,进一步提升了推理效率。
关键设计:VecInfer的关键设计包括:1) 平滑变换和Hadamard变换的具体实现方式,用于抑制KV缓存中的异常值;2) 向量量化的码本大小和比特宽度选择,需要在精度和效率之间进行权衡;3) CUDA内核的优化策略,例如融合计算与反量化,减少内存访问等。这些设计细节共同保证了VecInfer在低比特量化下也能实现高效的LLM推理。
🖼️ 关键图片
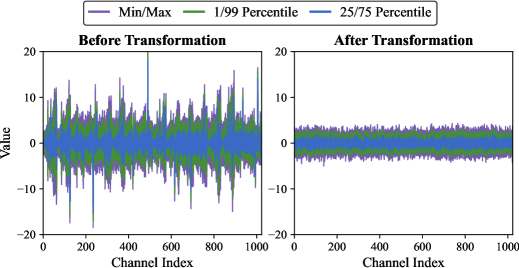
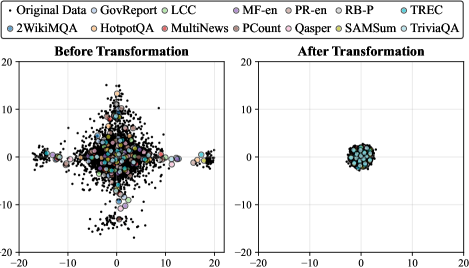

📊 实验亮点
实验结果表明,VecInfer在长上下文理解和数学推理任务中均优于现有量化基线。在Llama-3.1-8B模型上,序列长度为196k时,使用2比特量化,VecInfer实现了与全精度相当的性能,同时大批量自注意力计算速度提高了高达$\mathbf{2.7\times}$,单批量端到端延迟降低了$\mathbf{8.3\times}$。这些数据充分证明了VecInfer在低比特KV缓存压缩和高效LLM推理方面的优势。
🎯 应用场景
VecInfer在资源受限的设备上部署大型语言模型具有广泛的应用前景,例如移动设备、边缘计算设备等。通过降低KV缓存的内存占用,VecInfer使得这些设备也能运行更大规模的LLM,从而提升用户体验。此外,VecInfer还可以应用于对延迟敏感的应用场景,例如实时对话系统、在线翻译等,通过加速推理过程,提高系统的响应速度。
📄 摘要(原文)
The Key-Value (KV) cache introduces substantial memory overhead during large language model (LLM) inference. Although existing vector quantization (VQ) methods reduce KV cache usage and provide flexible representational capacity across bit-widths, they suffer severe performance degradation at ultra-low bit-widths due to key cache outliers that hinder effective codebook utilization. To address this challenge, we propose VecInfer, a novel VQ method for aggressive KV cache compression while enabling efficient inference. By applying smooth and Hadamard transformations, VecInfer suppresses outliers in the key cache, enabling the codebook to comprehensively cover the original data distribution and thereby reducing quantization difficulty. To facilitate efficient deployment, we design an optimized CUDA kernel that fuses computation with dequantization to minimize memory access overhead. Extensive evaluations demonstrate that VecInfer consistently outperforms existing quantization baselines across both long-context understanding and mathematical reasoning tasks. With only 2-bit quantization, VecInfer achieves performance comparable to full precision, while delivering up to $\mathbf{2.7\times}$ speedup in large-batch self-attention computation and $\mathbf{8.3\times}$ reduction in single-batch end-to-end latency on Llama-3.1-8B with a 196k sequence length.